Dataiku投稿第2弾!ひめのです。
前回はSnowflakeにDataikuから接続してみました。今回はRedshiftに挑戦します!
今回も個人的にはじわじわ苦戦したので私の屍を超えていってください。
Redshiftに接続しよう
今回もonline版でlaunch padを開きます。
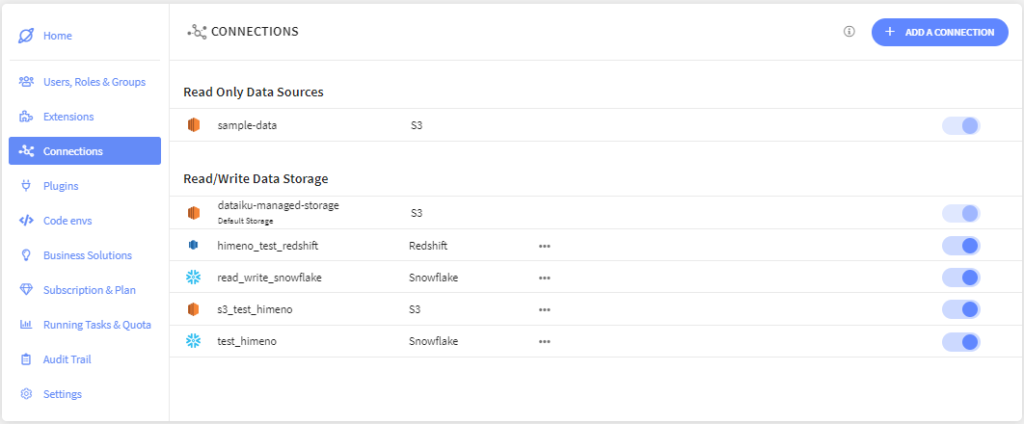
Connectionsを左側のタブから選び、「ADD A CONNECTION」ボタンを押します。
(ひめのが試行錯誤した形跡が見えますね。S3も接続できたのでこちらもブログにします。S3はすんなりいきました)
今回もRead/Writeにしました。Redshiftを一覧から選びます
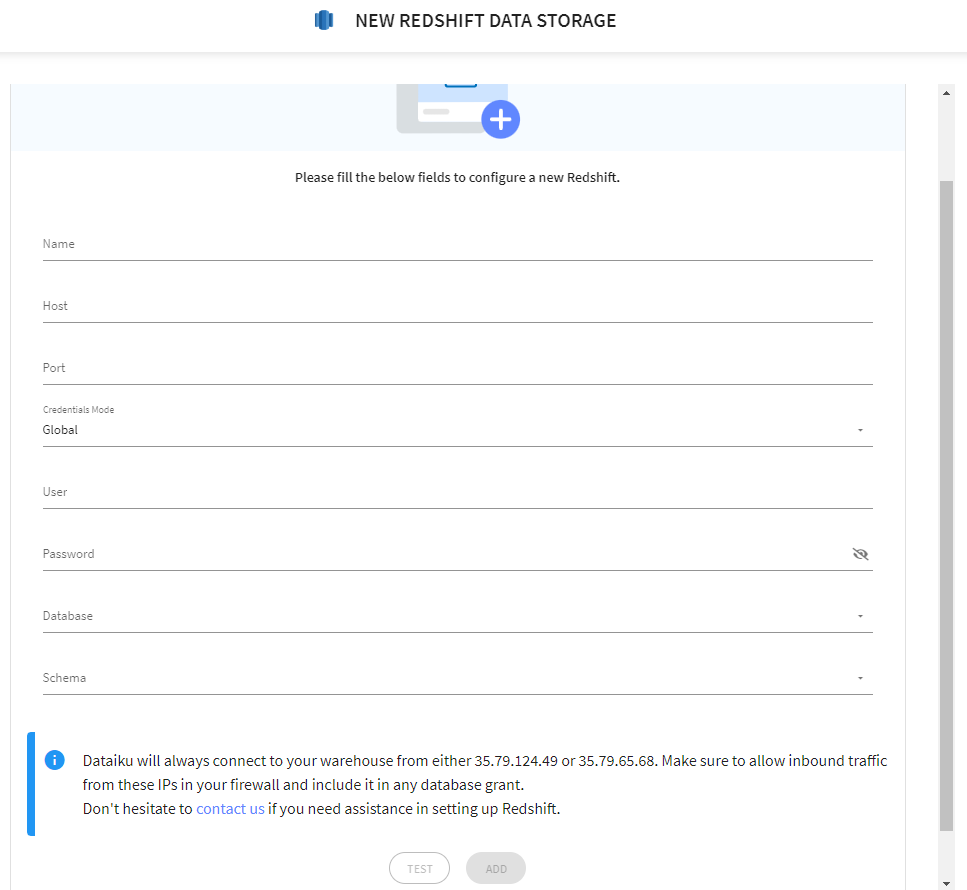
このフォームを入力していきます。まずはそのためのRedshift側の準備です。
Redshiftでデータベースを用意しよう
SnowflakeはPODBを使用しましたが、Redshiftは特にグループ内で共有している公開用テーブルが無いので作成しました。
Dataikuとの接続に関してはクラスター設定の部分(クラスター識別子、ノードの種類など)はあまり関係無さそうなので好きに設定します。
特に手元に良さげなデータが無かったので私は「サンプルデータをロード」に✓を入れました。
そしてこの「データベース設定」が私が引っかかったポイントだと振り返ってわかりました。
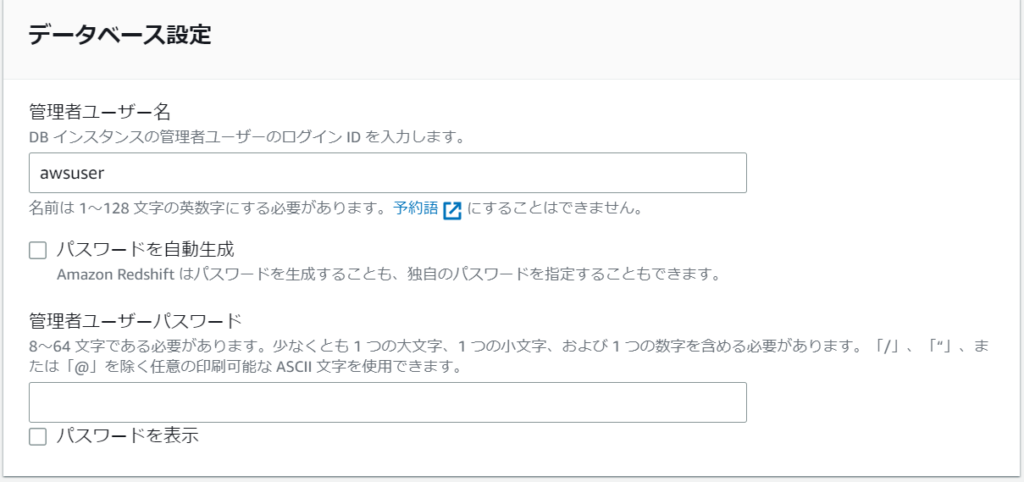
管理者ユーザー名と管理者ユーザーパスワードが接続に必要です。
クラスタ作成時にはよくわからずに(これが必要になると思っていなかった)「パスワードを自動生成」に✓を入れていました。
awsuserになっているところを変更してもOKです。私のようにパスワード自動生成をチェックした場合でも後から変更できます。
