はじめに
最近よく、「自然言語処理」という言葉を聞くので、どのようなものかと興味があり、勉強しております。
学んだことをブログに記載していこうと思います。
まずは、データ収集のため、Webスクレイピングを実施しましたので、紹介します。
Webスクレイピングとは?
Webスクレイピングとは、Webサイトから特定の情報を抽出する技術のことです。
詳しくは、こちらのサイトが参考になります。
また、Webサイトの情報を取得するのにとっても便利なのですが、
法律・サイトの利用規約に違反しないかや、取得先のサーバーに負荷を与えすぎないか等、事前に確認する必要があります。
Webスクレイピングをする際の確認事項については、こちらのサイトが参考になりますので、ご参考ください。
今回は、Uta-Netさんから、私の大好きなKing Gnuの歌詞をWebスクレイピングで取得したいと思います。
利用したツール
言語:Python
個人的にPythonを学習中なので、Pythonを利用します。
実行環境:Google Colaboratory
Google Colaboratoryを利用しました。Googleアカウントを所有していれば、ブラウザ上で手軽にPythonのコードを実行できるので、ぜひ試して見てください。
Webスクレイピングパッケージ:BeautifulSoup
BeautifulSoupはHTMLやXMLを構文解析してくれるPythonパッケージで、今回はHTMLより必要な情報を抽出するために利用します。
どのように取得していくか
①King Gnuの歌詞一覧リストページより、歌詞ページのURLパスを取得
こちらがKing Gnuの歌詞一覧リストページです。
各曲名の<a>に、歌詞ページヘのパスがあるので、BeautifulSoupでこちらのパスを取得し、歌詞ページのURLを生成します。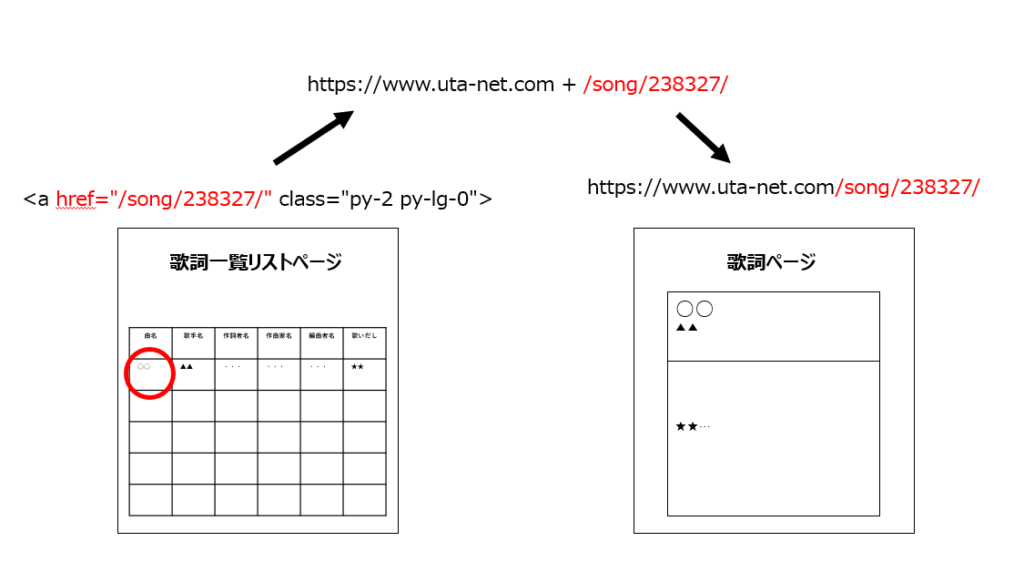
②歌詞ページより、曲名、歌詞、発売日、教示回数を取得
①で生成した歌詞ページヘのURLへ一つずつアクセスします。
曲名、歌詞、発売日、表示回数の情報は、BeautifulSoupで対象のタグを指定し、取得します。
| 曲名 | <h2>より取得 |
| 歌詞 | itemprop=’lyrics’である<div>より取得 |
| 発売日 | class_=’detail’である<p>より取得後、yyyy/MM/ddにマッチする文字列を取得 |
| 表示回数 | class_=’detail’である<p>より取得後、「この曲の表示回数:○回」の○部分の数値を取得 |
③取得した情報をデータフレームにし、CSV出力
都度データを取得しなくてもいいように、CSVで出力します。
では、やってみます!
