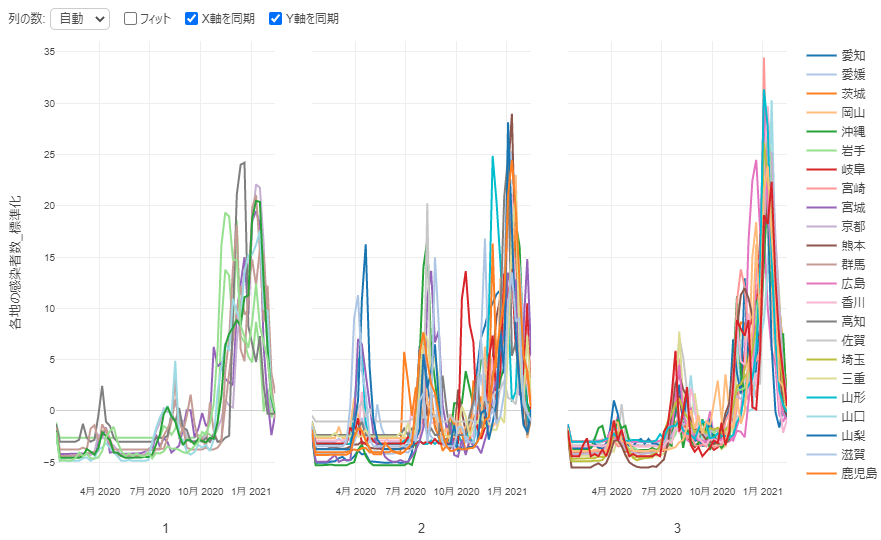
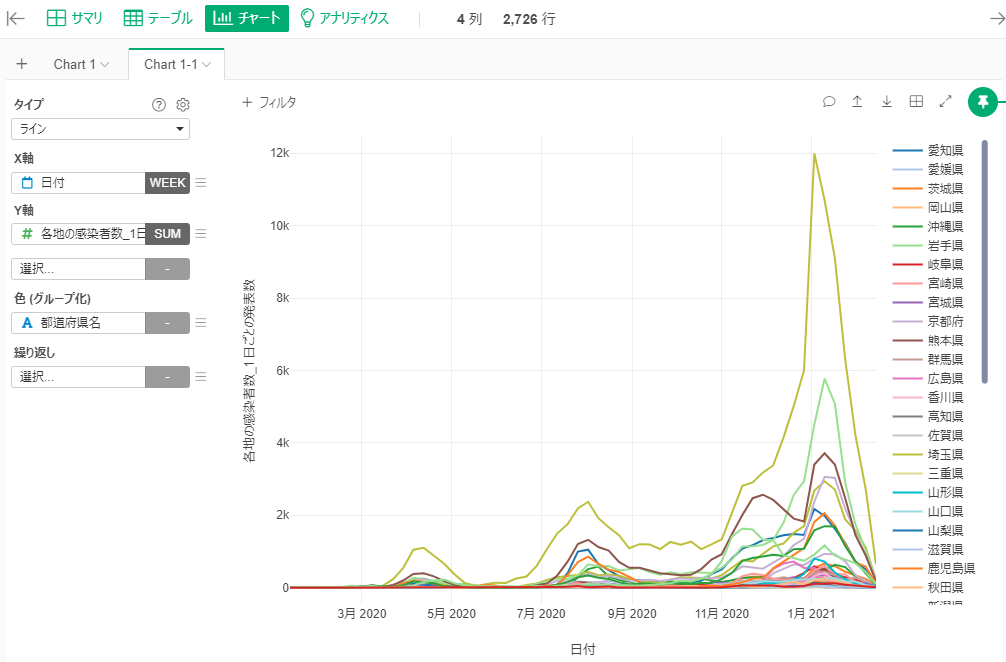
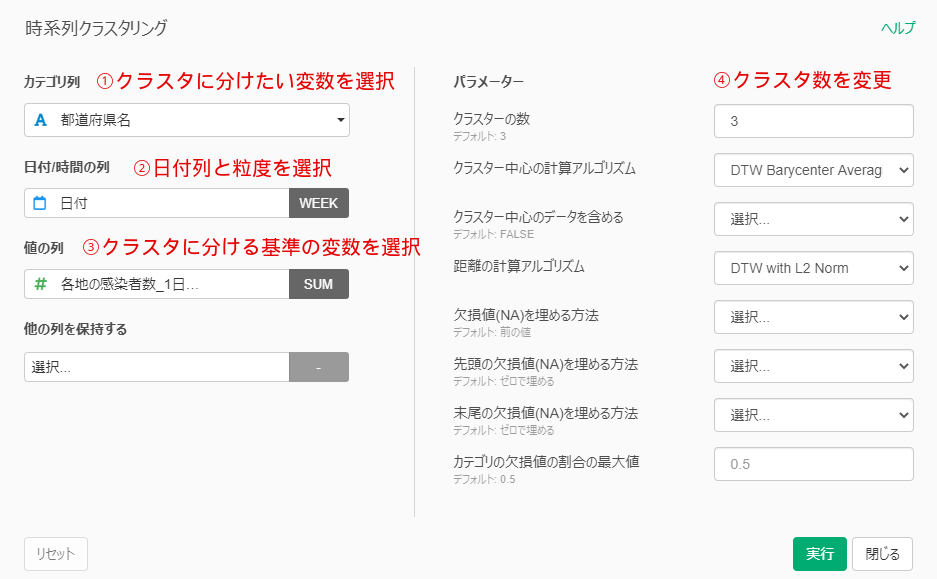
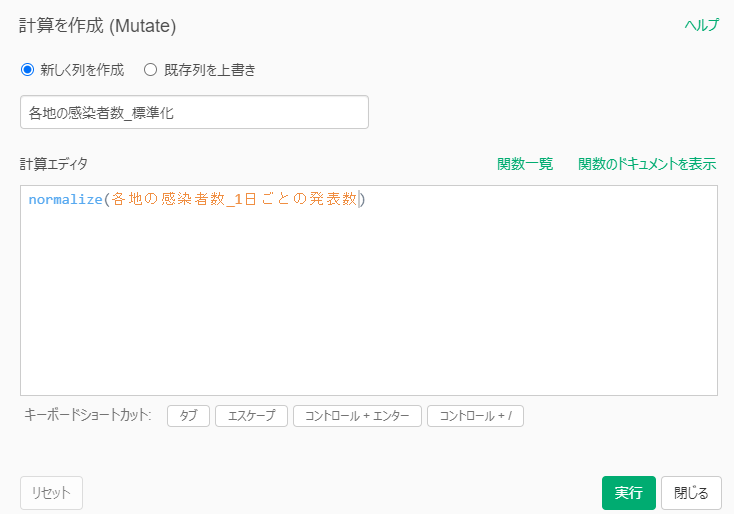
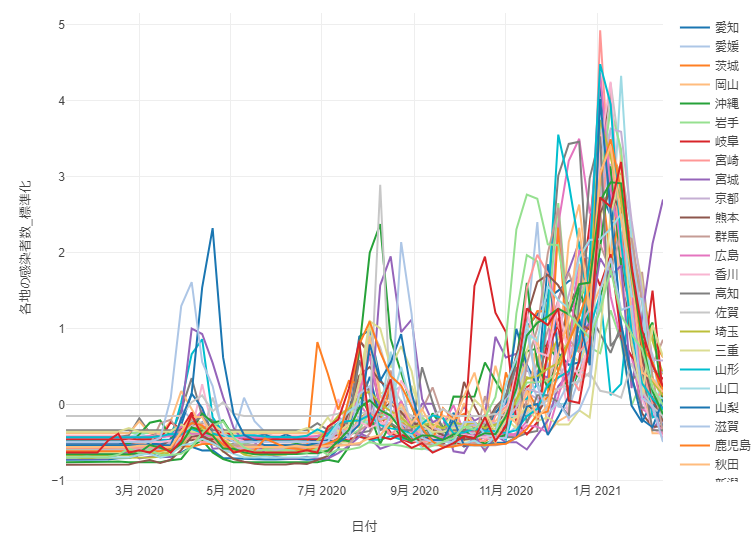
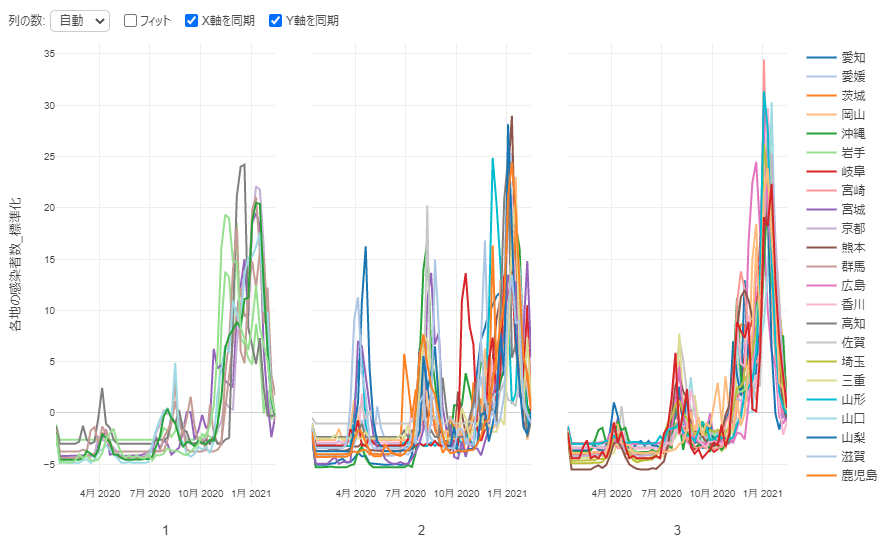
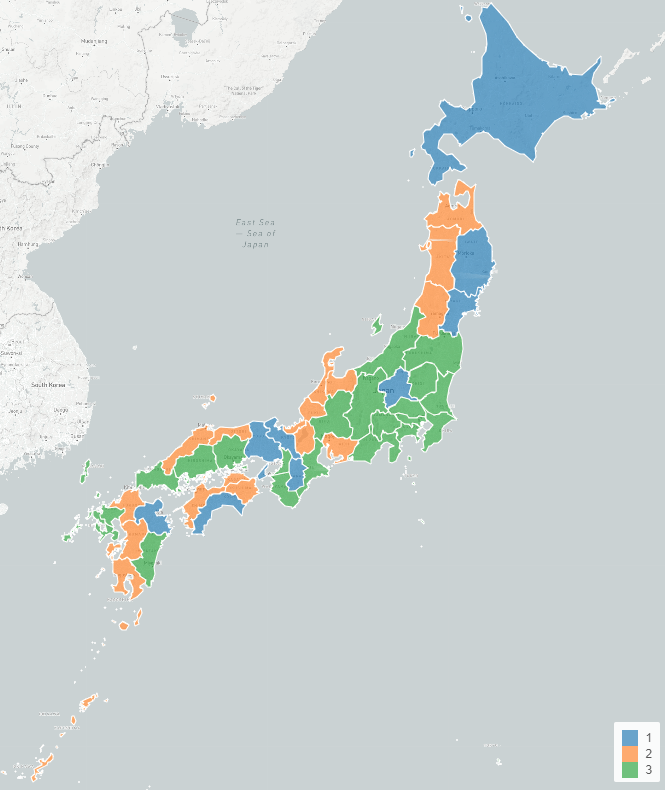
By Tableau-id Press編集部 Exploratory 2021/02/17 目次 2021年7月2日追記 使用したデータ : 都道府県別新型コロナ感染者数 とりあえず時系列クラスタリングをやってみた できた! けどちょっと結果が微妙… 標準化してからクラスタリングしてみる うまくクラスタに分かれてくれた! これからも毎週Exploratoryを紹介していきます 関連する記事 こんにちは。truestar齋藤です。 truestarブログでは先週より毎週Exploratoryの紹介をさせていただく企画を実施中です。今日は最近公開されたExploratory v6.4の新機能である「時系列クラスタリング」を試してみた結果をご紹介します。 