はじめに
こんにちは。truestarのこみぃです。
6/2-5で行われたSnowflake Summitで発表されたSemantic View機能について、truestarがローンチパートナーとしてロゴが掲載されました。
https://x.com/kommy_jp/status/1929951625357209862
PRESS RELEASEにもしっかり載っています。
In addition, Snowflake unveiled sharing of Semantic Models (now in private preview), which allows users to easily integrate AI-ready structured data within their Snowflake Cortex AI apps and agents — both from internal teams or third-party providers like CARTO, CB Insights, Cotality™ powered by Bobsled, Deutsche Börse, IPinfo, and truestar. With Snowflake’s latest collaboration innovations, enterprises can accelerate their AI initiatives with easy access to an expansive ecosystem of data and agentic AI-ready products, all from within the secure perimeter of the AI Data Cloud.
本日はそんなお話をします。
AI-Ready
今回Summitに参加された方は、会場のブースなどでたびたびAI-Readyという単語を見かけたと思います。このAI-Readyという概念はおそらく今後数年のバズワードになると思います。
AI-Readyというのは自社がAIを活用できるようになった状態を表す単語です。自社がAIを十分に活用できるようになるためには、以下のステップを満たす必要があります。
- 十分に構造化データが取得され、データウェアハウスに収められている
- それらの構造化データが適切に加工されてデータマートになっている
- 半構造化データや非構造化データが集積されてデータウェアハウスに収められている
- これらのデータのメタデータが整理され、AIが読める形でドキュメントが提供されている
これまでデータ基盤構築という話になると、構造化データにまつわる上の2つと、それを活用するBIツールやReverse ETLの整備が主な議題だったと思います。
AIを活用していくには下の2つが新たに必要となります。
Semantic View
