Dataiku投稿第3弾!ひめのです。
今回はS3です!前の2記事ほどは苦労しなかったのでさっくり接続していきましょう。
S3に接続しよう
今回もonline版でlaunch padを開きます。
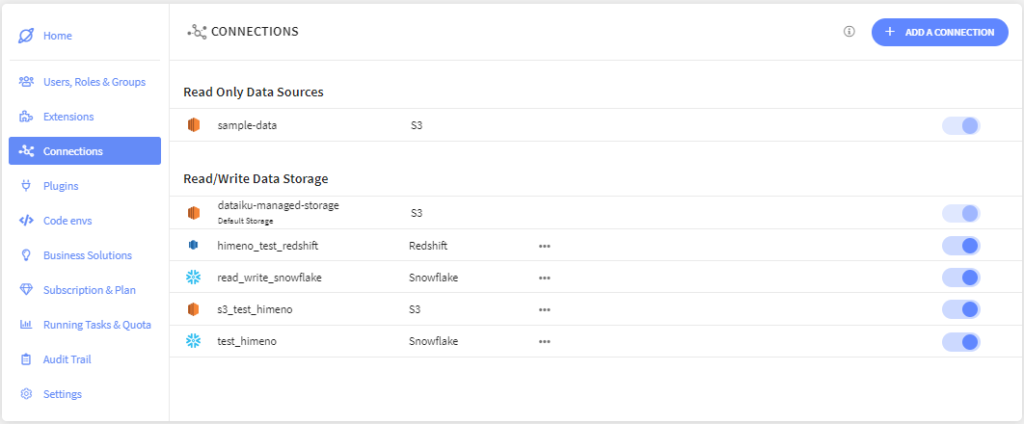
Connectionsを左側のタブから選び、「ADD A CONNECTION」ボタンを押します。
今回もRead/Writeにしました。S3を一覧から選びます。
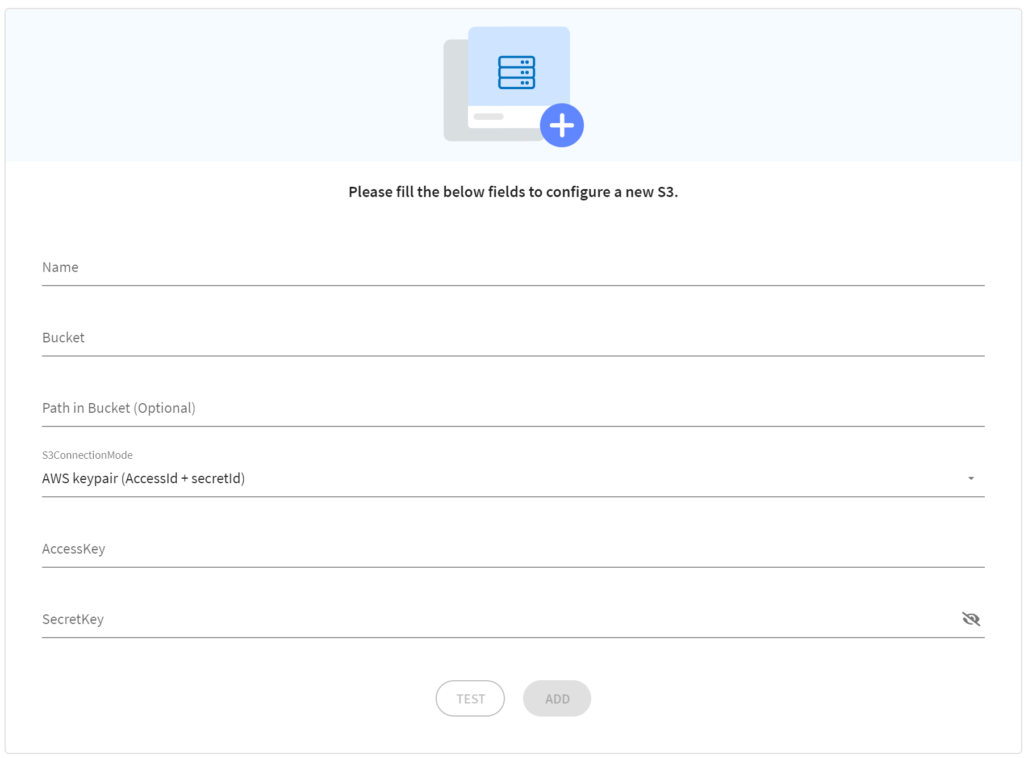
なんだかSnowflakeやRedshiftよりも項目が少なくてホッとします。
入力する内容をS3の画面から拾ってきましょう。
S3にデータを用意しよう
今回私は適当に拾ってきたオープンデータのcsvをS3のバケットに入れることにしました。
bucket名は一意になっているので、ご自身のbucket名を控えておいてください。
次に認証情報を用意します。参考にしたサイトはこちらです。
無くさないようにcsvをダウンロードしましょう!
なんと、用意する情報はこれだけ!今回短い!!
