こんにちはKyotaです!
暖冬に甘えて防寒対策をしていなかったら、急に冬らしくなり風邪を引きかけているこの頃。
皆様いかがお過ごしでしょうか。
今回はtruestarアドベントカレンダー企画、本日は22日目。
Snowflakeのパフォーマンスチューニングに役立つクラスタリングについて図解していきたいと思います。
【予備知識】マイクロパーティション
クラスタリングの話に入る前に、Snowflakeマイクロパーティションの仕組みを理解する必要があります。
マイクロパーティションとは文字通り、小さな区画という意味です。
Snowflakeは大規模なデータを保存する際は圧縮して小分けにし、各ストレージに分割保存します。
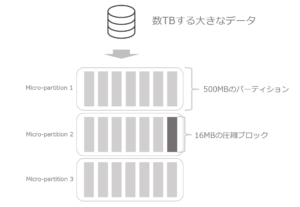
データを圧縮することで、処理がしやすくなることは容易に想像できるかと思います。
一方で、欲しいデータを検索する場合、小分けにしただけでは何処にデータが存在するのか分かりません。
そこで、Snowflakeはデータの所在を明確にするため大量データをパーティション化する際に
マイクロパーティションに関するメタデータを保存します。
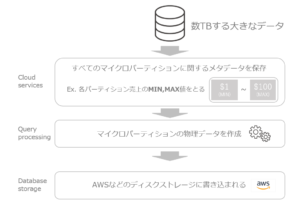
メタデータを保持すればデータの所在地の目安がつき、効率的にデータを呼び出すことができます。
例えば、「売上$250のデータをみたい」と指示すれば、全データを探さずにMIN/MAX情報だけで
適切なパーティションから該当データのあたりをつけることができます。
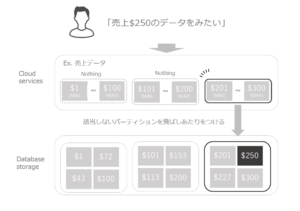
このように、メタデータから該当データのあるパーティションだけを絞り込み
他のパーティションを無視する仕組みをプルーニング(剪定)と言います。
まとめると、Snowflakeはマイクロパーティションに分け、メタデータを保持することで
必要なデータへ効率的かつ高速にアクセスすることが可能になります。
また、一連の流れには特に設定は必要とせず、Snowflakeが自動的に行ってくれます。
マイクロパーティションは常に最適な形なのか?
自動で設定されるマイクロパーティションは
例で示したようにデータが重複しない形で存在するわけではありません。
実際は各マイクロパーティション間でデータが被ります。
そのため、例のようにピンポイントであたりをつけられず
該当データが存在しないマイクロパーティションを経由する必要があります。
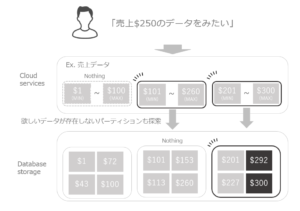
欲しいデータが存在しないマイクロパーティションを無視できないのは、コスト面で非効率だといえます。
なるべくマイクロパーティションの読み込みを減らしたい。
そんなときに、役立つのがクラスタリングです。
クラスタリングの仕組み
クラスタリングとは、特定のルールに基づいてデータセットを分類することを指します。
データセットとは、正にマイクロパーティションのことであり
クラスタリングはマイクロパーティションを適切な形に再編成する機能になります。
Clustering Depth
Snowflakeでは重複する値を含むマイクロパーティションの数を
Clustering Depth(クラスターの深さ)で表現します。
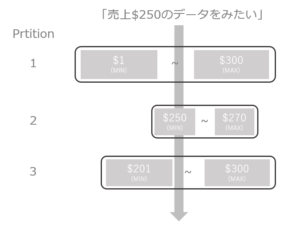
例:不十分なクラスタリング(深度3)
例:適切なクラスタリング(深度1)
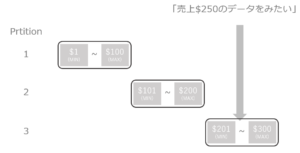
図のようにClustering Depthの数が小さければ、読み込むマイクロパーティションの数も少なくなります。
Clustering Depth情報の取得
では、実際にSnowflakeのsampleデータを使用してClustering Depth情報を取得してみましょう。
//情報を取得
select system$clustering_information('ORDERS','(o_totalprice)');
//結果
{
"cluster_by_keys" : "LINEAR(o_totalprice)",