クラスターの許可も恐らくDataikuとの接続には不要なので飛ばします。
追加設定の「デフォルトを使用」をオフにします。
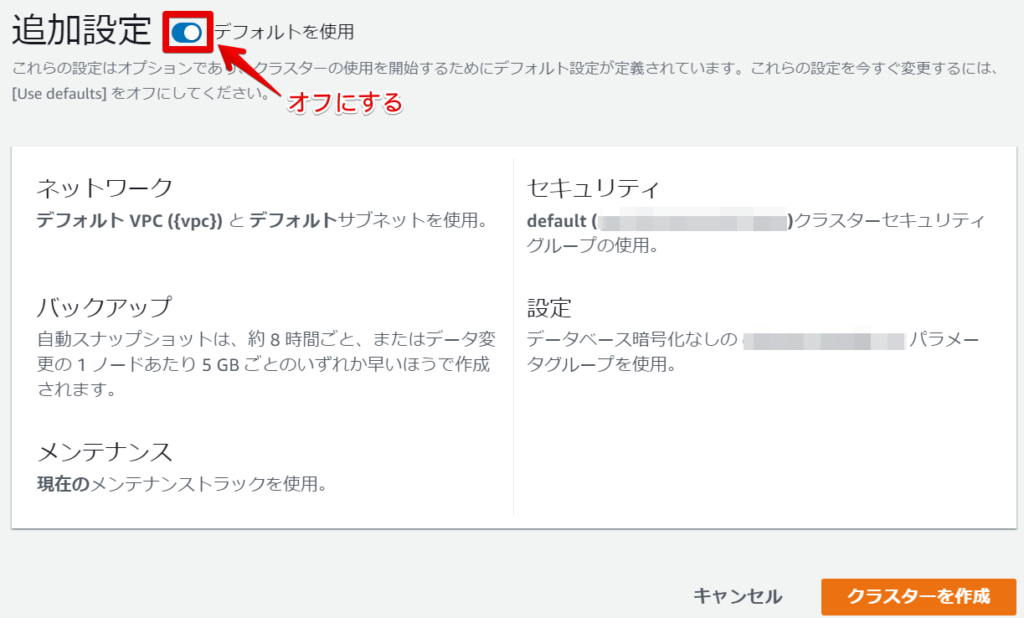
ネットワークとセキュリティの設定で、
デフォルトだとVPCはデフォルトVPCに設定されていますが、私は今回のテスト用にVPC、サブネットなどを作りなおしたのでそれを指定しました。
最後の「[パブリックにアクセス可能]をオンにする」に✓も入れます。
データベース名も必要に応じて変更するなどして、「クラスターを作成」ボタンを押して待ちます。
状態がAvailableになったらクラスター名をクリックし、「データベース」タブをクリックしてデータベースを確認します。
また、その下にあるスキーマも表示されるか確認します。サンプルデータのチェックを入れていれば何もデータを投入しなくても出てくるはずです。
Dataikuとの接続を設定しよう
先ほどのDataikuとの接続の設定画面に戻ります。
以下の内容を入力します。
- Host→クラスターの「一般的な情報」の「エンドポイント」の最初~redshift.amazonaws.comまでの部分(例:xxxxxxxxxxxxxxxxxxxxx.redshift.amazonaws.com)
- Port→Hostで入力した後の部分にある数字(デフォルトだと5439?)
- Credentials Mode→Globalのまま(ドキュメントによるとPer-userはサポートされていないとか。)
- User→クラスター作成時の管理者ユーザー名。プロパティタブからも確認できます。
- Password→クラスター作成時の管理者ユーザーパスワード。忘れた・自動作成してわからない場合はプロパティタブの[Edit admin credentials]から変更可能。
- Database→「データベース」タブをクリックし、データベース名を確認します。デフォルトから変更していない場合はdev。