S3との接続を設定しよう
Dataiku Cloudの画面に戻って以下の項目を入力します。
- Name→この接続に好きな名前を付けます
- Bucket→先ほど控えたbucket名を入力します
- Path in Bucket (Optional)→階層分けしていたりする時に使うのかと思いますが今回はパス
- S3ConnectionMode →AWS keypair (AccessId + secretId)のままにします
- AccessKey → 先ほどダウンロードしたcsvからペーストします
- SecretKey→ 先ほどダウンロードしたcsvからペーストします
項目少ないのですぐに終わります。[ADD]ボタンでConnectionを作成しましょう。
フローから接続しよう
フローで新しいデータセットを追加します。
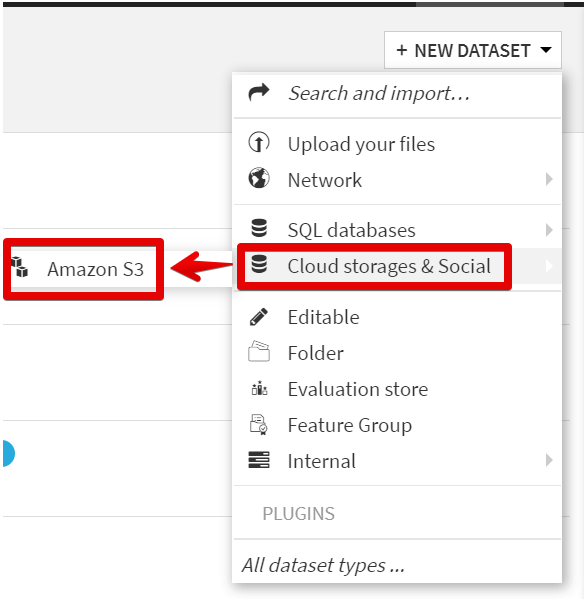
[Cloud storages & Social]にマウスオーバーして[Amazon S3]を選択します。
[S3 connection]で先ほどNameで入力したConnectionの名称を選択します。
[Browse]ボタンでオブジェクトを選択できるので、指定してデータベースを[CREATE]します。
また、Read/WriteのConnectionで作成していればアウトプットをS3に置くことも可能です。
おまけ:DataikuからRedshiftに書き込むのが遅いらしい
Redshiftに接続して書き込みなどを試していたのですが、何も加工せずにRedshiftに書き込むレシピをRunしようとするとこんなワーニングが出ました。
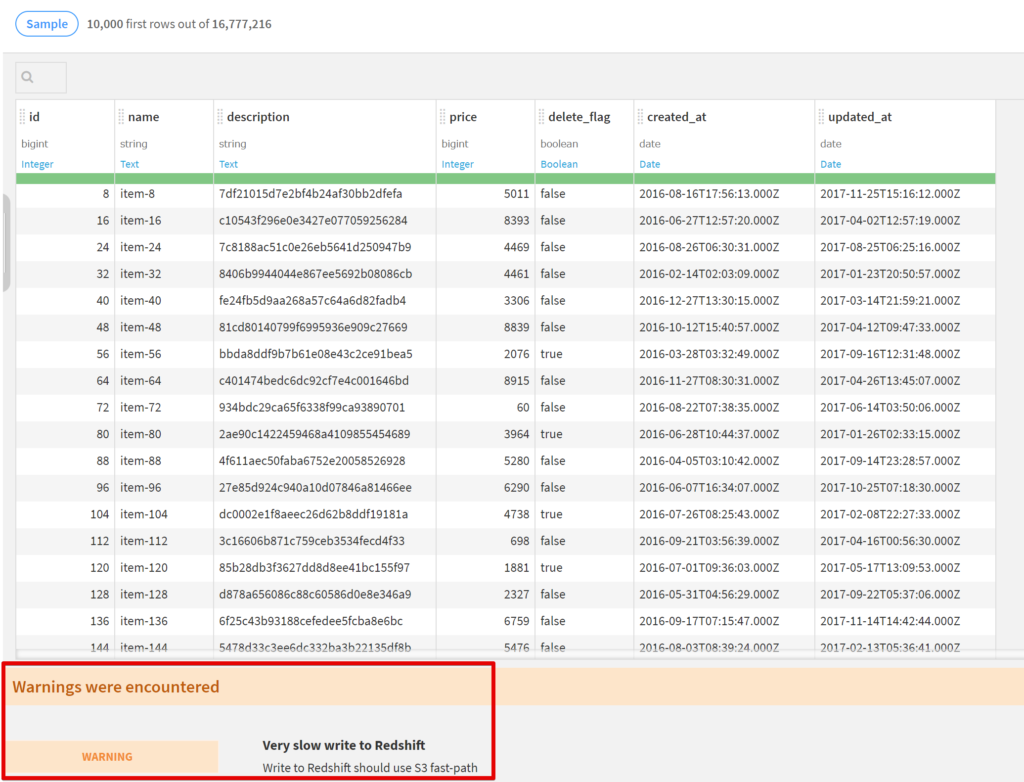
公式ドキュメントによるとS3を経由するのが早くておすすめな方法だが、Cloud版では対応してないそう…
1700万行くらいを試しに書き込んでみようと思ってやってみたのですが、ログ見てると7万行くらいで30分かかりました。
(これは待ってられない、と思って切りました。)
S3を経由する方法を試してみようと思ったんですが、Cloud版ではまだできないみたいなのでこの件はまた今度にします。