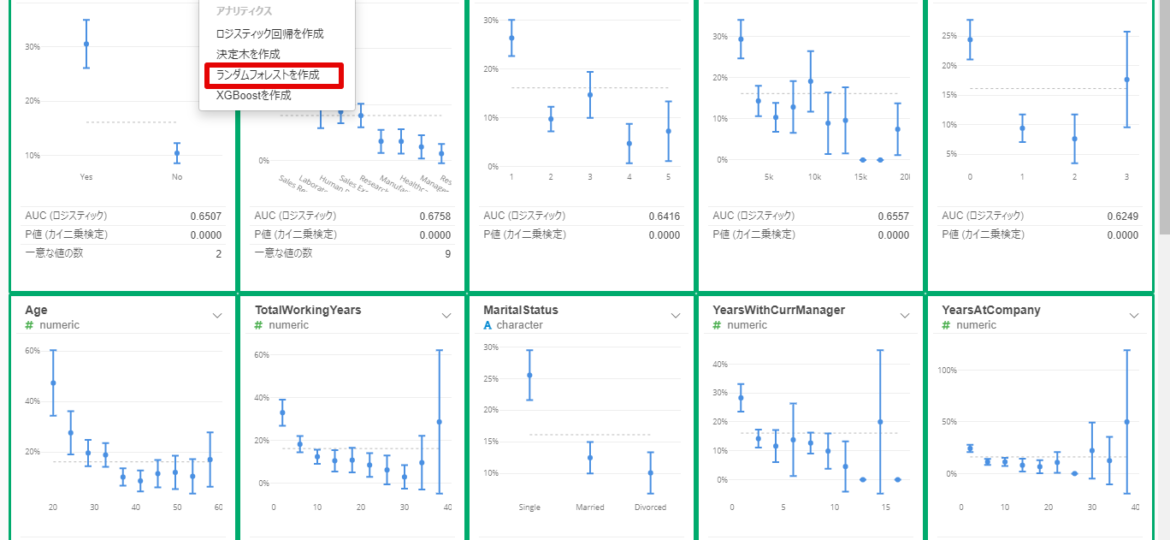
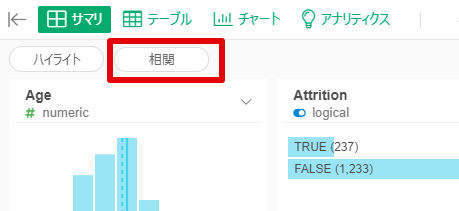
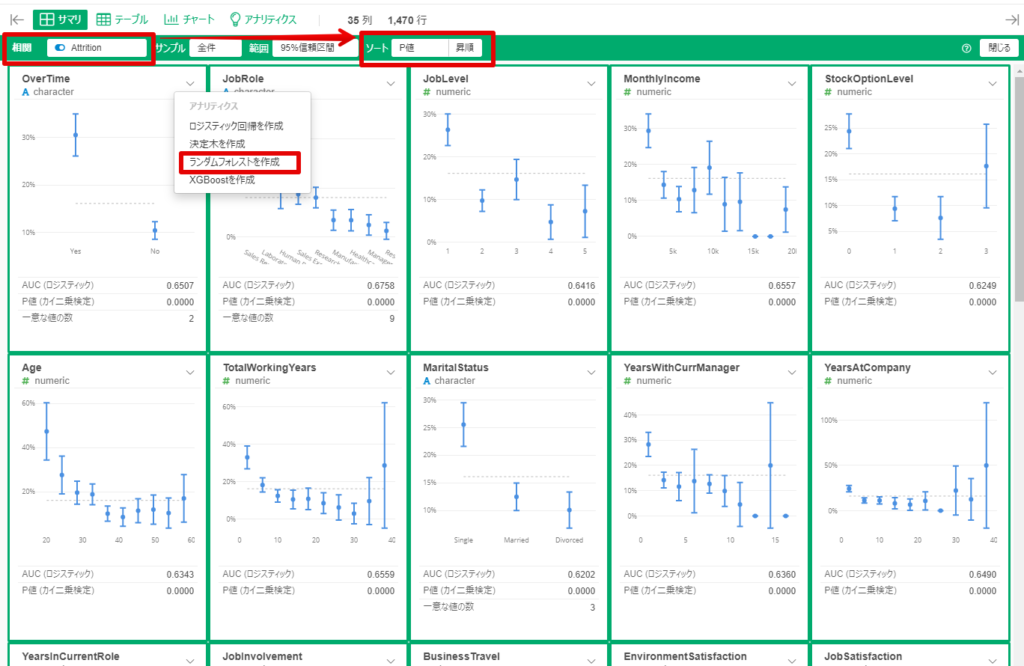
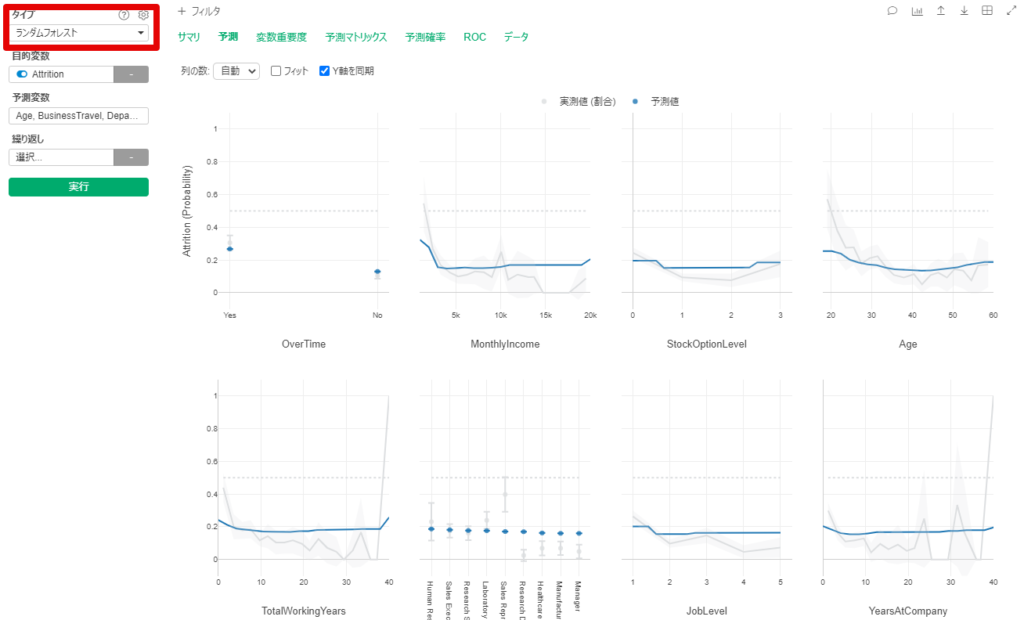
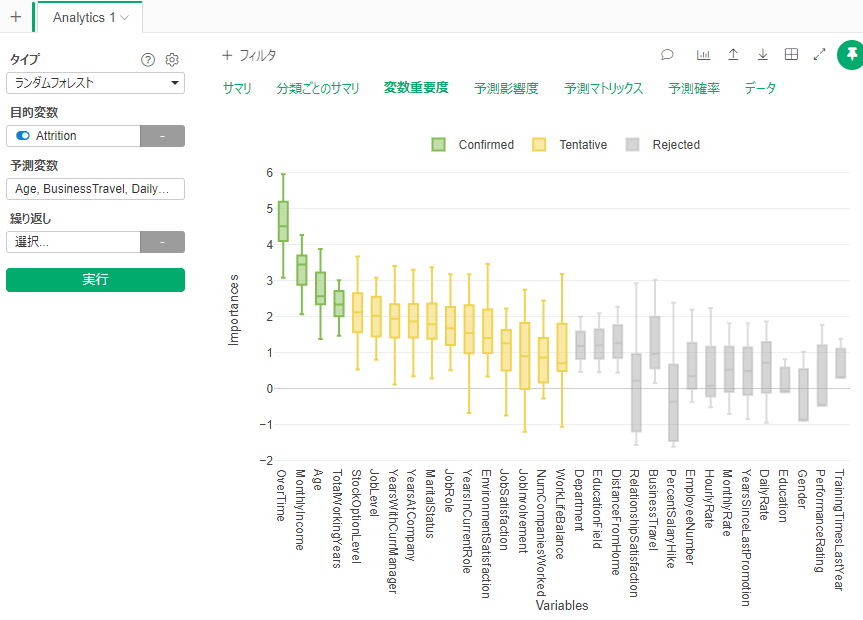
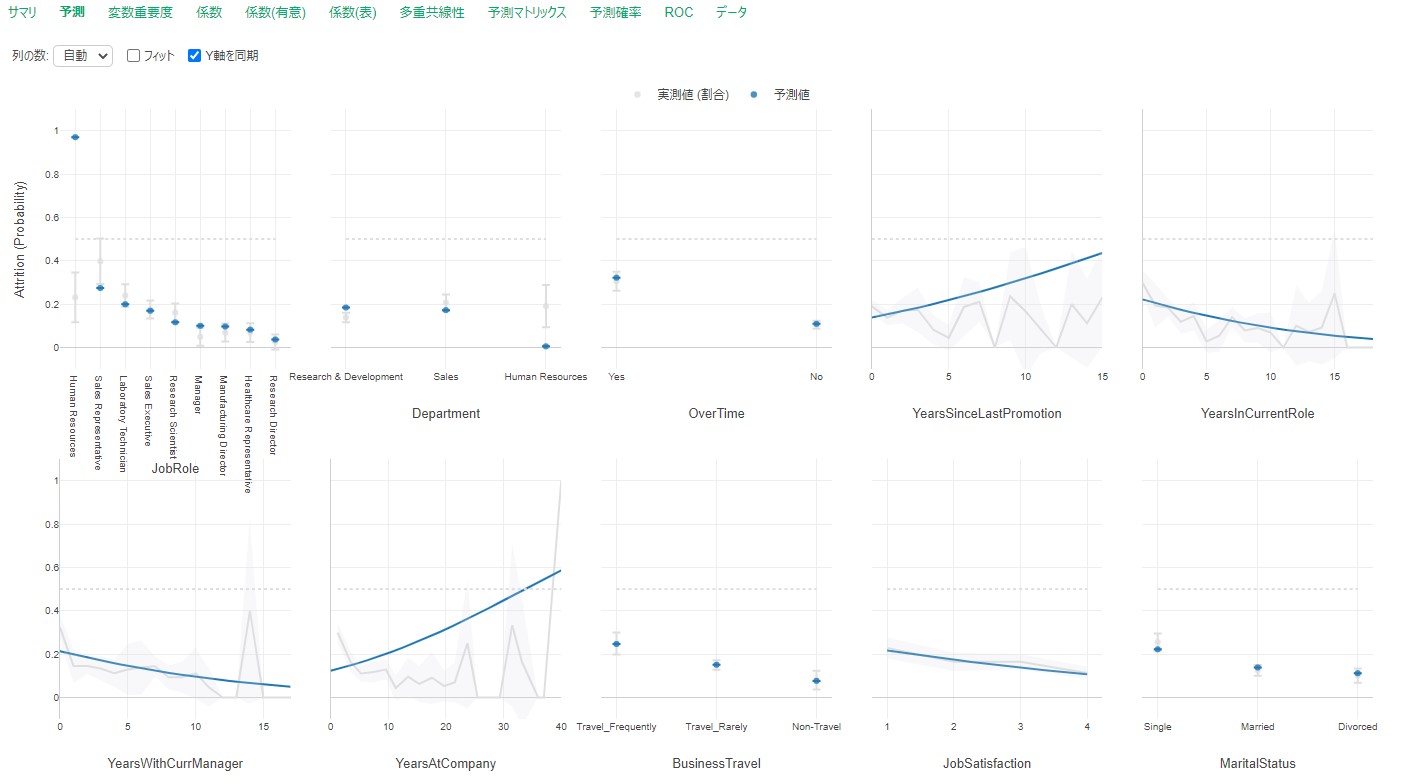
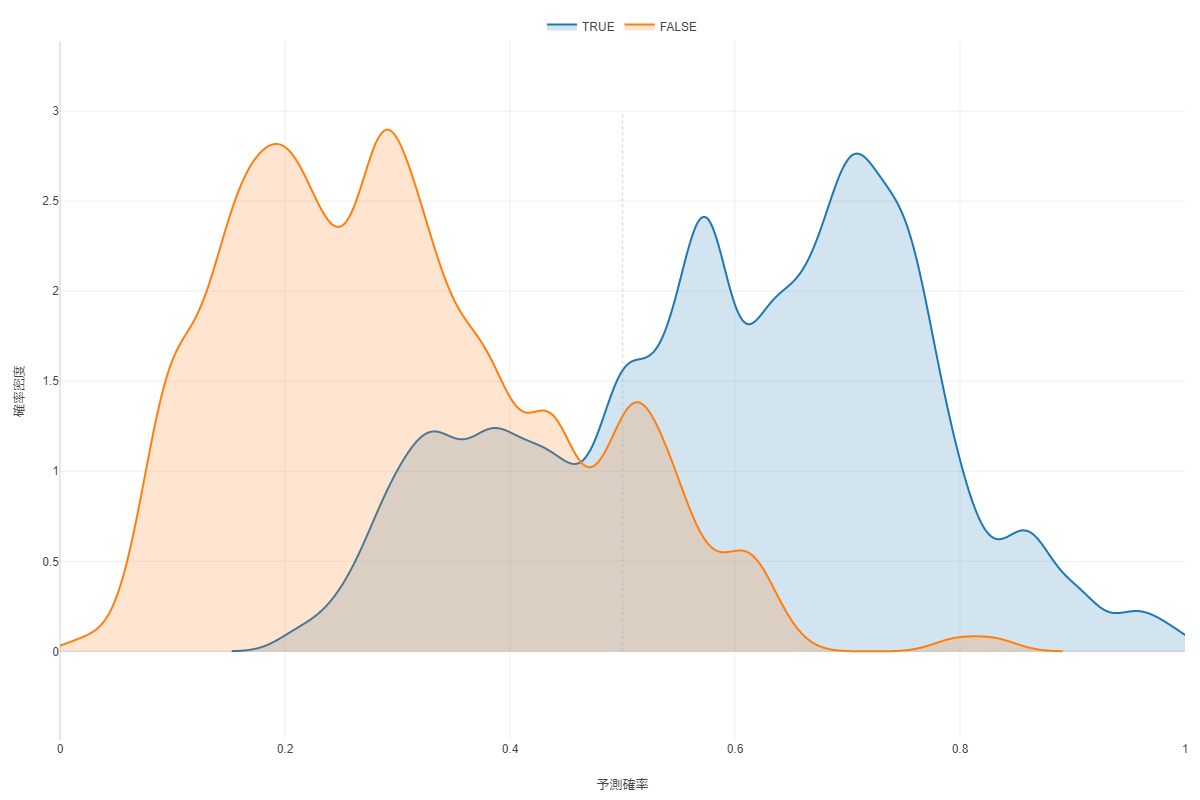
By Tableau-id Press編集部 Exploratory アドベントカレンダー 2020/12/14 目次 Exploratoryってどんなツールなの? 機能の追加がどんどん行われている! 便利で簡単な予測モデル構築方法を紹介 【メンバー募集中】 関連する記事 こんにちは。truestar齋藤です。 今日は弊社内で使用している「Exploratory」というツールによる予測方法を紹介します。 