はじめに
Tableauは、データを視覚化し、インサイトを得るための強力なツールです。
しかし、データの管理やその関係性を理解するためには、メタデータの把握が欠かせません。
ここで登場するのが、Tableau Metadata APIです。
このAPIを利用することで、Tableau CloudサイトやTableau Server上のコンテンツに関する詳細な情報を取得することができます。
Tableauメタデータ APIの概要
メタデータAPIを使用することでTableau Cloud,Server上のデータソースのカラム情報やワークブックのシート情報が取得できます。
またオブジェクト情報の他に、依存関係情報の取得も行われるためTableau Metadata APIはデータマネジメントにおいて強力な機能です。
以下がタスクの例になります。
| 機能 | 説明 |
|---|---|
| コンテンツの検出 | Tableau Cloud サイトまたは Tableau Server に公開されたコンテンツに関連付けられているデータを検索 |
| 外部アセットの検索 | テーブル、データベース、データソースなどの外部アセットを特定 |
| 系統情報の追跡 | データソースやワークブックなどのコンテンツと外部アセットの関係を追跡し、特定の公開済みデータソースを使用するワークブックを識別 |
| 影響分析 | 上流および下流の系統情報を活用して、コンテンツへの変更の影響を評価。データソース変更、依存ワークシート情報の発見が可能 |
メタデータ APIとGraphQL
メタデータ APIは、クエリ言語であるGraphQLを使用します。
GraphQLに関する一般的な情報と、GraphQLで実行できることについては、GraphQL.orgを参照してください。
以下がクエリ例になります。
--データベースと付随情報を記載
query {
databases {
name
tables {
name
columns {
name
dataType
}
}
}
}メタデータ APIとREST APIとの違い
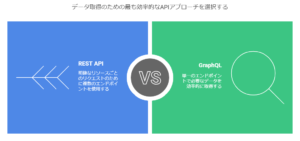
REST API
Tableau Cloudのワークブック一覧を取得する場合、GETリクエストを実行してデータを取得します。
異なる情報を取得する際は、それぞれのエンドポイントにリクエストを送信する必要があります。
メタデータ API
メタデータAPIで使用されるGraphQLは、REST APIと同様にHTTP経由でデータを取得できますが、リクエストの仕組みが異なります。
REST APIでは複数のエンドポイントに対してリクエストを行いますが、GraphQLでは単一のエンドポイントに1回のクエリを実行し、必要なデータだけを取得できます。
Tableau メタデータ APIの導入方法
APIの有効化
Tableau メタデータ APIを利用するには、まずAPIを有効化する必要があります。
Tableau CloudやTableau Serverの管理者権限を持っている場合、以下の手順で有効化できます。
- Tableau ServerまたはTableau Cloudにログイン。
- サイトの設定メニューに移動。
- 「メタデータ API」を有効にするオプションをオンにする。
- 設定を保存し、変更を適用。
認証方法
Tableau メタデータ API を使用するには、主に 3 つの認証方法があります。
| 認証方法 | 説明 | 利用ケース |
|---|---|---|
| 個人アクセストークン(PAT) | REST API の Sign In メソッドを使用し、個人アクセストークンを発行・使用 | スクリプト・バッチ処理での利用 |
| JSON Web トークン(JWT) | Tableau 接続アプリを使用して JWT を発行し、認証情報として利用 | アプリ連携・SSOの活用 |
| ユーザー名とパスワード | REST API の Sign In メソッドを使用し、ユーザーの資格情報で認証 | 手動でのAPI利用・テスト時 |
必要な権限
メタデータ API を介してメタデータにアクセスするために使用される権限は、
Tableau Cloud または Tableau Server を介してコンテンツにアクセスする権限と同様に機能します。
実践
PAT取得
個人用アクセストークンを「マイアカウント設定」→「設定」で取得します。
任意のトーク名を記載して、発行されたシークレットを残します。
実装
リクエストを送信して、GraphQLクエリを定義した値を取得します
# ライブラリインポート
import requests # HTTPリクエストを送信するためのライブラリ
import json # JSON形式のデータを扱うためのライブラリ
import openpyxl # Excelファイルを扱うためのライブラリ
import pandas as pd # データ分析のためのライブラリ
import os # オペレーティングシステムの機能を扱うためのライブラリ
from datetime import datetime # 日時を扱うためのライブラリ
import csv # CSVファイルを扱うためのライブラリ
# TableauのAPI情報
TABLEAU_SERVER = 'TableauサーバーのURL'
TABLEAU_VERSION = '3.24' # 使用するAPIのバージョン
TABLEAU_TOKEN_NAME = '# Personal Access Tokenの名前'
TABLEAU_TOKEN_VALUE = 'シークレット情報の名前'
# Tableauサーバーへサインインするための情報設定
server_name = TABLEAU_SERVER
version = TABLEAU_VERSION
site_url_id = "" # Site URLのパス、空白の場合はデフォルトサイトを使用
# Personal Access Tokenを指定する
personal_access_token_name = TABLEAU_TOKEN_NAME
