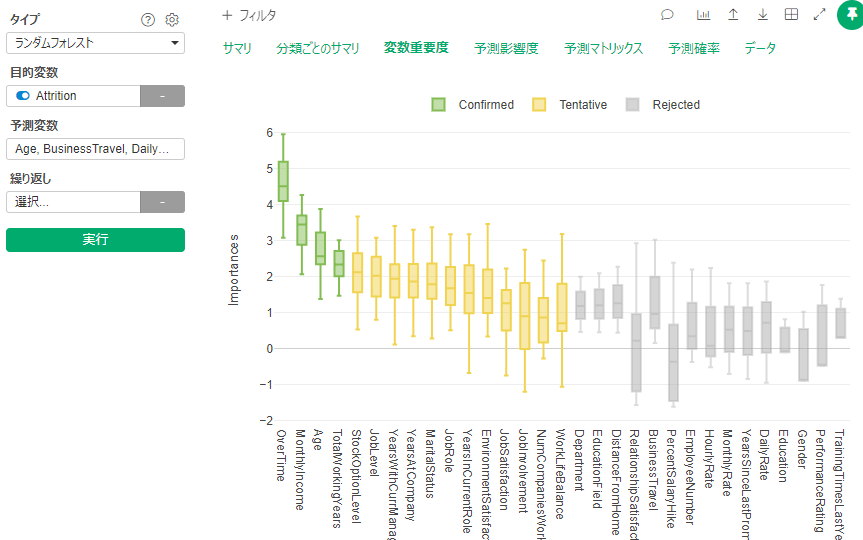
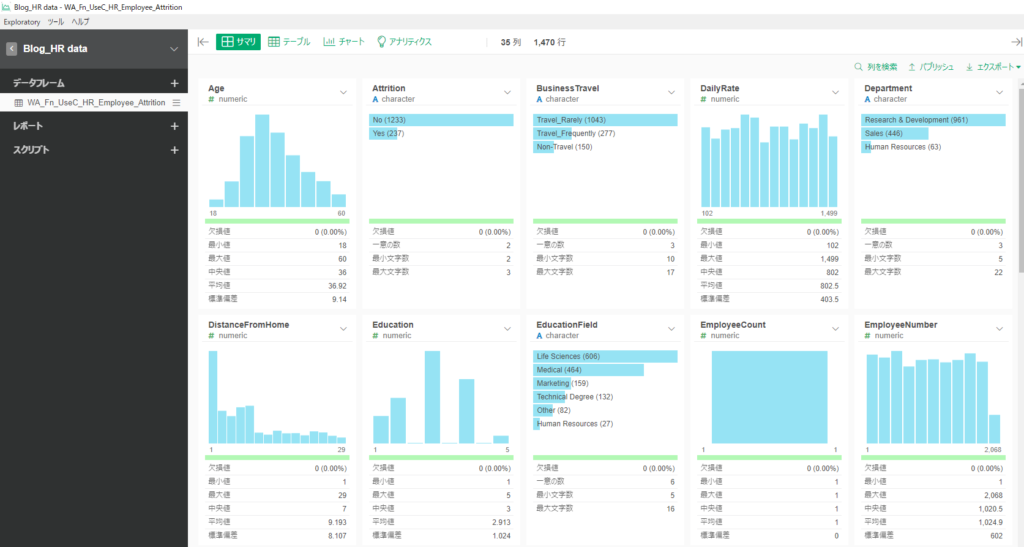
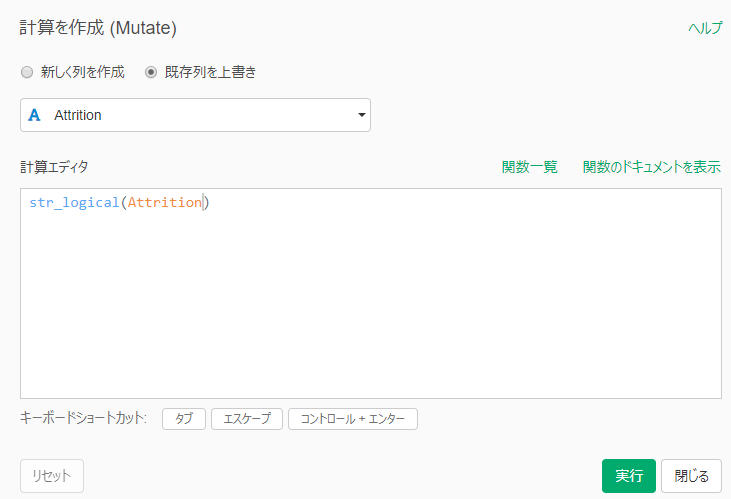
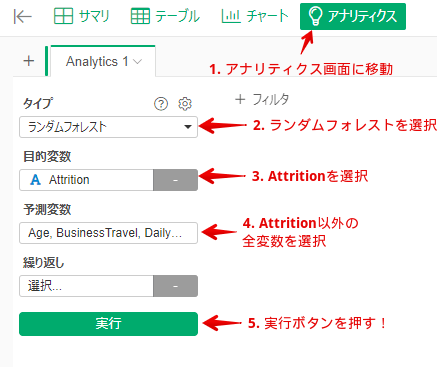
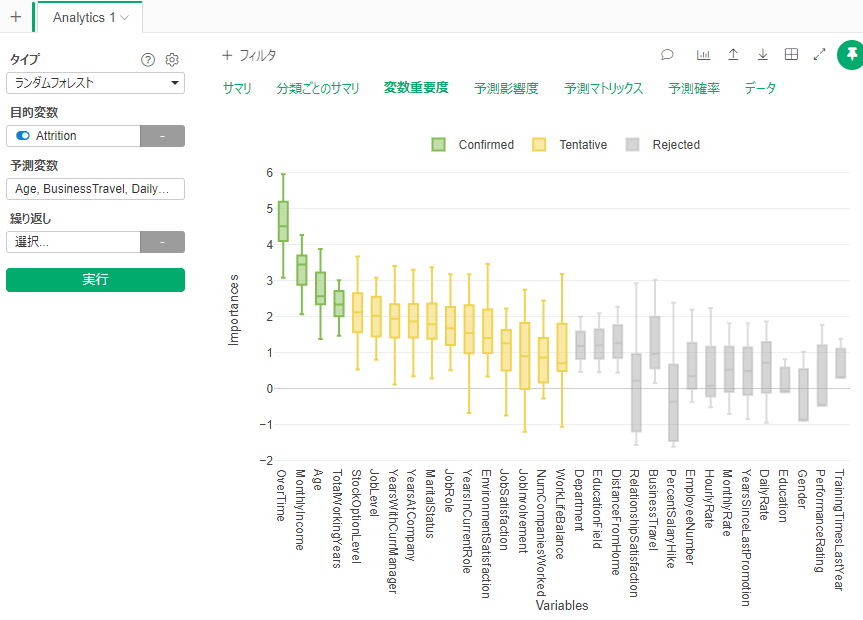
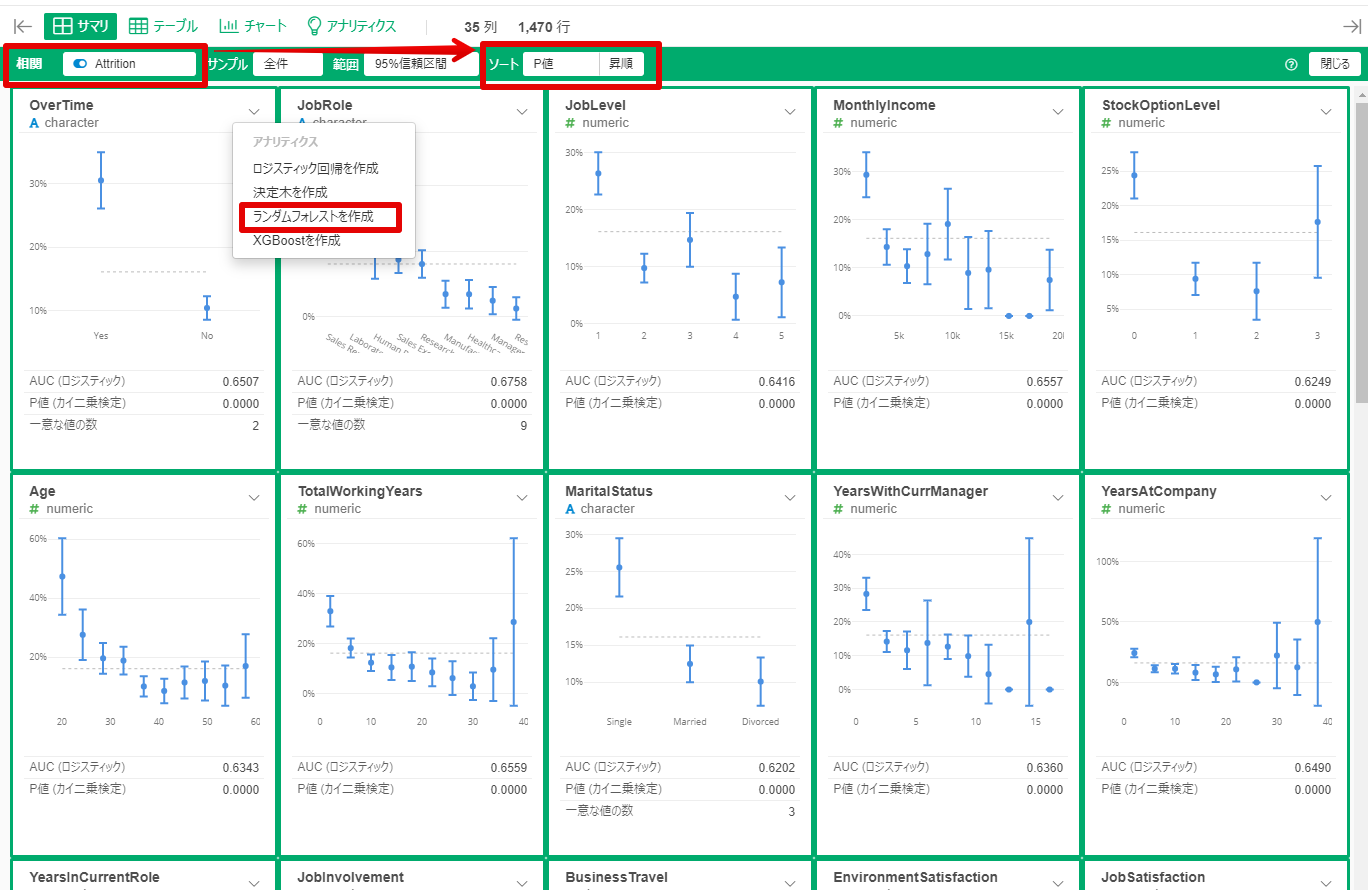
By Tableau-id Press編集部 Exploratory 2020/01/06 目次 Exploratoryって何? 何が便利なの? どうやって使うの? さいごに 関連する記事 こんにちは。truestar齋藤です。 今回は弊社内で最近使い始めた新しいツール「Exploratory」を紹介します。 Exploratoryって何? データ接続・加工 データ分析・統計解析・機械学習 可視化 がExploratoryひとつで完結でき、かつプログラミング知識なしで使うことができるツールです。 詳細は以下のExploratoryのサイトをご確認ください。 https://exploratory.io/ 開発した会社はシリコンバレーにベースを置いていますが、なんと開発者は全員日本人!とのことです。 