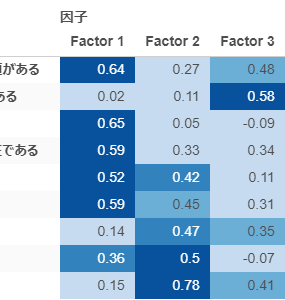
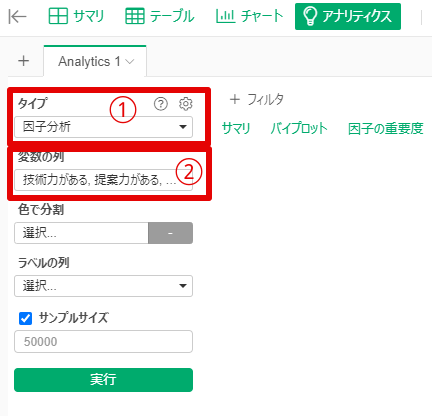
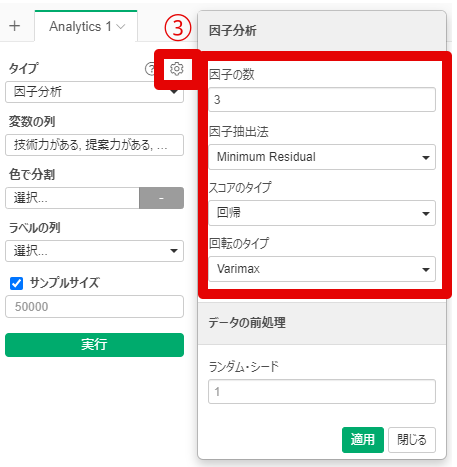
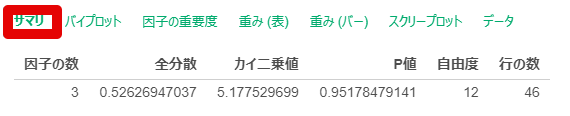
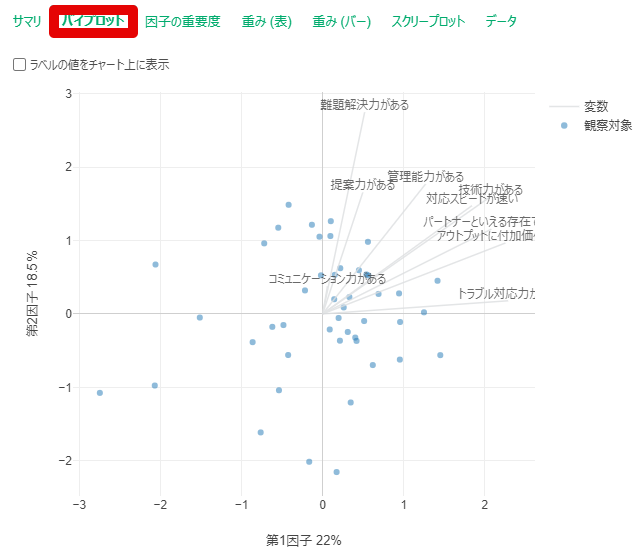
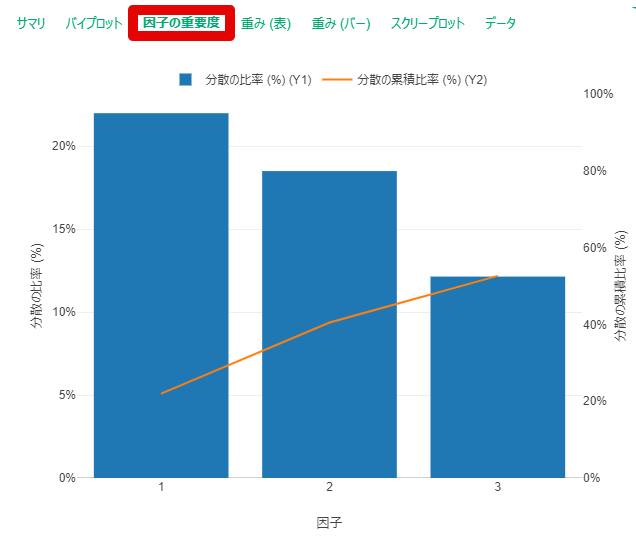
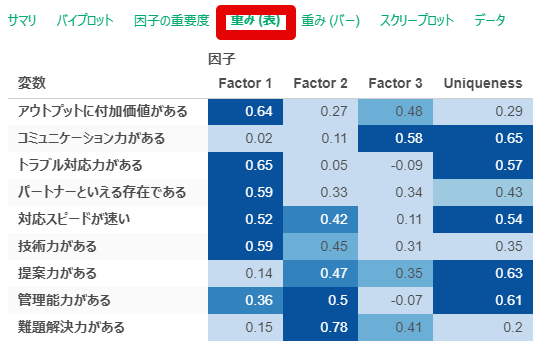
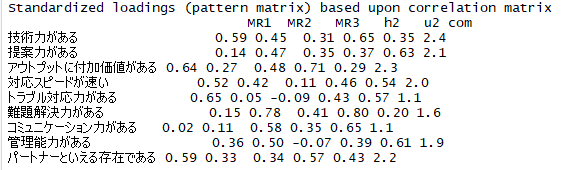
By y.saito Exploratory 2021/06/25 目次 はじめに Exploratoryでの操作方法 Rで出力した因子分析結果と比較する まとめ 【メンバー募集中】 関連する記事 はじめに こんにちは。truestarの齋藤です。本日は最近公開されたExploratory version 6.6で実装された因子分析を試してみましたので、その方法と結果をご紹介したいと思います。 実はこの因子分析の機能は私から以前Exploratoryさんに機能追加リクエストさせていただいたものでして、ちょうど今回追加いただいきとてもうれしく思っています! ユーザーのリクエストを反映してどんどん進化するExploratoryもすごいですね! また今回扱うデータについては以下の弊社ブログでもご紹介させていただいたNPS調査データ(データはダミーです)を使用しました。 NPSを使ってクライアントサービスを向上させる! Exploratoryでの操作方法 データフレームを読み込んでから、以下のとおりアナリティクスビューから①「タイプ」で因子分析を選択し、②「変数の列」で因子分析にかける変数を選択します。 そののち、以下の③歯車マークをクリックして設定を確認します。 デフォルトのまま分析を回してもよいですが、因子の数(デフォルトは2)、因子抽出法(デフォルトはMinimum Residual : 最小残差法)、回転のタイプ(デフォルトはVarimax)を指定することができます。 今回は因子数は3つ、その他はデフォルトのまま実行してみます。 結果が出ました。とても簡単ですね! 以下のとおり、サマリ情報、バイプロット、因子の重要度、重み(因子負荷量)などが出力されます。 