
Dataiku体験日記第4弾です!
前回までいろいろデータ接続周りを試したので、今回はデータの加工の部分です。
TruestarグループではAlteryxをETLに使っている社員が多くて、私もAlteryxゴリゴリゴリゴリしてました。
Deepblue転籍後の今もクライアントにpythonで、など指定されていない場合はAlteryxでやっちゃいます。
そんなAlteryxユーザー目線でお届けしたいと思います。
インターフェースと機能
黄色いのがAlteryxにあるいろんなアイコンの代わりみたいなイメージです。
オレンジはコードをDataiku内に書いて実行できます。
赤っぽいのはプラグインなので後から追加するものです。
今回は黄色メインでお話しします。
Dataikuのプレパレーションを見てみよう
比較のためにAlteryxのweekly challengeをお題とします。
私が組んだフローがこちら↓
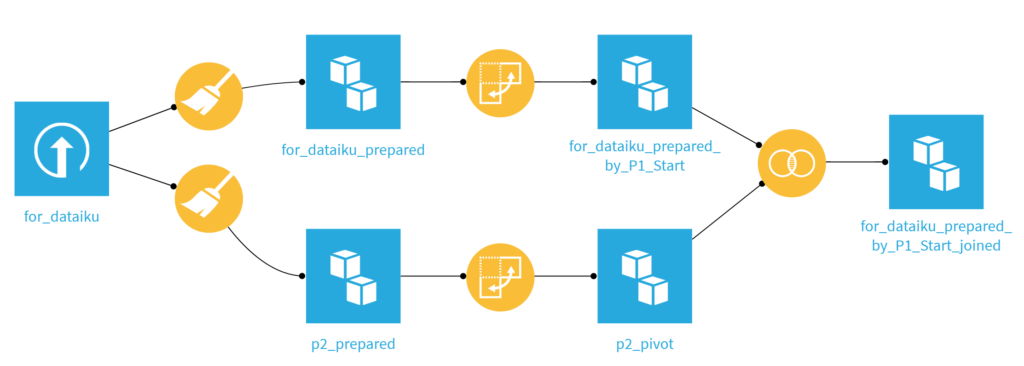
青い四角はデータベースなので、データ処理をしているアイコンは5つ。
Alteryxで自分で組むとしたら…でやってみましたがアイコンが15個くらいになってこっちの方が断然すっきりして見えます。
ほうきマーク(Prepare)にAlteryxの青系ツールがいろいろ詰まってます。
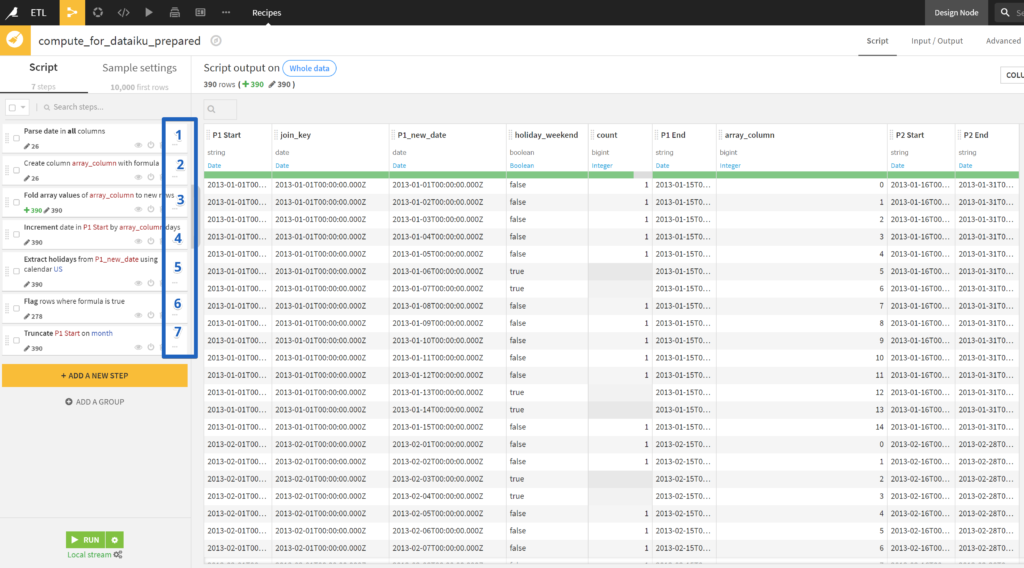
7つのステップが組み込まれてます。
内容としては以下の通りです。
- 日付のデータ型を修正
- P1 StartとP1 Endの日数の差をarrayで別の列に追加
- array列でfold(Alteryxで言うtransposeみたいな)
- foldした結果の数値とP1 Startを足す(datetimeaddみたいな)
- 4の日付が週末かどうかフラグを立てる
- 5の列がtrueなら1を代入
- 後でjoinするためのキーとして日付部分をtruncateする
Alteryxのアイコンがたくさん並んでごちゃごちゃするより断然すっきり!