Semantic Viewは特定のデータに対してAIが読める形にしたドキュメントと考えるとわかりやすいです。先述の4つのうち太字にした4つ目がSemantic Viewというわけです。
Semantic ViewはデータマートとAIを繋ぐためのドキュメントで、以下の要素を含んだものです。
- データベース・スキーマ・テーブル名
- 各テーブルや各カラムにどんなデータが入っているか
- それらのデータは自社で使うビジネス用語や指標とどのように紐づいているか
- 各ビジネス用語の同義語(synonym)
- テーブル同士をjoinする際のキーは何か
- サンプルクエリ
これらの情報は人間が読む場合にはデータカタログや仕様書を提供するのが一般的です。AIに渡すデータカタログや仕様書だと考えるとわかりやすいかもしれません。
データマネジメントに詳しい方は気づいたかもしれませんが、これは元々セマンティックモデルという名前で存在した概念です。SnowflakeのSemantic Viewはセマンティックモデルをスキーマオブジェクトとして作成する機能です。
なお、このSemantic Viewは現状ではビジネス要件上組み合わせて使われるデータごとに定義する形になります。
実際に使ってみる
というわけで、実際に使ってみましょう。
PODBに付属しているSemantic Viewを単体で使う
まずは単体で使ってみましょう。以下のPODBのデータをマーケットプレイスでGetしてみてください。日本のカレンダーデータです。