時系列クラスタリングを含むv6.4の新機能の詳細については、先日行われたExploratoryの勉強会で紹介されていましたので、以下のサイトも参考にしてください。 https://exploratory.io/meetup-jp 2021年7月2日追記 この記事の作成後2021年4月にv6.5が公開され、標準化が自動ででき、かつアナリティクスビューからもできるようになりました。 詳細は以下の記事にも記載していますのでご参照ください。 Exploratory v6.5で「時系列クラスタリング」がバージョンアップ! 使用したデータ : 都道府県別新型コロナ感染者数 Exploratoryの勉強会では、アメリカの州別の新型コロナ感染者率を使用して説明が行われていたので、日本の都道府県を感染傾向でクラスターに分けてみよう!と思い、以下のNHKが提供している感染者数データを使用してみました。 https://www3.nhk.or.jp/news/special/coronavirus/data-widget/ 都道府県別、日別の感染者数のデータとなります。Exploratoryのチャートで可視化してみたのが以下ですが、昨年4月の第1派、8月ごろの第2派、直近の第3派の山が明確に分かりますね。 とりあえず時系列クラスタリングをやってみた 設定は非常に簡単です。以下が設定ウインドウですが、Exploratoryのラングリング(データ加工)の新規ステップ追加から設定画面を開くことができます。 都道府県をクラスタに分けたいのでカテゴリ列には都道府県名を選択、日付は今回は週の粒度で計算してみます。