Rで出力した因子分析結果と比較する 試しにRによる出力結果と比較してみましょう。 今回はpsychパッケージのfa()という関数を使って実施してみます。 コードは以下のとおりです。 result <- fa(dataframe, nfactor = 3, fm = "minres", rotate= "varimax", use = "pairwise")print(result, digits = 2) resultに結果を代入しています。まず対象のdataframeを指定し、nfactorで因子数を指定、fmで因子抽出法を指定(minresが最小残差法)、rotateで回転方法を指定します。printで出力してみます。 以下が因子負荷量の結果ですが、上記Exploratoryの結果と変数の並び順は違いますが、同じ数値が出力されていることが分かります。 Exploratoryは裏側ではすべてRで作られているとのことなので、この関数によって算出されているのでしょうか…。Exploratoryではコードを書かずにGUIで操作できるので非常に便利ですね! まとめ truestarでは消費者調査データを使用して、因子分析ののちにクラスター分析を行い、消費者クラスタリングを行うプロジェクトもよく手掛けています。今後クラスター分析などほかの手法についてもこちらのブログでご紹介できたらと思っています。 またtruestarではデータ活用に関する様々な業務を承っております。是非こちらからご相談ください。 【メンバー募集中】 truestarでは、新しい仲間を募集しています。詳細は以下をご覧ください。株式会社truestar採用サイト https://en-gage.net/truestar/ 関連する記事 Exploratory v6.5で「時系列クラスタリング」がバージョンアップ! 多重共線性を排除せよ Linux初心者がExploratory Collaboration Serverのバージョンアップをやってみた Exploratory Collaboration ServerのSSL証明書の更新をしてみた AnalyticsExploratory y.saito / About Author More posts by y.saito ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。