ちなみに、実はCategoriesに「Cortex AI Ready」というカテゴリが追加されています。Semantic Viewが付属されたデータということです。こんなところにもAI-Ready
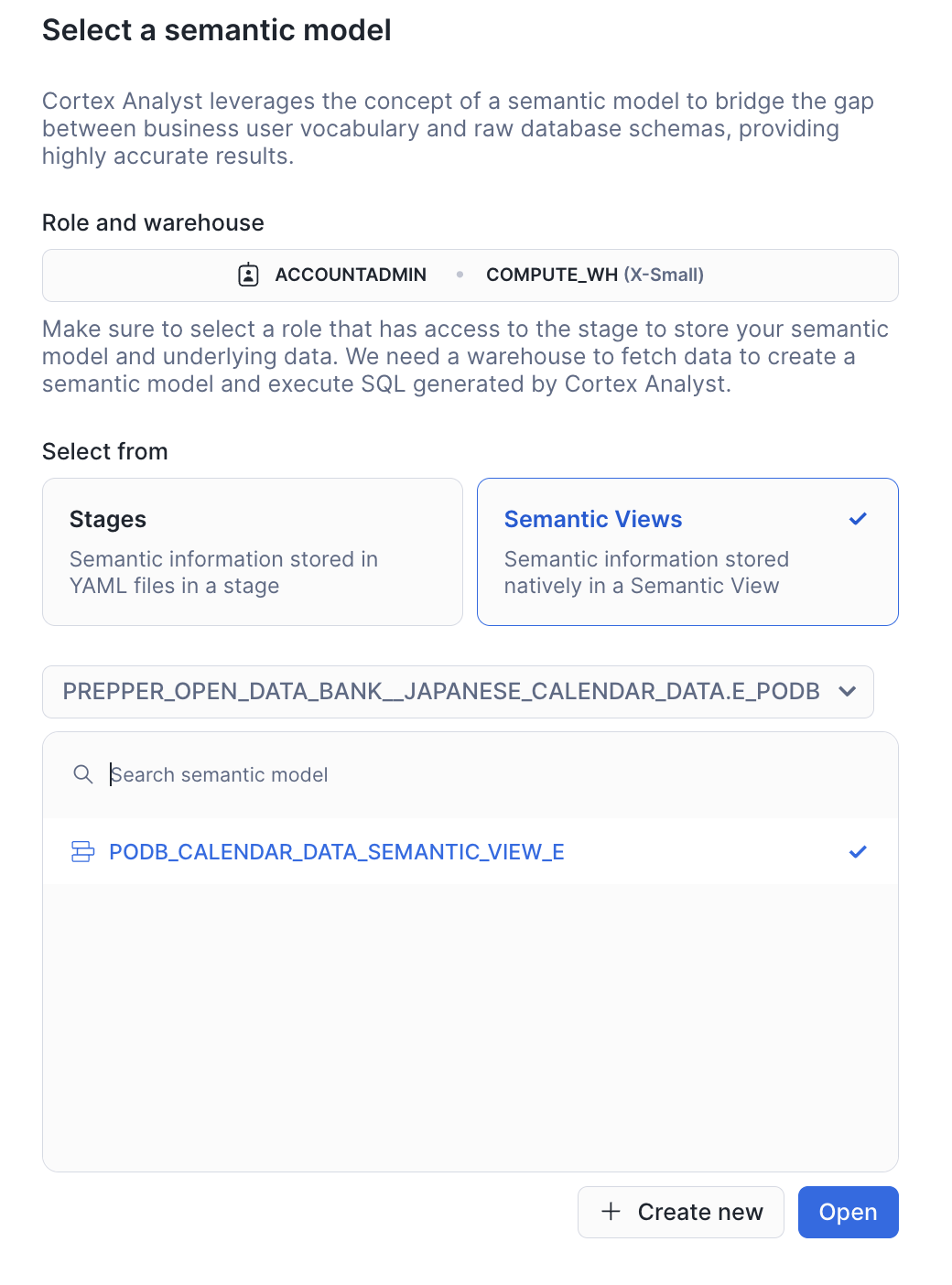
Getできたら「AI ML」->「Cortex Analyst」の「Try」ボタンを押し、以下のようにPODB_CALENDAR_DATA_SEMANTIC_VIEW_Eを選択してOpenを押してください。
表示されたチャット画面で、このデータについて自然言語で問い合わせることができます(残念ながら英語のみです)。
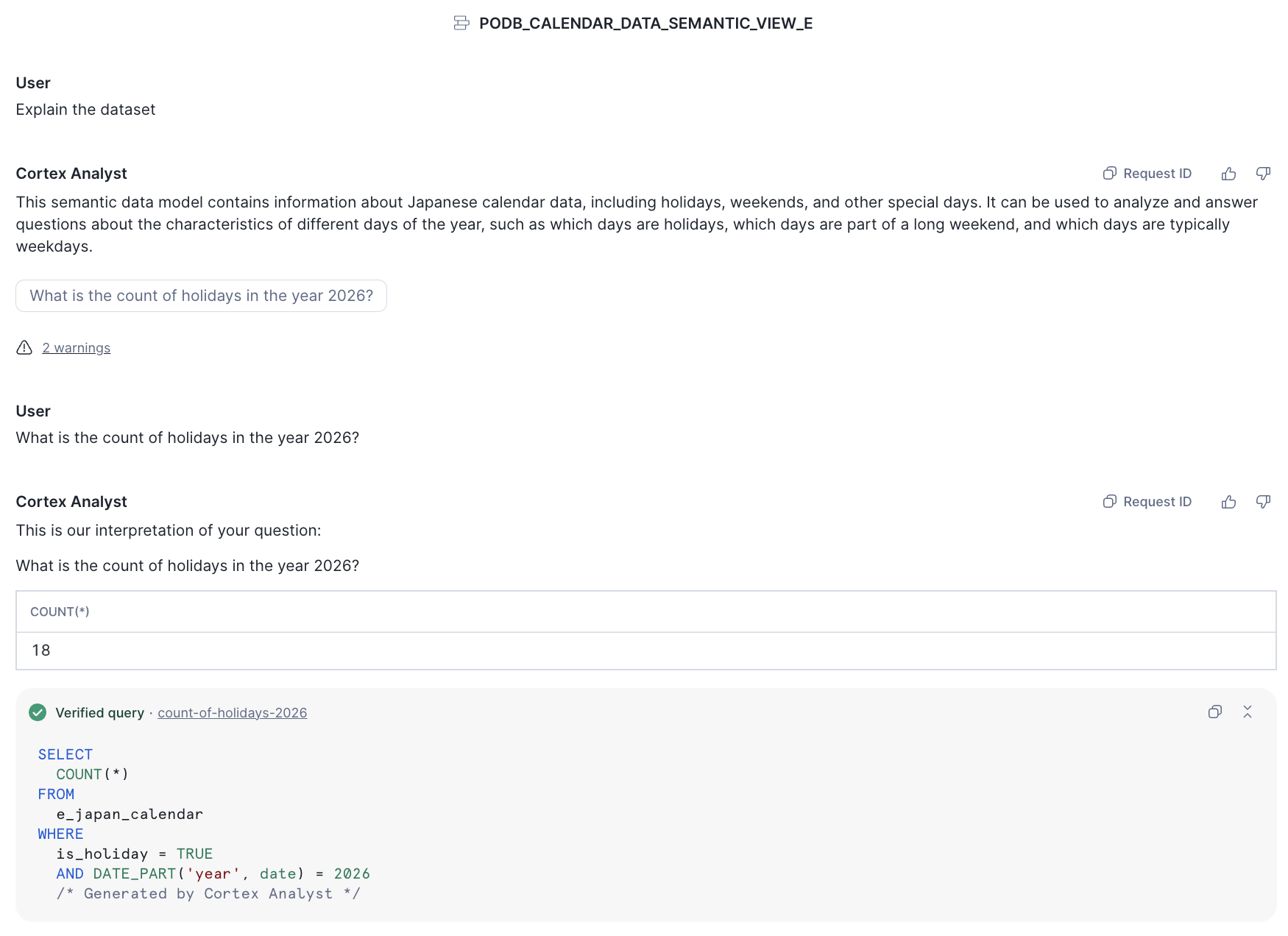
例えばこのように、データの概要について質問したり、中身について質問したりすることができます。
自社のデータと組み合わせて使う
さて、せっかくカレンダーのデータがあるんですから、自社のデータと組み合わせて使いたいですね。そのやり方も解説します。
まずは先ほどのCortex Analystの画面で右上の3点リーダからDownload YAMLを押してください。これがカレンダーのSemantic ViewをYAML形式で保存したものです。
次に、自社のデータと組み合わせたSemantic Viewを作ります。