- Schema→Database同様に確認します。デフォルトから変更していない場合はpublic。
[ADD]ボタンで追加できたように見える。が、そう甘くはなかったのでAWSの設定に戻ります。
AWSの権限周りの設定をしよう

指定されているIPアドレスからのアクセスを許可しないといけません。
クラスターが置かれているサブネットのVPCのネットワークACLのインバウンドルールとアウトバウンドルールを編集します。
また、VPCルートテーブルでインターネットゲートウェイの設定が必要です。
参考にしたのはこちらです。公式ドキュメントがやっぱり大事だと今回も痛感しました。
がばがばな設定なのでお見せできず、すみません。
フローから接続しよう
SnowflakeはConnection作成の時に弾かれていたのですが、Redshiftは接続はチェックがゆるいのか簡単にパスして、
フローから接続しようとしたらダメ、というケースが多かったです。
データのインポートのところで先ほど作成したConnectionを指定し、[LIST TABLES]をクリックします。
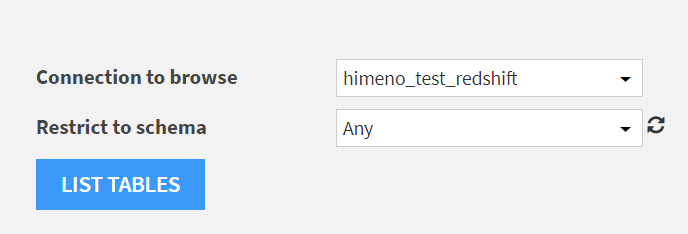
エラーが出るとしたらここです。パスワードが違う、アクセス権限を確認しろ、などいろいろ出ました。
絶対redshiftの設定の問題だとわかりつつもチャットサポートの方に聞いてみたら親切に教えてくださいました。
Redshiftへの書き込みもRead/Writeの設定でできることを確認できました。
同じConnectionでテーブル一覧を表示すると今はこんな感じになっています。2行目が書き込んだだけの新ファイルです。

まとめ
RedshiftはConnection画面がすんなり通ってしまうので簡単かと思いきや、Redshiftの権限周りで手こずりました。
Redshiftのどの情報をDataikuの画面に入力するのか、参考になれば幸いです。
次回はS3の予定です~