感染者数を値の列で選択し、必要であればクラスタ数を変更します。今回はデフォルトの3クラスタのまま実施しました。あとはデフォルトの設定のまま実行してみます。 できた! けどちょっと結果が微妙… すぐに結果が算出されたので、チャートでクラスターごとの傾向の違いを見てみました。 先ほど作成したチャートの繰り返しの部分でClusterという変数を選択すると、クラスタ別の傾向を分かりやすく見ることができます。 ただし…、クラスタ2は感染者数が多い都道府県(東京と神奈川)、クラスタ3が感染者数が中程度、クラスタ1は感染者数が少ない、と単に感染者数で分かれてしまいました…。 本来は時系列での感染傾向の違いを知りたかったのです。例えば第1派からすでに多い都道府県や、第3派で急に多くなった都道府県、といったように分けたいと考えていました。 標準化してからクラスタリングしてみる (2021年7月2日追記:冒頭にも追記しましたとおり、v6.5以降のバージョンでは標準化も自動で行われるようにバージョンアップされています) 都道府県の感染者数の多さ少なさの要素を抜き取って、時系列の傾向だけを抽出するために、都道府県ごとに感染者数を標準化してみました。 Exploratoryではラングリングで都道府県でグループ化したのち、計算を作成から以下のとおりnormalize関数を使って標準化を行います。 以下のとおり都道府県別の時系列の傾向のみ抽出することができました。 うまくクラスタに分かれてくれた! そして3クラスタに分けてみたところ、想定のように分かれてくれました! クラスタ1:第1派と第2派は同程度だが第3派で大きく増えている クラスタ2:第1派~第3派の大きさにあまり差がない クラスタ3:第1派~第3派でどんどん増えている Exploratoryでは簡単に地図で示すこともできます。地図を見ながらですと解釈しやすいですね。ただし今回はあまり地域性の傾向ははっきり見えないようです。 時間の都合で本日はここまでとなりますが、他の変数も入れて分析してみるのも面白そうですね。 これからも毎週Exploratoryを紹介していきます 今日はExploratoryの新機能、時系列クラスタリングの紹介をさせていただきました。 毎週Exploratoryの様々な機能について紹介していきますのでお楽しみに! 関連する記事 Exploratory v6.5で「時系列クラスタリング」がバージョンアップ! Exploratory Collaboration Server ログ監視・確認 Exploratory Collaboration ServerのSSL証明書の更新をしてみた Exploratory ノート機能でレポート作成! Tableau-id Press編集部 / About Author More posts by Tableau-id Press編集部 ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。