Semantic Viewはスキーマオブジェクトなのでスキーマ配下に作成されるのですが、なぜかStageがないと作れないので、先にCreate StageでSemantic Viewを配置したい先にStageを作ります。
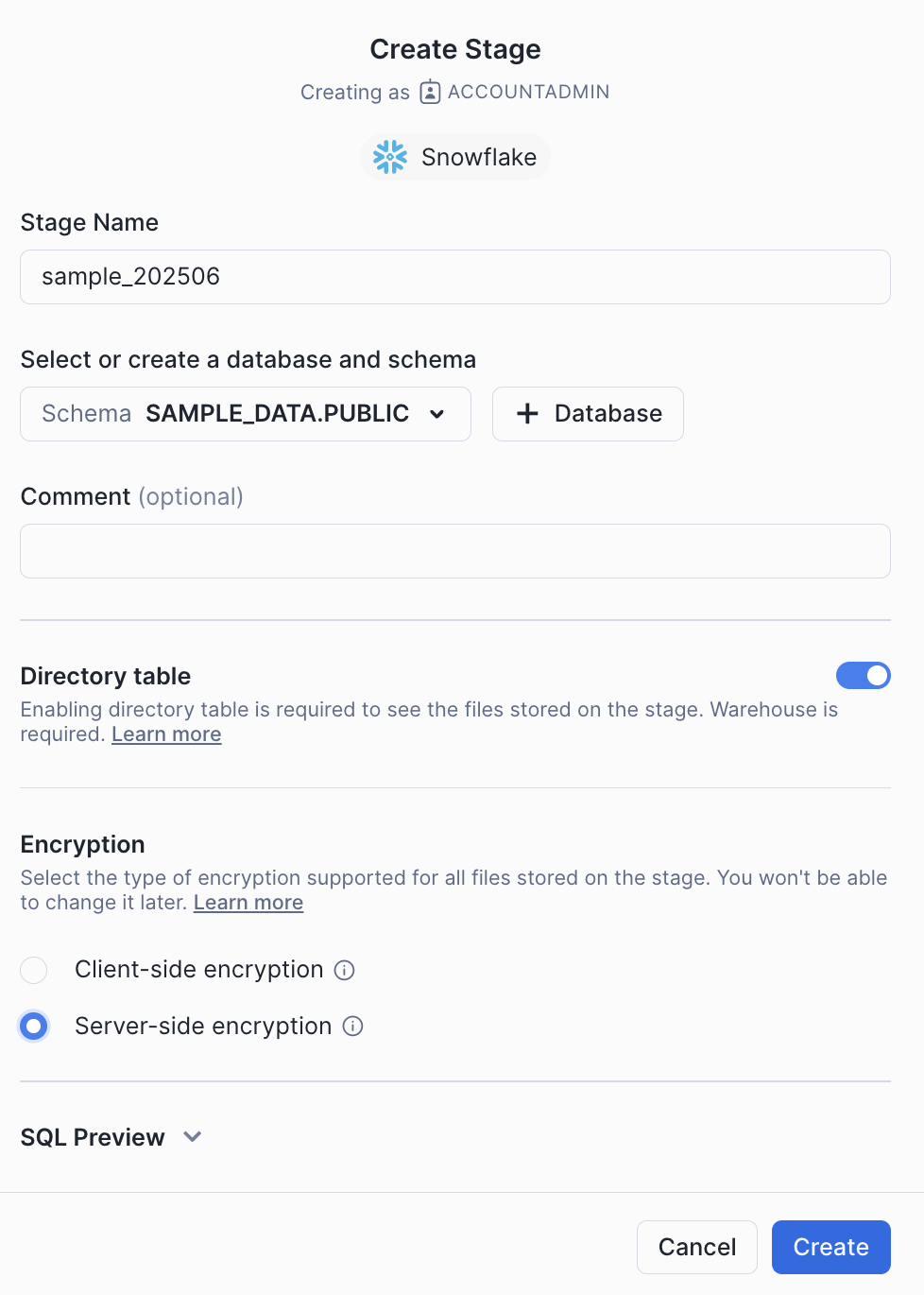
次に「AI ML」->「Cortex Analyst」の「Try」ボタンを押し、今度は「Create new」を押します。
Semantic View名はよしなにつけていただき、Select Table画面ではPODBのカレンダーのViewと
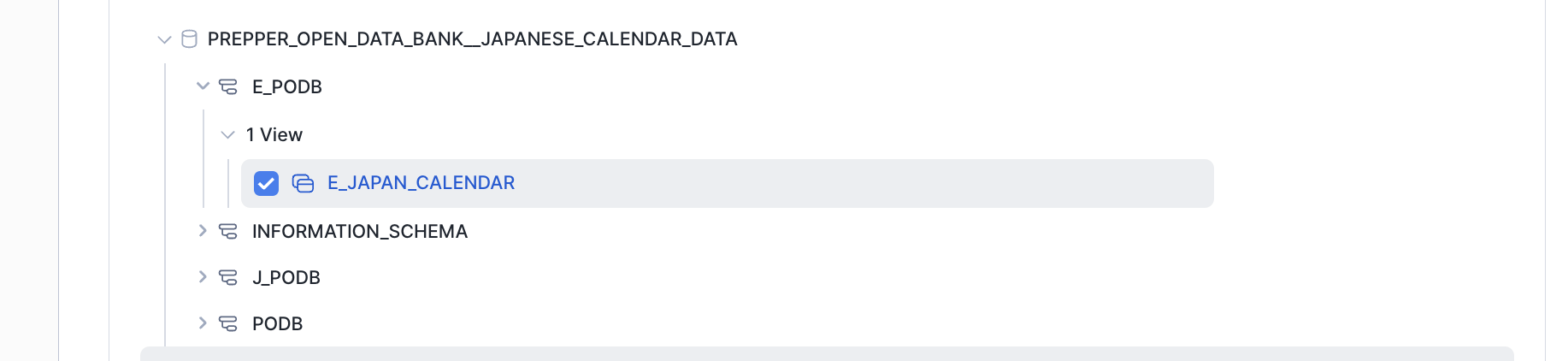
自社の売り上げデータを選択しましょう。

Select Columnsは全部選べばOKです。
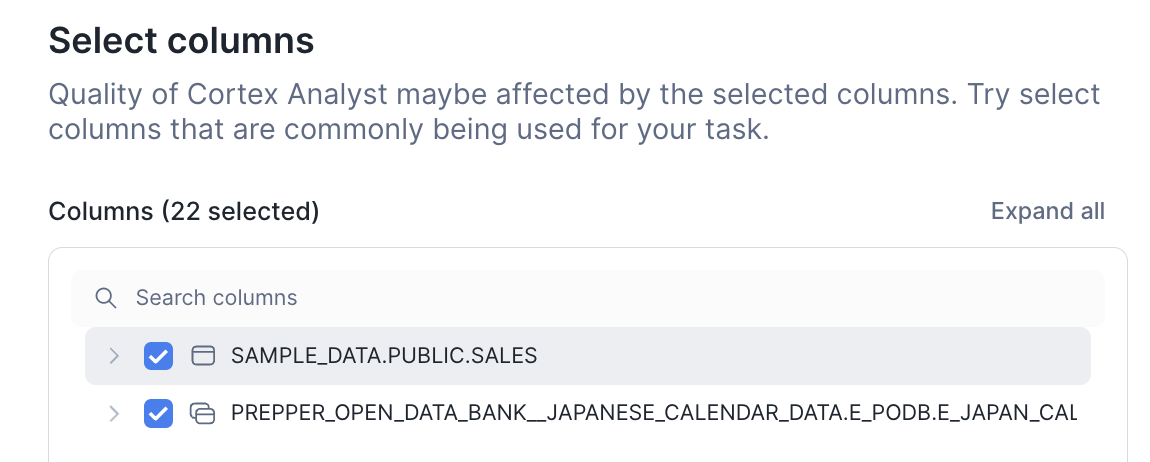
Create and saveを押すとSemantic Viewの編集画面が表示されます。
まずは真ん中くらいにある「Edit YAML」というボタンを押します。こうするとSemantic ViewをYAML形式で編集できます。
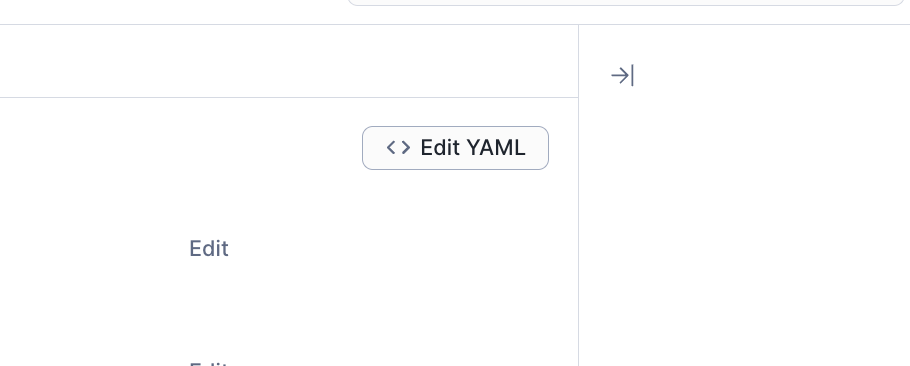
ここからがちょっと難しいのですが、