しかも勝手に何やってるかのタイトルつけてくれるのもいいですね(変更もできます)
最初に作ったほうきアイコンをコピーして別の列の処理に使用したりもしました。(フローの下段)
Alteryx使ってる身としてよくわからないな、と思うのがtransposeはほうきでできるのに、ピボットは別アイコンということ(;’∀’)
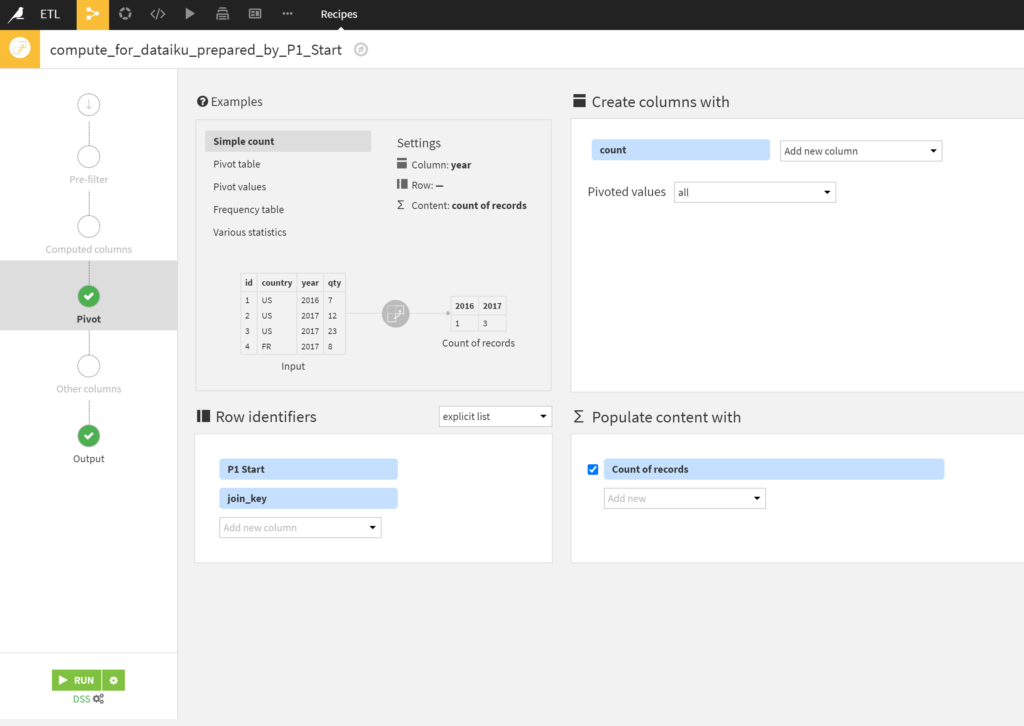
Populate content withのAdd newをするときにコード内容を書くともっと柔軟にいろいろできそうです。
SummarizeツールはAlteryxの方がわかりやすかった気がします。キー指定しないで全体の平均出す、みたいなSummarizeの使い方もDataikuは出来なさそう。
あとjoinもしてみました。
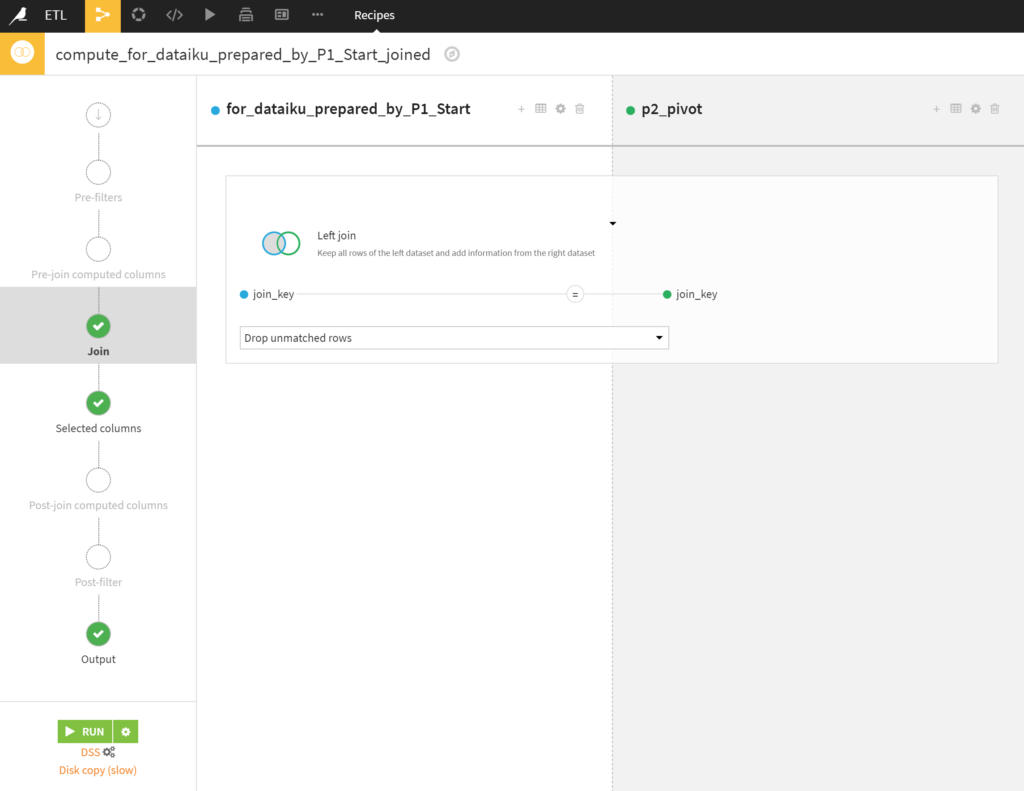

(あんまり良くないと思いつつも便利な)上から順番にキー指定しないでjoinする、というのができませんでした。
(ほうきに戻ってjoinキーを追加した)
2枚目の画像の画面でアウトプットする列を選択・解除できて、列名の変更もできました。
Dataikuのデータ加工の感想
Dataikuの良いところ
- ツールがごちゃごちゃしなくてすっきりする
- ツールを追加する際には必ずアウトプットのデータベースが作成されるのでどこまで遡って分岐するか、などの判断がしやすい
- データベースが都度都度作成されるので全部流しなおさなくてもいい(時間短縮)
