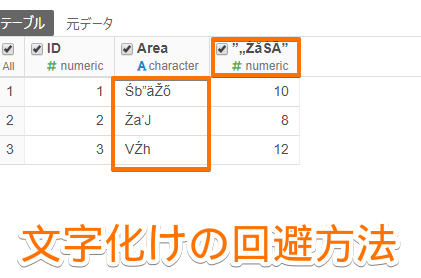
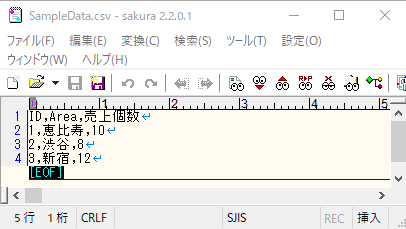
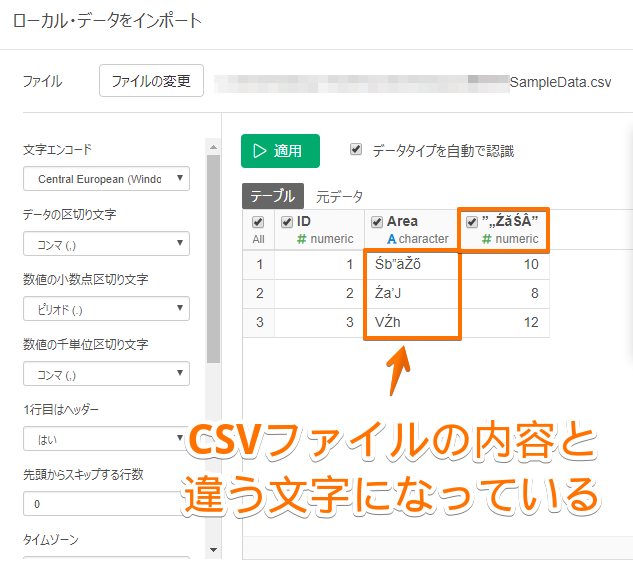
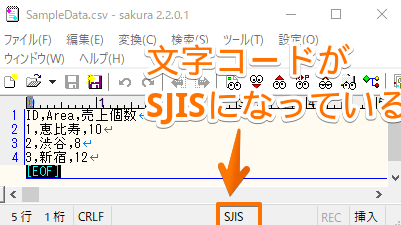
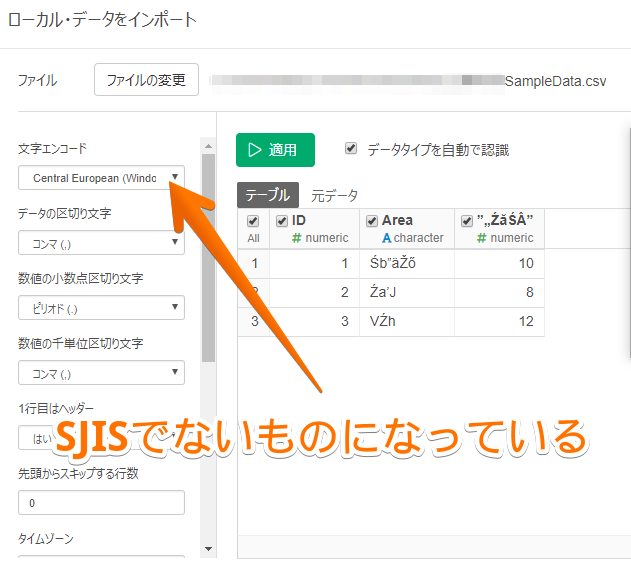
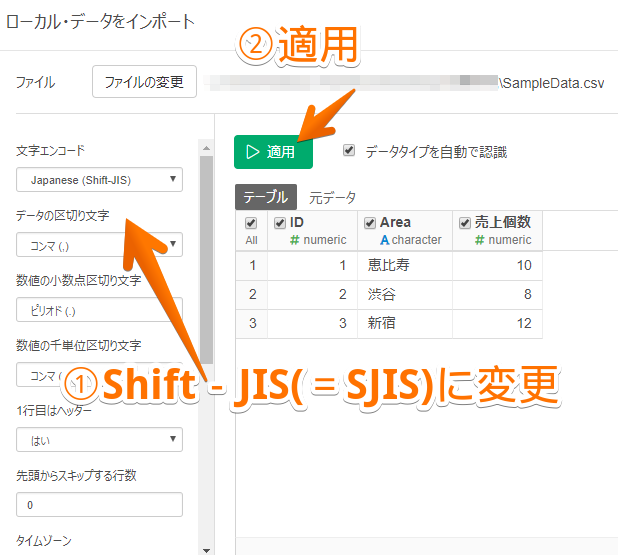
By Tableau-id Press編集部 Exploratory その他 2020/09/18 目次 関連する記事 はじめまして、truestarの吉村と申します。 私は社内ではシステム系の仕事に携わることが多いため、システムの経験や知見を活かした情報発信が出来ればと考えています。 今回は、Exploratoryで文字化けが起きた時の回避策と原因に関して紹介します 1.現象 データ(以下の例はCSVファイル)を、Exploratoryに読み込ませるとおかしい状態になってしまいました。 2.原因 文字コード(文字エンコード)が、CSVファイルとExploratoryで異なっていることが原因です。今回の例では、CSVファイルは「SJIS」という設定になっています。一方、Exploratoryは違う設定になっているので、文字化けが起きてしまっています。 3.回避策 文字コード(文字エンコード)を統一する事で回避可能です。 この場合は、CSVファイルがSJISなので、Exploratoryの設定をCSVファイルと同じ設定にすることで修正できます。 4.文字コード(文字エンコード)とは? 物凄いザックリとした言い方をすると、文字を表現するルールです。 そもそもPC上で文字(例えば「あ」)を入力した場合、PCの内部的には番号に変換して管理・記憶します。 この「文字」と「番号」の対応方法のルールが文字コードになります。 ルールが変わると、同じ文字でもPC上で扱う番号が全く別物になります。 ある文字コード(ルール)で変換した「番号」を、別の文字コード(ルール)で変換すると文字がおかしくなってしまいます。 これが文字化けが起きてしまうメカニズムの1つです。 (ちなみに「半角英数字と半角記号」は多くのルール間で統一されています。 そのため、上記の例でも文字化けしていません。) このような文字コードに由来する文字化けはExploratory以外のツールでも発生する可能性があります。 ただし、多くの場合はツール側で上手く解釈してくれるのでユーザが気にする機会は少ないです。 しかし、今回のように明示的に気にしないといけないケースもあるのでご注意ください。 関連する記事 リモートミーティングの心得 Tableauで更新前と更新後のシート画像をキャプチャーして比較する 【おすすめの書籍】『AI・データ分析プロジェクトのすべて―ビジネス×技術力=価値創出―』 Tableau-id Press編集部 / About Author More posts by Tableau-id Press編集部 ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。