tables: 以下にある- name: E_JAPAN_CALENDARを先ほどダウンロードしたYAMLに書き換えてください。ダウンロードしたYAMLの- name: E_JAPAN_CALENDARからverified_queries:の前の行までをコピーし、編集画面にある- name: SALESの上の行までを置き換える形になります。
これでカレンダーのテーブルについては弊社が用意した定義を扱うことができるようになりました。
次に自社のデータとして用意したデータの定義を追加していきます。ここは編集画面のEditを押して編集するのがわかりやすくて良いです。ある程度はAIが先に埋めてくれますので、楽ちんです。
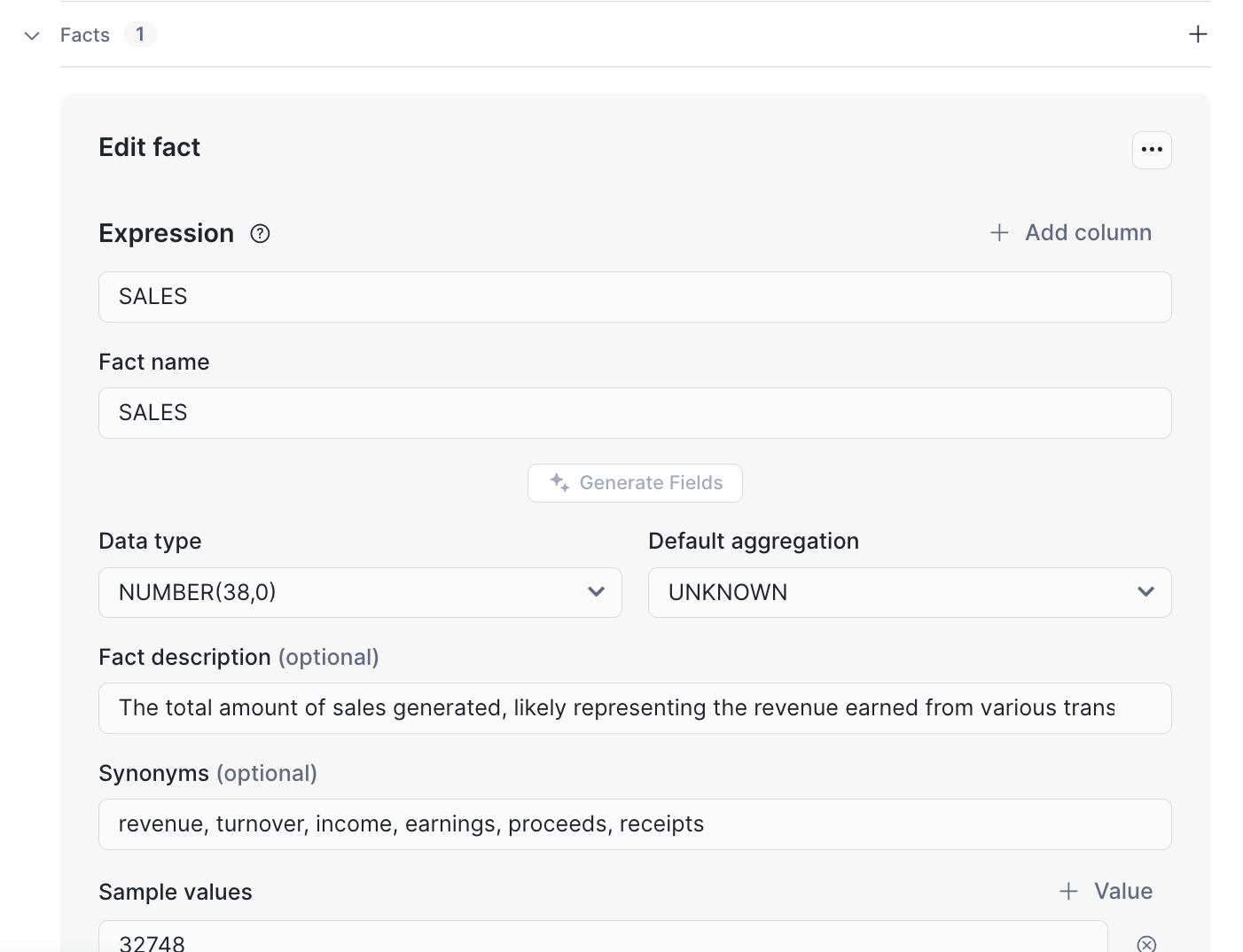
最後にこの二つのテーブルのJOINを定義します。JOINを定義するにあたりPrimary Keyを設定する必要があります。なので「Edit YAML」から各テーブルの定義のbase_table:とdimensions:の間に以下の記述ように記述を追加します。(自社のテーブルの方は各自で記述を変えてください)
– name: E_JAPAN_CALENDAR
base_table:
database: PREPPER_OPEN_DATA_BANK__JAPANESE_CALENDAR_DATA
schema: E_PODB
table: E_JAPAN_CALENDAR
primary_key:
columns:
– date
dimensions:

– name: SALES
base_table:
database: SAMPLE_DATA
schema: PUBLIC
table: SALES
primary_key:
columns:
– date
– OBSERVATORY_NAME
dimensions:

最後にrelationshipsを追加します。こちらはYAMLでも編集画面でもどちらからでも大丈夫です。
relationships:
– name: sales_calendar
left_table: sales
right_table: E_JAPAN_CALENDAR
relationship_columns:
– left_column: date
right_column: date
join_type: inner
relationship_type: many_to_one
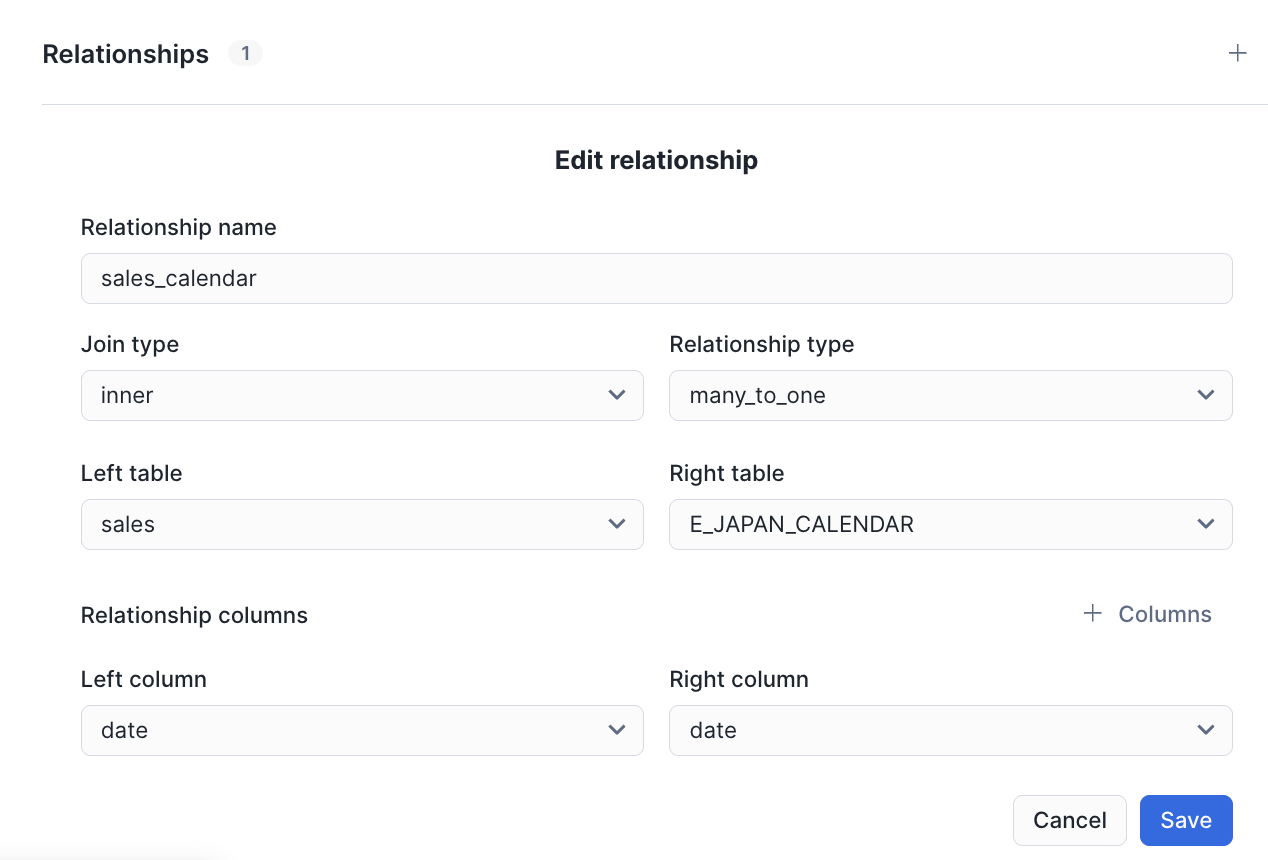
これで準備完了です。右画面で自然言語で問い合わせをしてみましょう。
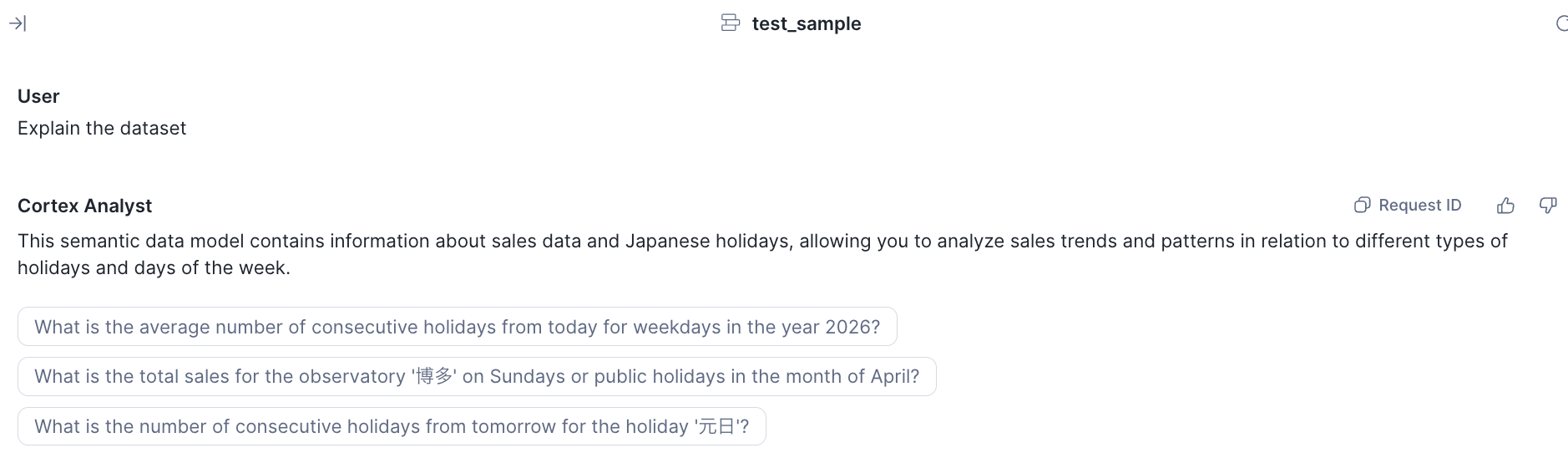
Explain the datasetを押すと、カレンダーデータと売り上げデータを含んだSemantic Viewであることがわかります。
せっかくなので博多の日曜日祝日の売り上げ情報を聞いてみましょう。
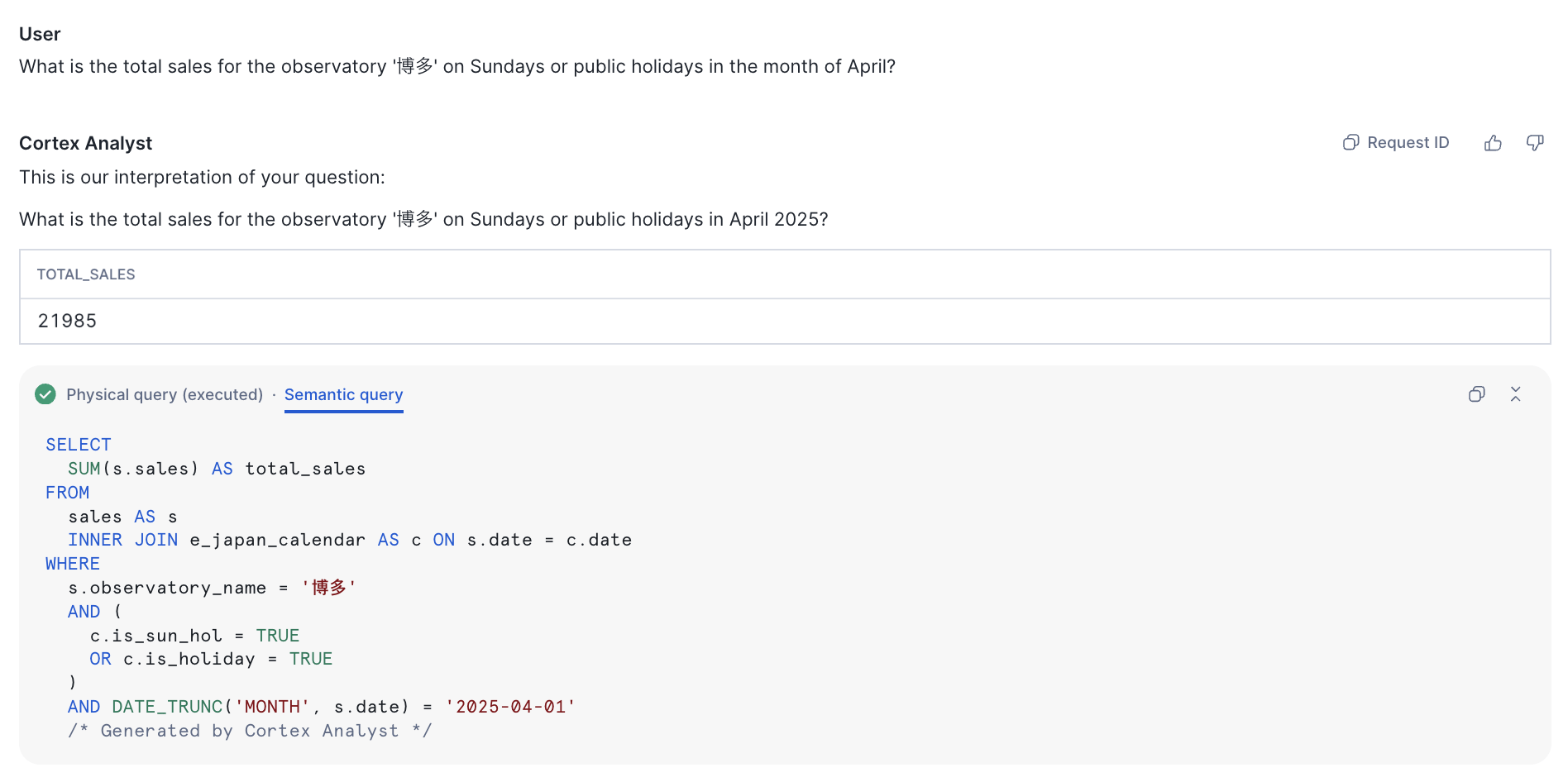
ね、簡単でしょ?