Exploratoryってどんなツールなの? データ接続・加工 データ分析・統計解析・機械学習 可視化 がExploratoryひとつで完結でき、かつプログラミング知識なしで使うことができるツールです。 詳細は以下のExploratoryのサイトをご確認ください。 https://exploratory.io/ ちなみに約1年前に以下のブログでも簡単に紹介させていただきました。 Exploratoryでランダムフォレストをやってみた 機能の追加がどんどん行われている! 上記機能がExploratoryだけで完結できるというだけですごいツールではあるのですが、Exploratoryのさらにすごいところは、機能の追加がどんどん行われている点です。 上記のブログを書いた時はバージョン5.4でしたが、ちょうど今月バージョン6.3が公開となり、以下のとおりExploratoryの勉強会の際にCEOの西田さんが機能の紹介をされていました。 便利で簡単な予測モデル構築方法を紹介 今回は、1年前と同じデータを使って、さらに便利になったモデル構築の機能を紹介したいと思います。 KaggleがOpen Databaseとして公開している以下の「従業員の離職(Attrition)についてのフィクションデータ」を使用します。 https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset/data このデータを使って、離職に影響する要因を調べてみしょう。 データを取り込んでサマリビューを見ると、左上に「相関」というボタンがあります。 ボタンを押して相関を見たい変数を選べば全変数との相関が計算されます。今回はAttritionを目的変数としたいのですが、1/0のロジカル変数のためP値とAUCが計算されるので、P値の小さい順にソートしてみました。以下のとおり重要そうな変数がひと目でわかりやすく並んでいますね。 さらに予測モデルに入れたい変数をCtrlキーを押しながら選択すると緑の枠で囲われるので、その状態から例えばランダムフォレストを選択すると、モデルがぱっと作れてしまうのです! 以下のとおり予測モデルが構築されました。 