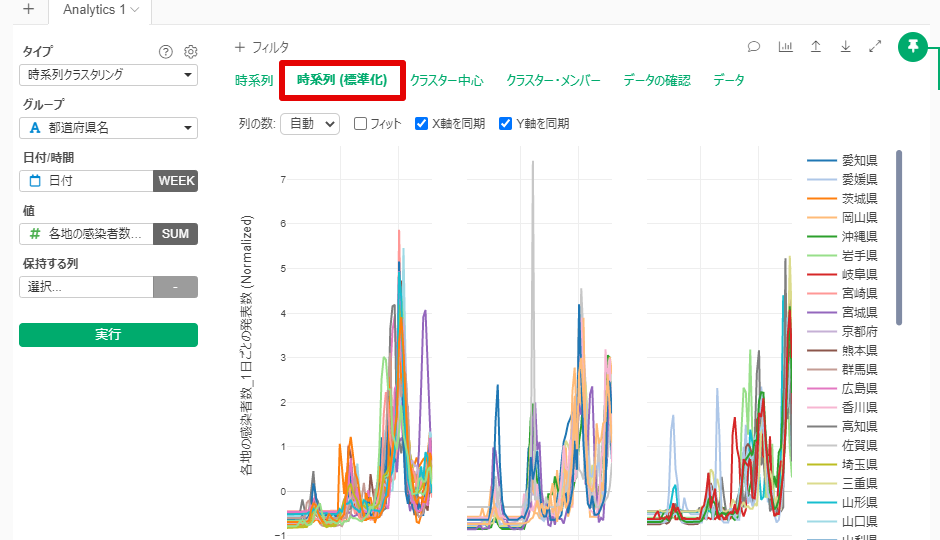
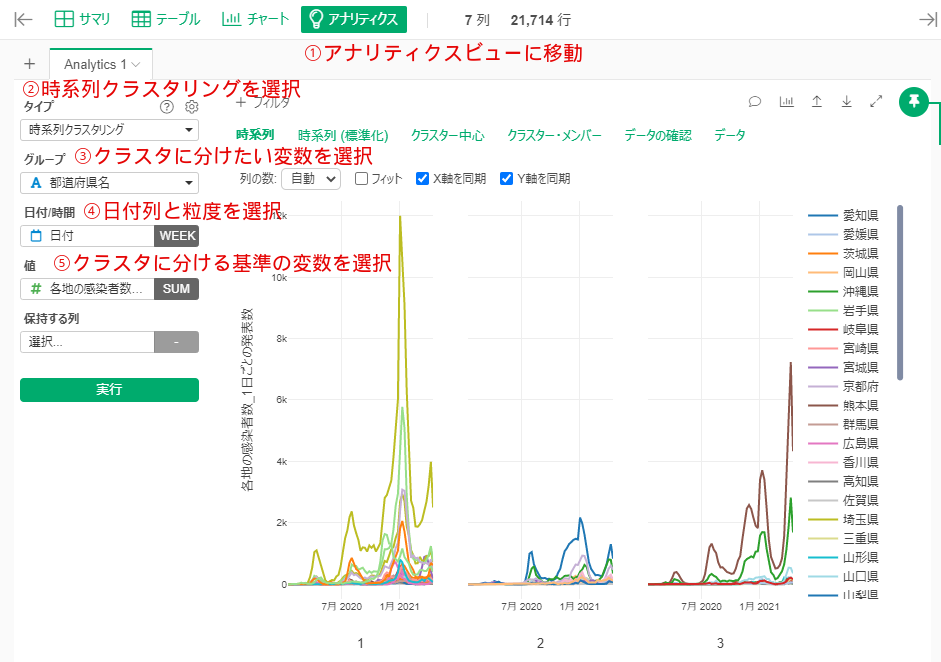
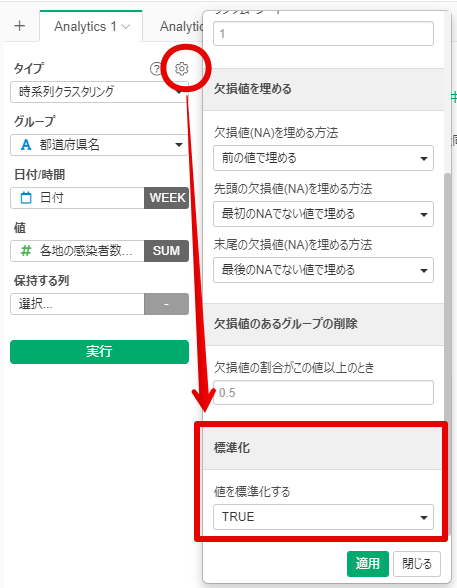
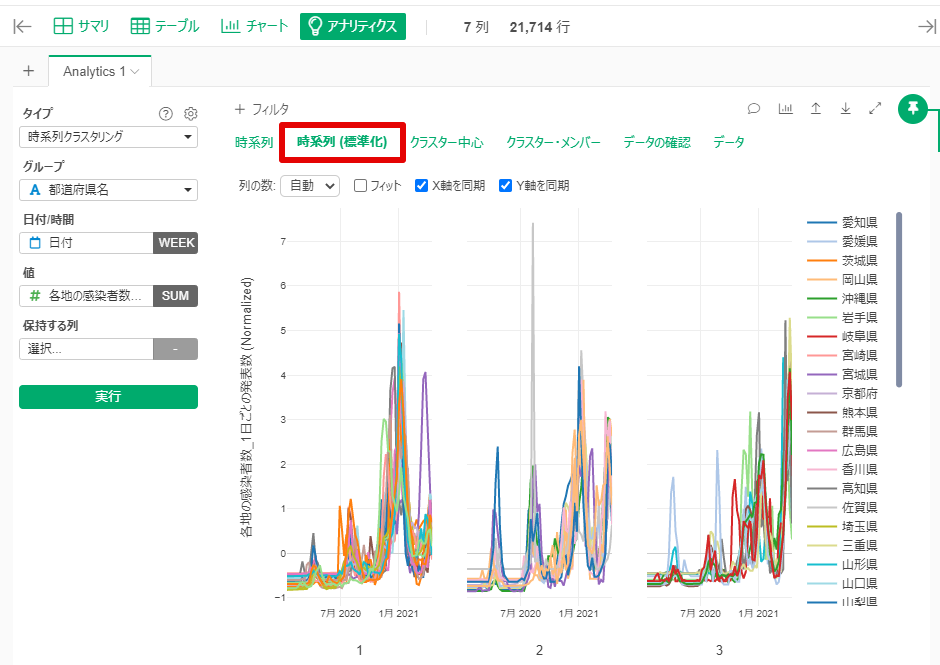
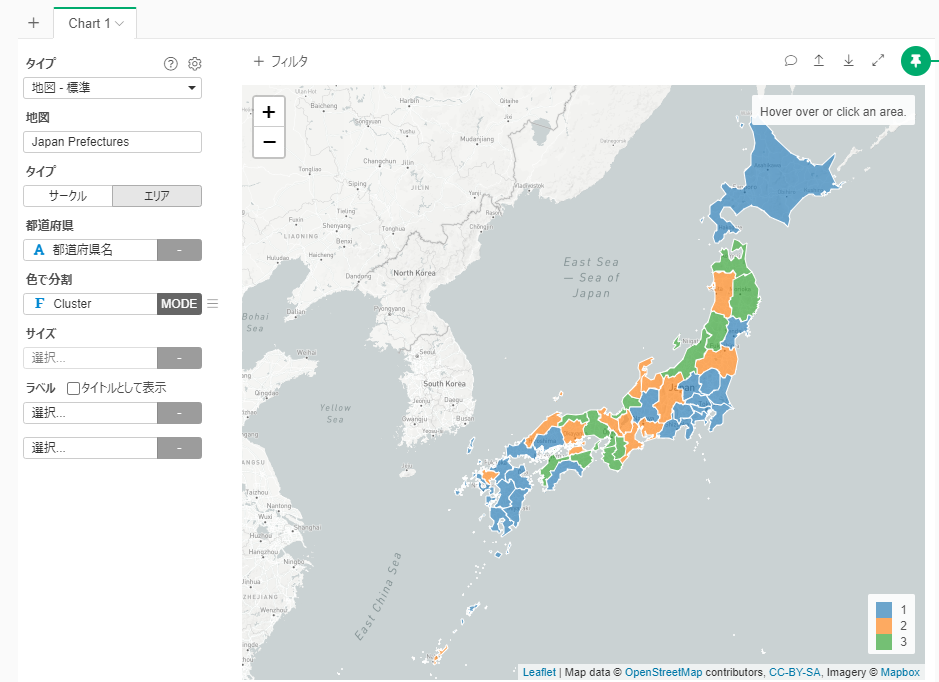
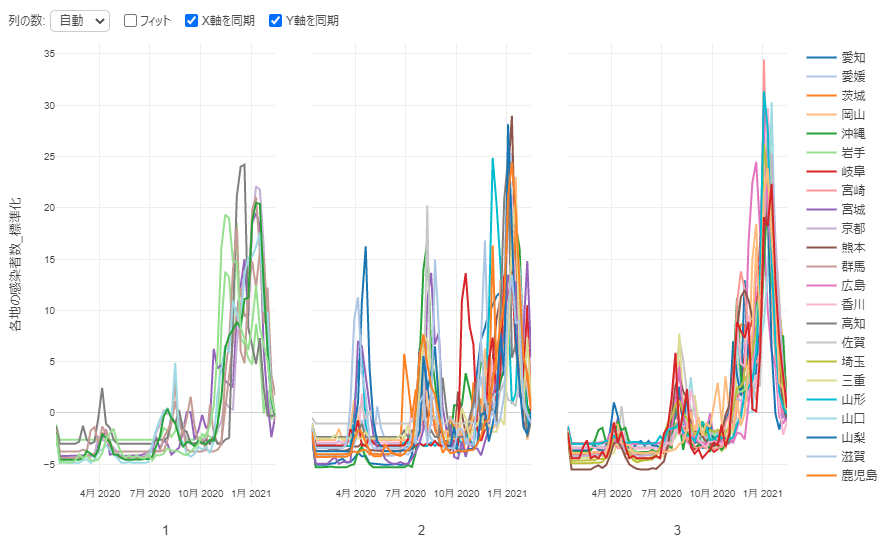
By Tableau-id Press編集部 Exploratory 2021/04/23 目次 はじめに 使用したデータ : 前回同様に都道府県別新型コロナ感染者数 アップデートされた時系列クラスタリングの実施方法 なんと自動で標準化してくれる! 地図で結果を確認 これからも毎週Exploratoryを紹介していきます 関連する記事 はじめに こんにちは。truestar齋藤です。 truestarブログでは毎週にわたってExploratoryの紹介をさせていただいています。今日は最近公開されたExploratory v6.5においてバージョンアップした時系列クラスタリングをご紹介します。 時系列クラスタリングを含むv6.5の新機能の詳細については、先日行われたExploratoryのデータサイエンス勉強会で紹介されていますので以下のサイトも参考にしてください。 https://exploratory.io/meetup-jp また時系列クラスタリングについては、つい2ヶ月ほど前に公開されたv6.4で実装されたばかりでして、以前以下の記事でご紹介させていただきました。