personal_access_token_secret = TABLEAU_TOKEN_VALUE
# サインインURLの設定
signin_url = "https://prod-apnortheast-a.online.tableau.com/api/{version}/auth/signin".format(version=version)
# サインインのためのペイロードを作成
payload = {
"credentials": {
"personalAccessTokenName": personal_access_token_name,
"personalAccessTokenSecret": personal_access_token_secret,
"site": {"contentUrl": site_url_id}
}
}
# リクエストヘッダーを設定
headers = {
'accept': 'application/json',
'content-type': 'application/json'
}
# サーバーにリクエストを送信してサインインする
req = requests.post(signin_url, json=payload, headers=headers, verify=False)
req.raise_for_status() # ステータスコードが200でない場合は例外を発生させる
# HTTPレスポンスを取得し、JSON形式に変換
response = json.loads(req.content)
# アクセストークンを取得
token = response["credentials"]["token"]
# Site IDを取得
site_id = response["credentials"]["site"]["id"]
# Metadata APIのエンドポイントを設定
metadata_url = f"{TABLEAU_SERVER}/relationship-service-war/graphql"
# リクエストヘッダーを設定
headers = { 'X-Tableau-Auth': token, # 認証トークンをヘッダーに追加 'Content-Type': 'application/json' }
# GraphQLクエリを定義(データソース「×××」とそのフィールド情報を取得)
graphql_query = """
{
publishedDatasources(filter: { name: "×××" }) {
name
hasExtracts
upstreamTables {
name
id
}
fields {
name
id
}
}
}
"""
# APIリクエストを送信
response = requests.post(metadata_url, headers=headers, json={'query': graphql_query})
# レスポンスを処理
if response.status_code == 200:
data = response.json() # JSON形式に変換
# レスポンスの確認
print("APIレスポンス:", data) # レスポンスを出力して確認
if "data" in data and data["data"] is not None:
published_datasources = data["data"].get("publishedDatasources", [])
# CSVファイルに出力
with open("tableau_metadata_filtered.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
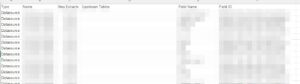
writer.writerow(["Type", "Name", "Has Extracts", "Upstream Tables", "Field Name", "Field ID"]) # ヘッダー行
# 各データソースの情報をCSVに書き込む
for datasource in published_datasources:
upstream_tables = ', '.join([f"{table['name']} (ID: {table['id']})" for table in datasource["upstreamTables"]])
for field in datasource.get("fields", []):
writer.writerow([
"Datasource",
datasource["name"],
datasource["hasExtracts"],
upstream_tables,
field["name"],
field["id"],
])
print("CSVファイル 'tableau_metadata_filtered.csv' に出力しました。")
else:
print("エラー: レスポンスにデータが見つかりませんでした。")
else:
print(f"データの取得に失敗しました。HTTP ステータスコード: {response.status_code}")
print("レスポンス:", response.text)
# サインアウト
signout_url = f"{TABLEAU_SERVER}/api/{TABLEAU_VERSION}/auth/signout"
requests.post(signout_url, headers={'X-Tableau-Auth': token}) # サインアウトリクエストを送信
print("正常にサインアウトしました。")最終的に以下のようにCSV形式に落とせました
使用してみた感想
ワークブックやデータソースのメタデータを一括で取得できる点は使い勝手が良かったです。
依存関係も取得できるのでリネージなど自力でできる感もあるので、深堀したら便利な機能だと思いました。
一方でfilterの設定がワークブックやデータソースなどオブジェクト単位でprojectで絞るとかできないのがイマイチだと思いました。
(やり方あれば有識者の方に教えていただきたいです、、、)