こんにちは。Ozawaです。
今回はSnowflake Cortexサービスのうち、LLM(Large Language Model)関数について、出来ること・コスト感・自社データの安全性を基準にまとめていきたいと思います。
早速ですが、ここでいくつか固有名詞が出てきたので整理します。(下図を参照)
・Snowflake Cortex:Snowflake上で自然言語処理を使ったサービスの総称。
・LLM関数:Snowflake Cortexのうちの1つのサービスで、自然言語処理をクエリ上で実行できます。

※ ちなみに、Snowflake Cortexサービスには、他にも3点ありますが、今回は割愛します。
・Document AI:画像から取り出したい情報を抽出。
・Universal Search:テーブルやロール等のSnowflake上のすべてのオブジェクトを一斉で検索。
・Snowflake Copilot:ユーザの要望文から、それに沿ったSQLを自動で作成してくれる。
1. できること
自然言語タスクをSnowflake上のLLM関数で行うことができます。
・COMPLETE:汎用的な会話(ChaoGPTのイメージ)。使用するモデルを複数の候補から選択できます。
・EXTRACT_ANSWER:文章とそれに関する質問を入力し、答えを出力(読解問題のイメージ)
・SENTIMENT:文章のネガポジ判定
・SUMMARIZE:文章の要約
・TRANSLATE:文章の翻訳
・CLASSIFY_TEXT:文章の分類
また、追加で次の処理を行うことができます。
・EMBED_TEXT:単語や文章をベクトル化し、機械学習に入れるデータに変換する。
・FINETUNE:Snowflakeデフォルトのモデルをファインチューニング(ある分野に最適化するように微調整)してくれる。
試しに、Snowflake LLM関数をいくつか実行してみました。
① TRANSLATE関数で日本語から英語に翻訳
リンゴを説明した文章を日本語から英語に変換してみます。
「丸く、通常は赤または緑の果物で、甘くてシャキシャキした味があり、よく生で食べられたり料理に使われたりします。」という文章が、「Round, usually red or green fruit with a sweet and shaky taste that is often eaten raw or used in cooking.」と翻訳されました。
-- リンゴを説明した文章を日本語から英語に変換
SELECT SNOWFLAKE.CORTEX.TRANSLATE('丸く、通常は赤または緑の果物で、甘くてシャキシャキした味があり、よく生で食べられたり料理に使われたりします。', 'ja', 'en');
--> Round, usually red or green fruit with a sweet and shaky taste that is often eaten raw or used in cooking② TRANSLATE関数で翻訳した文章をCLASSIFY_TEXTで分類
次に、「リンゴ」「バナナ」というカテゴリのうち、リンゴを説明する英語文章がどちらに分類されるかを検証します。
結果、リンゴを説明する文章は、「リンゴ」カテゴリに分類され、想定通りの翻訳→分類を行うことができました。
-- リンゴを説明した文章を日本語から英語に変換し、
-- 英語の説明文が、「リンゴ」「バナナ」のどちらのカテゴリに分類されるかを調査
select SNOWFLAKE.CORTEX.CLASSIFY_TEXT(
SNOWFLAKE.CORTEX.TRANSLATE('丸く、通常は赤または緑の果物で、甘くてシャキシャキした味があり、よく生で食べられたり料理に使われたりします。', 'ja', 'en') //翻訳関数
,['Apple', 'Banana']
);
-->
-- {
-- "label": "Apple"
-- }※ ちなみに残念なことに、まだ日本リージョンではEMBED_TEXTのみしかLLM関数を使用することができません。
現在使用できるリージョンはこちらを参照ください。筆者はAWS US WEST(オレゴン)を使用
2. コスト
SnowflakeのLLM関数を使用する場合、クエリの実行時間の代わりに、処理されるトークン数に比例します。