- いろいろツールあるけど最終的に全部pythonコードで(書ける人にお願いして)処理してしまうのもアリ(Alteryxのpythonツールの挙動は怪しいことがある)
- 誰がいつどんな作業したかのログが残っていてロールバックもできる(gitだと思う)
- 機械学習などデータ加工後の拡張性が高い
Alteryxの方がいいと思ったところ
- 処理が早い(多分これは小さいデータで比べているから、というのはありそう。でもデータベースを都度都度作成していないので早い)
- 雑な処理(キーをちゃんと指定しないjoinやSummarize)ができる 本当はやらない方が良いとは思いつつ
- フローにテキストボックス置ける
- フローをずっと見ながら作業できる(Dataikuは毎回画面が切り替わるので全体の流れの中でのどういう処理か見失う)
- ローカルにアウトプットできる(Cloud版しか試していない、というのもあるかもしれません)
hyperなどいろいろな形式でアウトプットできるhyperはプラグインを追加したら出力できました(修正3/20)- 学習コストは恐らくこっちの方が少ない
Dataikuは分業体制で機械学習サイクルを構築するのに適していて、Alteryxはデータ加工の手間が簡単に減るし、雑なタスクもこなせるというのがメリットな気がしました。
データ加工よりも機械学習部分の方がDataikuの売りだと思うので、その部分も引き続き試していきたいと思います。




