こんにちは。t.ozawaです。
先日snowflake data clowd world tourに参加し、「Snowflake クエリパフォーマンス チューニング入門」公演を聴いて来ましたので、その内容を共有します!
本講演では、snowflake上でクエリの実行が遅い事象があった場合にどんな原因があるのか、どうやって解決するかについて有益な情報がありました。
クエリが遅い原因を細分化
講演によると、クエリの実行が遅い、という事象でも大きく分けて、二つに分けることができます。
- 複数クエリをフローとして実行する場合に遅くなる
- 単一のクエリを実行する場合に遅くなる
複数クエリのフロー全体が原因なのか、単一の特定のクエリが原因なのかを判別するには、サイドバーのADMIN→WEARHOUSEから「ウェアハウスアクティビティ」を見ます。
ウェアハウスアクティビティでは、ウェアハウスリソースがどのように消費したか?を表示してくれます。

青色で表示されたバーが正常に計算を実行されているリソースに対して、黄色で表示されたものが他のクエリ実行によって、実行開始待ちのリソースになります。
青色の実行時間が大きいと、ウェアハウスは長時間頑張ってクエリを実行していることを指しています。
黄色の実行待ちのリソースが大きいほど、無駄な時間やリソースを使ってしまっていることになります。
左側の赤丸のように、長時間にわたって黄色バーが大きい場合、互いにリソースを奪い合った複数のクエリによって、実行時間が長くなっている場合があります。青色バーが全体的に大きい場合も、一連のクエリの処理内容が重く、全体的に実行時間が長くなっていることを意味します。
一方、青色・黄色バーが一瞬だけ極端に伸びている場合、単一のクエリの実行時間が長くなっている可能性が高いです。
それでは実行時間が長い理由が「複数のクエリが原因の場合」、「単一のクエリが原因の場合」の2種類で解決策を見ていきます。
複数クエリを実行する際に遅くなる場合
複数クエリのフローが遅い場合の解決方法の一覧です。
| 解決方法 | 解決できるケース |
| 仮想ウェアハウスサイズを上げる | フローの中で特定のクエリの実行時間が遅い |
| 最大クラスター数を増やす | フローの中で並列に実行するクエリの挙動が遅い |
| 複数の仮想ウェアハウスで分散する | フローの中で並列に実行するクエリの挙動が遅い 「このクエリにはこのWH」という確固たる方針がある場合 |
| クエリ数を削減する | 複数のクエリを使って少ないレコードを複数回読み込んでおり、ひとつのクエリにまとめられそう |
1. 仮想ウェアハウスサイズを上げる
仮想ウェアハウスを上げることで、単一のクエリの実行クオリティを高め、速度を向上することができます。
例えば、クエリの実行速度が全体的に遅く、待機中の時間もそこまで見られない場合は、仮想ウェアハウスのサイズをXSサイズからMサイズへと高めて、リソースのキャパを向上して対応します。
2. 最大クラスター数を増やす
ウェアハウスのマルチクラスター機能を使って最大クラスター数を増やすと、複数のウェアハウスを使って並列実行ができます。
並列実行によって、一度に処理するキャパシティが増えるため、複数のクエリを複数のウェアハウスで分担することができます。
これによって、実行待機中のクエリが減るため、複数のクエリの総実行時間を削減できます。
3. 複数の仮想ウェアハウスで分散する
「最大クラスター数を増やす」ことで並列処理を可能にし、実行時間を削減する手法と基本的には一緒ですが、こちらの手法では、特定のウェアハウスを特定のクエリに割り当てることができます。
例えば、軽いクエリ1と重たいクエリ2があるとして、軽いクエリ1にはXSサイズを割り当て、重たいクエリ2にはLサイズを割り当てます。
--クエリ1ではXSサイズを使い、USE WAREHOUSE WH_XS;
SELECT * FROM TABLE1;
--クエリ2ではLサイズを使う。
USE WAREHOUSE WH_L;
SELECT * FROM TABLE2;こうすることで、無駄のない処理スペックと消費クレジットの削減を実現できます。