何が便利なの? データ加工・データ分析・可視化のそれぞれが得意なツールは多くありますが、統計解析・機械学習も含めてひとつのツールで完結できる、という点がまずひとつ。 弊社truestarで使っている最も大きな理由は、統計解析や機械学習が非常に簡単にできるからです。 どうやって使うの? 今回は簡単に使い方をご紹介しましょう。 例として、KaggleがOpen Databaseとして公開している以下の「従業員の離職(Attrition)についてのフィクションデータ」を使用します。 https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset/data このデータを使って、離職に影響する要因を調べてみましょう。 ダウンロードしたデータを読み込むと、以下のようなデータのサマリ画面を表示することができます。各データ項目の内容がひと目で分かるので便利ですね。 次にランダムフォレスト(機械学習アルゴリズム)によって、離職(Attrition)に影響する要素は何かを探ってみましょう。 ランダムフォレストって何?という方は、今回は「ある要素に影響する項目を探し出す機械学習アルゴリズム」と考えて下さい。 詳しく知りたい方は、Exploratoryさんの以下の紹介スライドが分かりやすいです。 https://speakerdeck.com/kanaugust/exploratory-randamuhuoresutofalseshao-jie 次に、離職(Attrition)のデータ型がカテゴリカルになっているため、ランダムフォレストで認識できるようにロジカル型に変更します。 計算エディタに数式が表示されていますが、「データタイプを変換する」というメニューを選択すると自動で数式が生成されるので、あとは実行を押すだけです。 あとは以下のとおり操作するだけです。 すると以下のような結果が表示されました! 箱ひげ図?のような形が色分けされて表示されていますが、これが変数重要度を表しています。数字が高いほど影響度が高い、というわけです。 結果を見ると、Overtime(残業時間ですかね…)、Monthly Income(やっぱり…)といった要素の影響が大きそうなことが分かりました。 さいごに 今回は簡単なご紹介でしたが、今後はランダムフォレストの詳細も含めて様々な機能の紹介をしていきたいと思います! 関連する記事 Exploratoryによる便利で簡単な予測方法の紹介 Exploratoryのデータサイエンス・ブートキャンプに参加しました 予測モデルの簡単手法選択ガイド 相関係数の求め方(Excel/Alteryx/Exploratory) Tableau-id Press編集部 / About Author More posts by Tableau-id Press編集部 ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。