"notes" : "Clustering key columns contain high cardinality key O_TOTALPRICE which might result in expensive re-clustering. Consider reducing the cardinality of clustering keys. Please refer to https://docs.snowflake.net/manuals/user-guide/tables-clustering-keys.html for more information.",
"total_partition_count" : 3242,
"total_constant_partition_count" : 0,
"average_overlaps" : 3241.0,
"average_depth" : 3242.0,
"partition_depth_histogram" : {
"00000" : 0,
"00001" : 0,
"00002" : 0,
"00003" : 0,
"00004" : 0,
"00005" : 0,
"00006" : 0,
"00007" : 0,
"00008" : 0,
"00009" : 0,
"00010" : 0,
"00011" : 0,
"00012" : 0,
"00013" : 0,
"00014" : 0,
"00015" : 0,
"00016" : 0,
"04096" : 3242
},
"clustering_errors" : [ ]
}読み取るべき情報
total partition count: テーブルを構成する合計パーティション数
total constant partition count: クラスタリングをする必要がないマイクロパーティション数
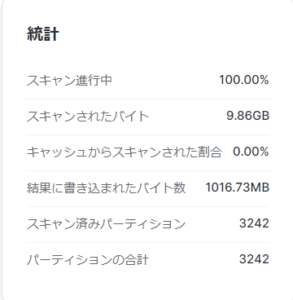
average depth: 平均深度、指定された値を読み取るためにマイクロパーティションの平均数今回の結果はtotal partition countとaverage depthが3242と数が一致しており
これは全パーティションを閲覧する必要があることを指しています。
実際にORDERSテーブルのo_totalpriceでフィルタをかけると、スキャン進行中が100%となっています。
これは全パーティションを読み込んでいることを表します。
クラスタリングをする基準
パーティションが最適な形ではないからといって、クラスタリングが必要というわけではありません。
先ほどの結果をみると、ORDERSテーブルのo_totalpriceはカーディナリティが高いため
クラスタリングするとコストが高くつくという注意喚起がされました。
"notes" : "Clustering key columns contain high cardinality key O_TOTALPRICE which might result in expensive re-clustering. Consider reducing the cardinality of clustering keys.再クラスタリングには仮想ウェアハウス外のコンピューティングリソースを使用するため費用が掛かります。
そのため、クラスタリングを検討する際は、クラスタリングに掛かる費用とクラスタリングで浮くコストを勘案する必要があります。
一般的にクラスタリングすべきデータセット
クラスタリングすべきデータセットの特徴は以下になります
・大規模なテーブル:テーブル内に1,000以上のマイクロパーティションがあるものが望ましい
・頻繁に使用されるクエリ:where句で絞り込みをかけるとき、頻繁に使用されるキー列
・更新がほとんどされないテーブル:DELETE, UPDATE操作はクラスタリングに影響するため、効率が良くない
・パフォーマンス改善につながるテーブル:クエリ時間、パーティション読み取り数減少など効果が表れるテーブル
以上を踏まえて、効果的なクラスタリングの設定をする必要があります。
最後に
少し長くなってしまいましたが以上でクラスタリング図解解説を終えます。
Snowflakeは大規模データセットを扱うのに長けているので
クラスタリングがパフォーマンスの一助になる機会は多いのかなと考えます。
この記事が理解の一助になれば幸いです。