Semantic Viewの今後
現状だとやや荒削りで使いにくい印象の機能ですが、以下のYoutubeでのSnowflake Intelligenceの話で映っている画面をみると、このSemantic ViewをTableauのダッシュボードをもとに作成できたり、PDFの仕様書をもとに作成できたりなどする機能が徐々に実装されていき、使い勝手がよくなっていくと思います。
https://www.youtube.com/watch?v=va-l7sYp3OA
具体的にはこの辺りですね。
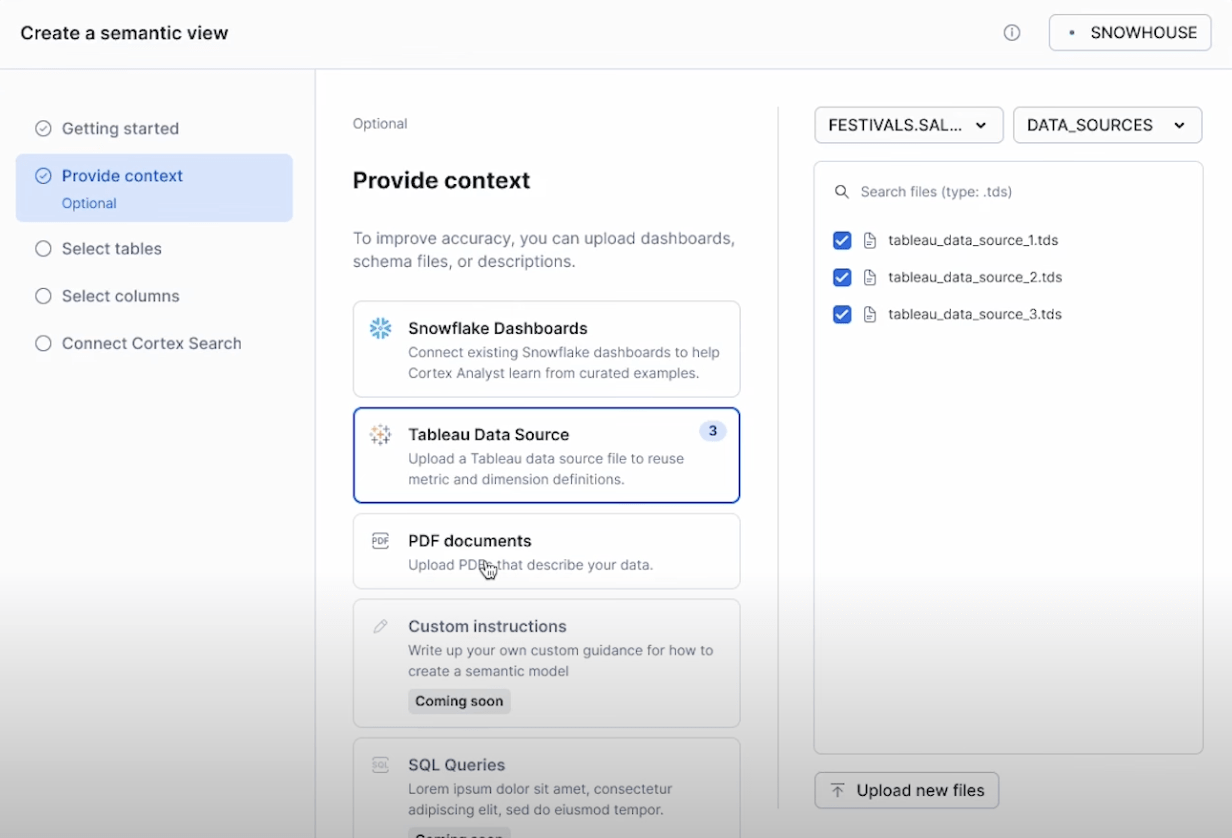
もともとは人がデータを活用するためにデータカタログとはいかずとも仕様書を作成していた方々も多いと思いますので、それらを元にAI-Readyになれるなら非常に捗りそうですね。
というわけで、今後の発展にも期待できる素敵な機能だと思います。ローンチパートナーになれて非常に嬉しく思います。
まとめ
以上がSnowflakeの新機能Semantic Viewの説明と使い方になります。
実際に自社のデータと合わせて使うのは少し手間が必要でしたが、多分このあたりは楽にする機能かツールが将来提供されるんじゃないかと思います。複数のSemantic Modelを読めるようにするとか、JOINを推測してくれる機能とか、そういうのがなんかこう、多分。
truestarは皆様がAI-Readyになる世界を目指してこれからも精進してまいります。
そんなわけで本日は以上です。
それじゃあ、バイバイ!