精度の良いCOMPLETE(会話)をする場合、mistral-largeモデルを使用し、5.1クレジット/100万トークンとなります。
1トークンが約4文字(WordではなくCharacter)なので、さらにイメージしやすくしやすいように、100万文字あたりのコスト(円)を求めます。
// Enterprise Aws Tokyoの場合の料金検証。(今後Tokyoリージョンで使用できると仮定する)
・5.1クレジット * 約7ドル/クレジット * 約150ドル/円 → 約5300円
・100万トークン * 4文字/1トークン → 400万文字
⇒ 1300円 / 100万文字100万文字あたりの1300円となりました。
注意として、例えばレコード1つにつき100文字の英語の場合、1万レコードを処理すると1300円となります。100文字は先ほどのリンゴの英語文章の文字数に匹敵するので、コストの膨れ上がりには要警戒です。
また、英語はスペースにより単語を分けていますが、日本語は1文字ごとにどこまでが文節かを把握する必要があり、その影響から日本語1文字は英語1文字よりもLLM使用コストが高くなる可能性に注意してください。
次にLLM使用コストの確認方法ですが、CORTEX_FUNCTIONS_USAGE_HISTORY関数で確認することができます。
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.CORTEX_FUNCTIONS_USAGE_HISTORY;
// LLMを使用したクエリのLLM使用コンピュートコストが表示される。(TOKEN_CREDITS)
-- START_TIME END_TIME FUNCTION_NAME MODEL_NAME WAREHOUSE_ID TOKEN_CREDITS TOKENS
-- 2024-09-22 05:00:00.000 -0700 2024-09-22 06:00:00.000 -0700 CLASSIFY_TEXT 4 0.000236300 170
-- 2024-09-22 06:00:00.000 -0700 2024-09-22 07:00:00.000 -0700 CLASSIFY_TEXT 4 0.000472600 340
-- 2024-09-22 06:00:00.000 -0700 2024-09-22 07:00:00.000 -0700 TRANSLATE 4 0.000044220 134また、Cost ManagementのConsumption上では、LLM関数のコストは、クエリ実行時のウェアハウスの料金として表示されるようです。
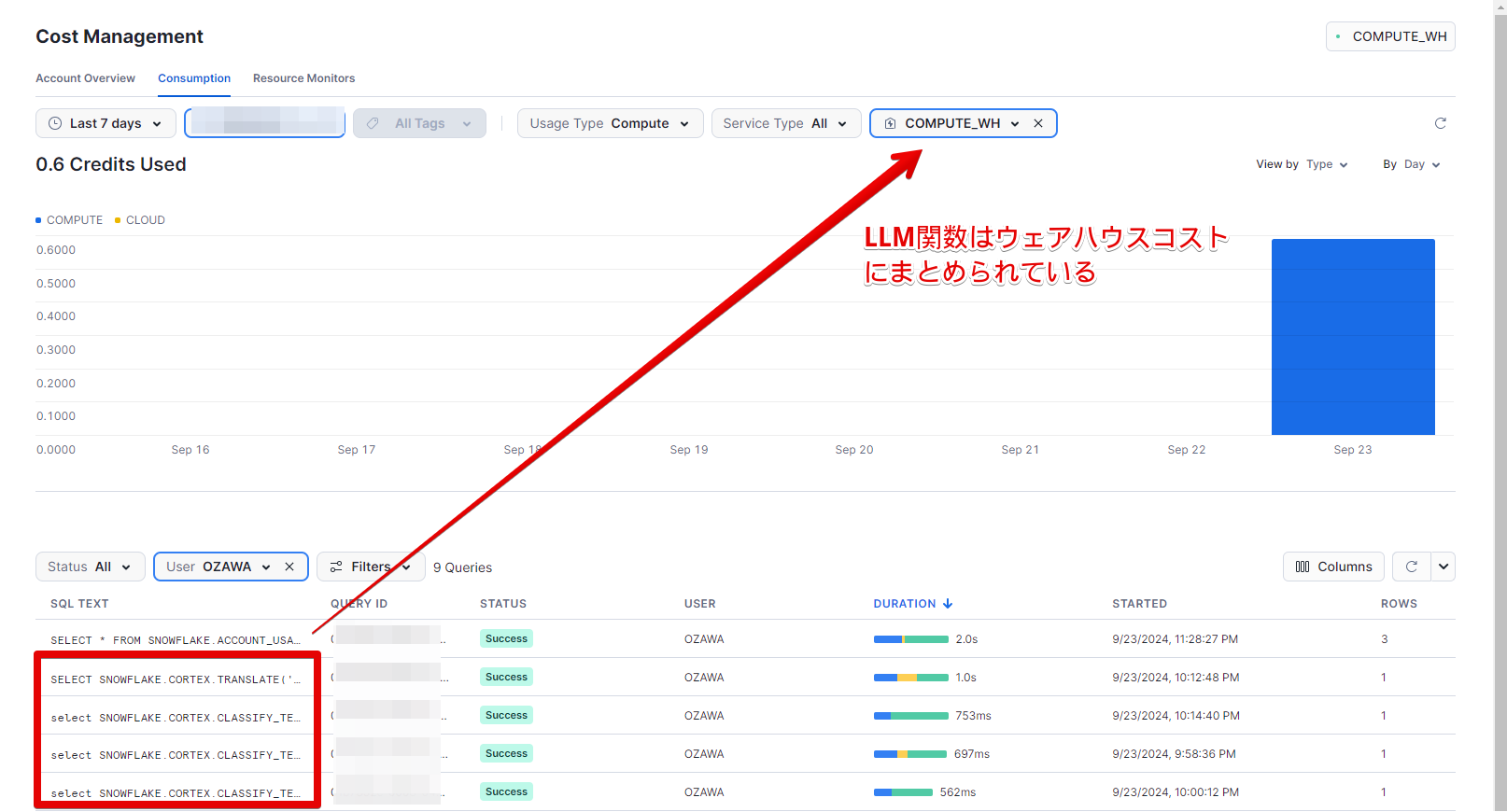
・ウェアハウスコストとなっているが、ウェアハウス実行コストが二重にかかっているわけではない。
・LLM関数コストが消えているわけではないので使い過ぎに注意!
この2点だけ抑えておいてください!
3. 自社データの安全性
LLM関数を使用した時に、Snowflake上に搭載されている自社データが、Snowflake他社ユーザーに見られることはありません。
・LLM関数で使用される入出力データは他のSnowflakeユーザーには共有されません。
・また、SnowflakeのデフォルトのMLのモデルの学習データとして入出力データは使用されません。
ファインチューニングする場合は、ファインチューニングされたモデルをテーブルと同じ階層に格納するため、そのモデルを他のユーザに使用されることはありません。
したがって、自社データが入出力を介して他社に見られたり、モデルの学習を経由して他社に流出することはありません。
参照:Snowflake AI の信頼性と安全性に関するよくある質問
おわりに
truestarでは、Snowflake導入検討、導入支援や環境構築まで幅広くサポート可能です。
Snowflakeに゙興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらから相談ください!
また、truestarではSnowflake Marketplaceにて、加工済みオープンデータを無償提供するPrepper Open Data Bank、全国の飲食店の情報を集めたデータセットの販売を行っております。(サービスリンク)
これまでのSnowflakeに関する記事はこちら