今回はより時系列クラスタリングがやりやすくバージョンアップされていますので、その方法についてご紹介したいと思います。 Exploratory v6.4の新機能「時系列クラスタリング」を試してみた 使用したデータ : 前回同様に都道府県別新型コロナ感染者数 前回のブログ記事と同様に、NHKが提供している都道府県別新型コロナ感染者数データを使用しました。 https://www3.nhk.or.jp/news/special/coronavirus/data-widget/ アップデートされた時系列クラスタリングの実施方法 以前はラングリングで時系列クラスタリングを実施する必要がありましたが、今回のv6.5ではより簡単にアナリティクスビューから実施できるようになっています。 設定は前回と同様に、グループは都道府県名、日付は週の粒度、感染者数を値の列で選択し、あとはデフォルトの設定のまま実行すると結果が算出されます。 なんと自動で標準化してくれる! 今回のバージョンアップで私が感動したのは、自動で値を標準化してくれる機能です! 以前の記事で実行した際には、そのままのデータで時系列クラスタリングを行うと値の大きさによってクラスタリングされるため、時系列の動きの傾向でクラスタリングしたい場合は事前に値の標準化を行う必要がありました。 今回はその必要がなく、デフォルトの設定で値を標準化してくれます。以下が設定の箇所となります。 またアナリティクスビューで以下の「時系列(標準化)」をクリックすると、標準化された値でチャートを見ることができます。これによると以下のように分けられていることが分かりやすく見えると思います。 クラスター1:第1派~第3派まで増えてきているが、第4派はまだ第3派ほど大きくなっていない都道府県 クラスター2:第1派~第3派の差がそれほど大きくない都道府県 クラスター3:第4派が最も大きくなっている都道府県 地図で結果を確認 前回と同様に地図でも結果を確認しました。データを新しいデータフレームとしてエクスポートし、チャートから地図を作成します。 クラスター1は関東や九州、クラスター3は大阪を中心とした近畿エリアが多いことが分かりますね。 これからも毎週Exploratoryを紹介していきます これからも毎週 #Exploratory について紹介していきますのでお楽しみに! ※分析にまつわるお困りごとも、いつでもご相談お待ちしています。 関連する記事 Exploratory v6.4の新機能「時系列クラスタリング」を試してみた Exploratory ノート機能でレポート作成! Exploratory Collaboration Server ログ監視・確認 Multicollinearity Diagnostics in Exploratory AnalyticsExploratory Tableau-id Press編集部 / About Author More posts by Tableau-id Press編集部 ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。