基本的には、自動的に使うウェアハウス数を調整する「最大クラスター数を増やす」手法でよいのですが、特定のクエリに対して特定のウェアハウスを使うという確固たる方針があれば、「複数の仮想ウェアハウスで分散する」手法が良いかと思います。
4. クエリ数を削減する
クエリを一つにまとめられるものは、まとめてしまったほうが、処理速度が速くなります。
--まとめられるクエリはまとめてしまったほうが早いです。
SELECT * FROM TABLE1 LIMIT 10000;
SELECT * FROM TABLE1 LIMIT 10000 OFFSET 10000;
--↓↓↓↓↓--
SELECT * FROM TABLE1 LIMIT 20000;単一のクエリを実行する際に遅くなる場合
単一クエリが遅い場合の解決方法の一覧です。
| 解決方法 | 解決できるケース |
| クラスタリングキーを活用 | データを読み込むサイズが大きいため時間がかかる |
| アスタリスクを使わずに特定のカラムを指定 | セレクトされた出力サイズが膨大なため時間がかかる |
| 結合キーを見直す | 結合に時間がかかる |
1. クラスタリングキーを活用
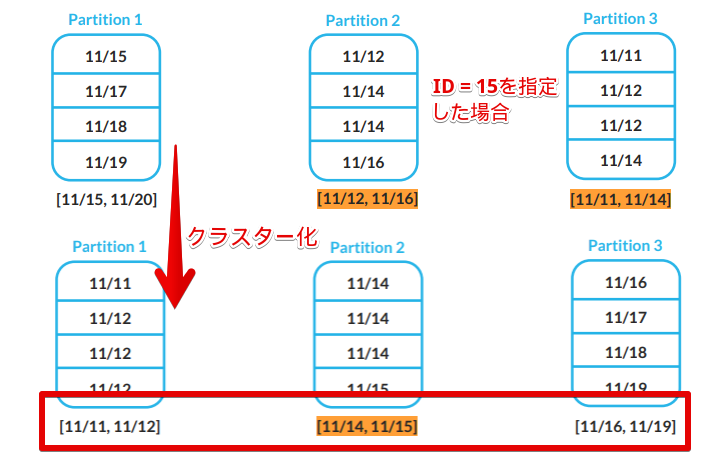
クラスタリングキーを使用してマイクロパーテションを最適化することで、データを読み込む量を最適化できます。
マイクロパーテションが最適化されると、クラスタリングキーに指定したカラムが綺麗に分かれるため(下図)、フィルターを使ったデータを読み込む際には、データを読み込む量を最小化することができます。
2. アスタリスクを使わずに特定のカラムを指定
SELECTする際にアスタリスクを用いると、出力されるデータ量が多くなります。
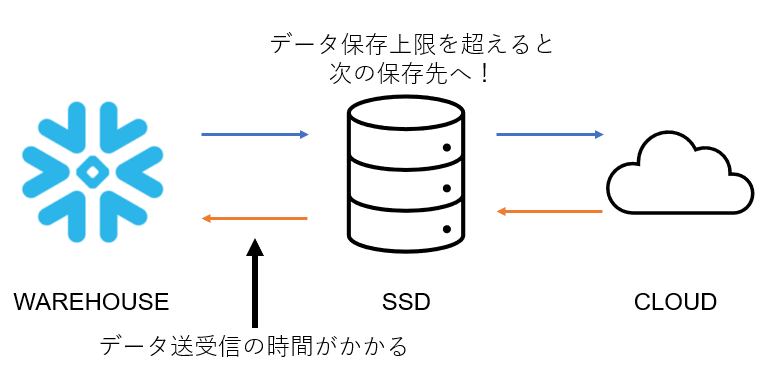
データ量が多くなると、ウェアハウスのメモリの保存量の限界から漏れたデータは、SSDやS3といった別の場所に一時格納「スピル」されます。
しかし、別の場所にスピルされたデータは読み書きに時間がかかるため、なるべくスピルは避けたいということになります。
出力カラムを指定することで、データ量を削減し、スピルによる計算時間を削減することができます。
3. 結合キーを見直す
結合キーを見直し、結合での出力を抑えることで、スピル回避につながります。
特に、結合キーを十分に指定し、結合キーにOR条件を使用しないことによって、結合処理における出力データを減らすことができます。
結合キーが不十分であると、実質CROSS JOINのような働きになってしまい、総当たりに限りなく近い結合になってしまうため、出力を抑えるような結合キーの指定が必要です。
また、結合キーにOR条件を使うと、内部では「一旦CROSS JOINした後に、フィルターする」処理を行ってしまうため、処理の途中で膨大なデータが発生してしまいます。
OR条件の代わりに、複数の結合結果をユニオンすることで、結合による速度低下を避けることができます。(下記コード例)
SELECT * FROM A
LEFT JOIN B
ON A.ID1 = B.ID2 OR A.ID2 = B.ID2 --OR条件は避ける!
-- ↓↓↓↓↓↓ --
SELECT * FROM A --それぞれの結合をUNIONする形で対応!
LEFT JOIN B
ON A.ID1 = B.ID1
UNION
SELECT * FROM A
LEFT JOIN B
ON A.ID2 = B.ID2
おわりに
クエリの実行が遅くなる原因の細分化方法と、解決方法を紹介しました。
弊社の逆ジオコーディングのアプリでは、まさに結合爆発による「スピル」に直面して、クエリ実行が非常に重くなってしまった経験があります。その際は、結合キーの条件を厳しくすることで、対応しました。
結合条件を工夫した逆ジオコーディングのアプリのブログはこちら
truestarではSnowflakeの検討、導入支援や環境構築からアプリ開発まで幅広くサポート可能です。
Snowflakeに興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらからご相談ください!