まずランダムフォレストで実施してみましたが、他の手法では結果が異なるかどうかも気になるところです。 シートをコピーしたうえで、左上のタイプの箇所から「XGBoost」を選択して実行してみると、XGBoostによる結果も簡単に算出できました! ちなみに古いバージョンでは手法を変える場合は変数を再度選び直す必要があったので、その点は非常に便利になりましたね。 せっかくなので結果を比較してみましょう。 上がランダムフォレスト、下がXGBoostの結果です。AUCも正解率もXGBoostのほうが良いことが分かりました。 Exploratoryを使えばこのように簡単に予測モデルの構築ができることがお分かりになったかと思います。 さらに今回のバージョン6.3では、その後の実際の予測も非常に簡単にできるようになっており、予測したいデータを読み込んでおけば、上記で作ったモデルを当てはめて予測も行うことができます。 Exploratoryは30日間無料で試用もできますし、ずっと無料で使用できるPublic版というものも用意されているので、興味がある方はぜひダウンロードして使ってみてください! https://exploratory.io/pricing Public版については以下のとおり弊社ブログでも紹介していますのでこちらもぜひ参考にしてみてください。 Exploratory入門: 無料のExploratory Publicからまずはじめよう 【メンバー募集中】 truestarでは、新しい仲間を募集しています。詳細は以下をご覧ください。株式会社truestar採用サイト https://en-gage.net/truestar/ 関連する記事 Exploratoryでランダムフォレストをやってみた Exploratoryのブートキャンプに参加しました ロジスティック回帰か?ランダムフォレストか? 相関係数の求め方(Excel/Alteryx/Exploratory) Tableau-id Press編集部 / About Author More posts by Tableau-id Press編集部 ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。