①作成したコード
#ライブラリインポート
import requests
from bs4 import BeautifulSoup
import pandas as pd
from datetime import datetime
import datetime
import time
import re
#取得したデータを格納するデータフレームを作成
KingGnu_songs_df = pd.DataFrame(columns=['song_name','lyrics','release_date','impression'])
#Uta-Net先頭URL
base_url = 'https://www.uta-net.com'
#King Gnuの歌詞一覧ページURL
url = 'https://www.uta-net.com/artist/23343/'
#歌詞一覧ページのHTML取得
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
links = soup.find_all('td', class_='sp-w-100 pt-0 pt-lg-2')
#歌詞ページより、情報を取得
for link in links:
a = base_url + (link.a.get('href'))
#歌詞ページよりHTMLを取得
response_a = requests.get(a)
soup_a = BeautifulSoup(response_a.text, 'lxml')
#曲名取得
song_name = soup_a.find('h2').text
#歌詞取得
song_lyric = soup_a.find('div', itemprop='lyrics').text.replace('\n','')
#発売日取得
detail = soup_a.find('p', class_='detail').text
match = re.search(r'\d{4}/\d{2}/\d{2}', detail)
release_date = datetime.datetime.strptime(match.group(), '%Y/%m/%d').date()
#表示回数を取得
p = r'この曲の表示回数:(.*)回'
impression = re.search(p, detail).group(1)
#取得したデータフレームに追加
temp_df = pd.DataFrame([[song_name],[song_lyric],[release_date],[impression]], index=KingGnu_songs_df.columns).T
KingGnu_songs_df = KingGnu_songs_df.append(temp_df, ignore_index=True)
#2秒待機
time.sleep(2)
#csv出力
KingGnu_songs_df.to_csv('KingGnu_songs_df.csv', mode='w')For文内で「②歌詞ページより、曲名、歌詞、発売日、教示回数を取得」で述べた事項を実施した後、
データフレームを作成しています。
For文の最後で、Uta-Netのサーバーに負荷を与えないよう、2秒待ってから次の曲の情報を取得するようにしています。
②取得した情報
上記のコードを実行して得られたデータをこんな感じです。
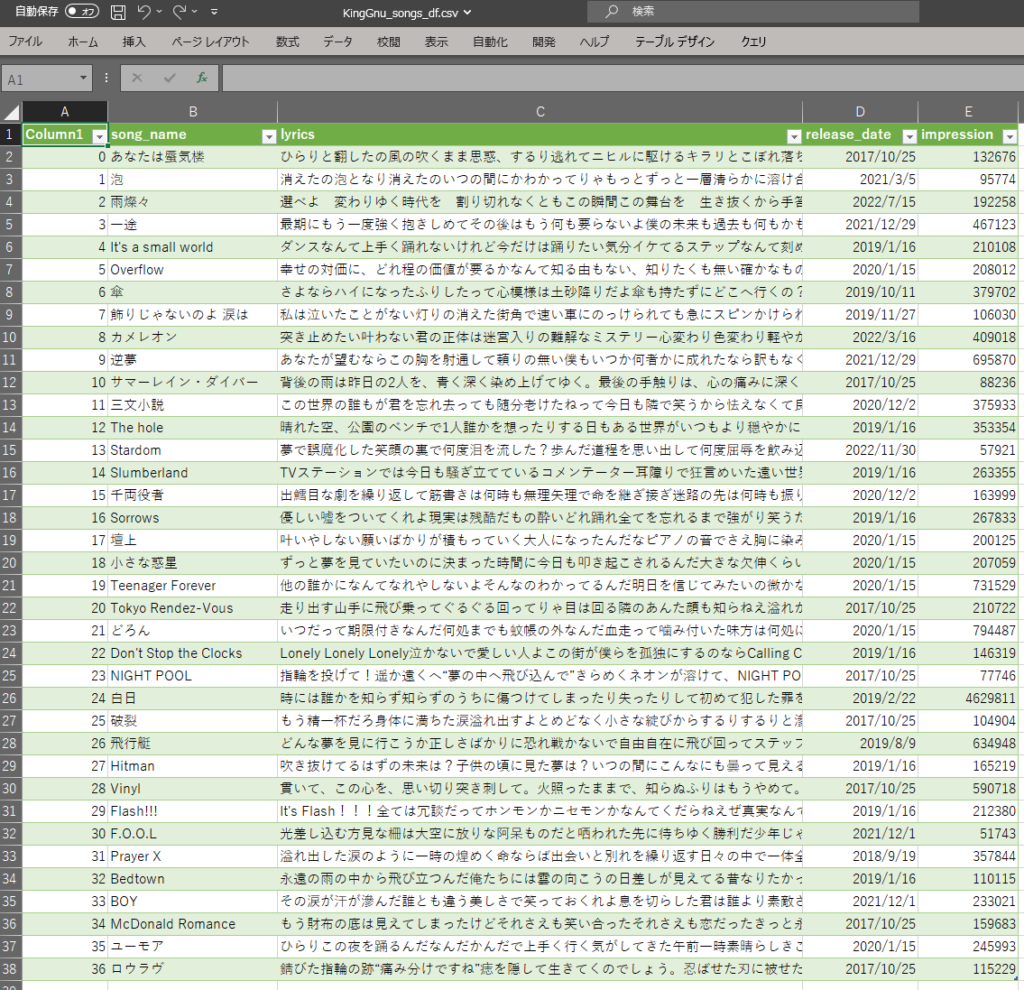
きれいに取得できました!(やった!)
参考にしたサイト
・Uta-Netのスクレイピング
・ミスチルの歌詞をスクレイピングで取得してみた【Beautiful Soup】
最後に
いかがでしたでしょうか。
Webサイトからの情報取得方法の一例として、参考になれば幸いです。
今回取得したデータを使って、次回以降は形態素解析ソフトウェアを利用したり、ワードクラウド作ってみたりしたいと思います!