はじめまして。shimikouです。
この度Dataiku主催のオンサイト体験会に参加してきましたので、当日の振り返りもかねてブログにまとめようと思います。
体験会に参加した理由と参加した感想
弊社内ではdataikuの技術研鑽が活発に行われており、多くの社員がdataikuのコアデザイナー等の資格を取得しております。
私もこの流れに乗じてdataikuのコアデザイナーまで取得し、現在はdataikuを活用した機械学習の勉強を始めたところです。
ただ、学習を続ける中でdataikuのツールの理解は進んできたのですが、データの加工から機械学習モデルの構築までの全体の流れがいまいちつかみきれず、
この度体験会に参加してみました。
実際に参加してみて、データの加工からモデルの構築、実際の数値予測までを実際に体験することで、
自己学習ではいまいちつかみ切れていなかった機械学習モデル構築までの一連のフローの全体像が非常にクリアになったと感じています。
体験会では細かい部分の説明は端折りながらどんどん進んでいくので、それがかえって全体像をつかむのに有用で非常にわかりやすかったと感じました(笑)
体験会で作成したフローとモデルについて
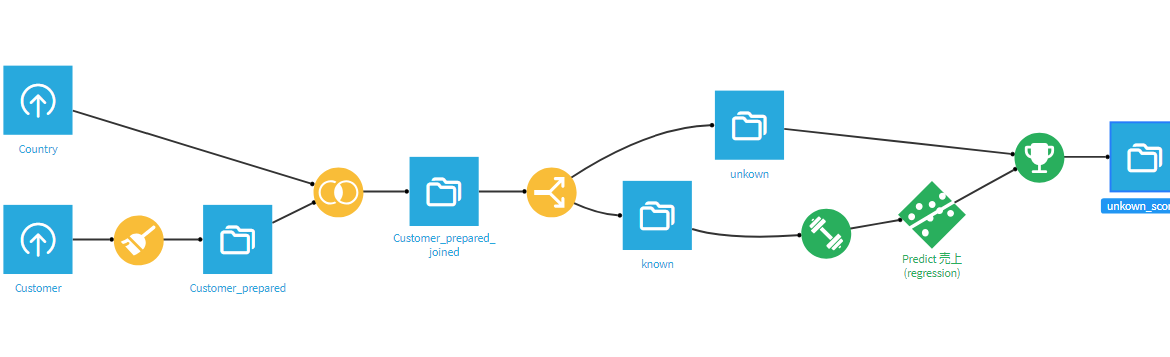
約1時間の体験会の中で下図のフローを作成しました。
このフローの中では、最終的にランダムツリーのモデルで、顧客の売上を予測しています。
このフローを作成するにあたり、データ加工から機械学習モデルの構築まですべてノーコードで実現できており、dataikuというツールが非常に強力なツールだということがお分かりいただけると思います。
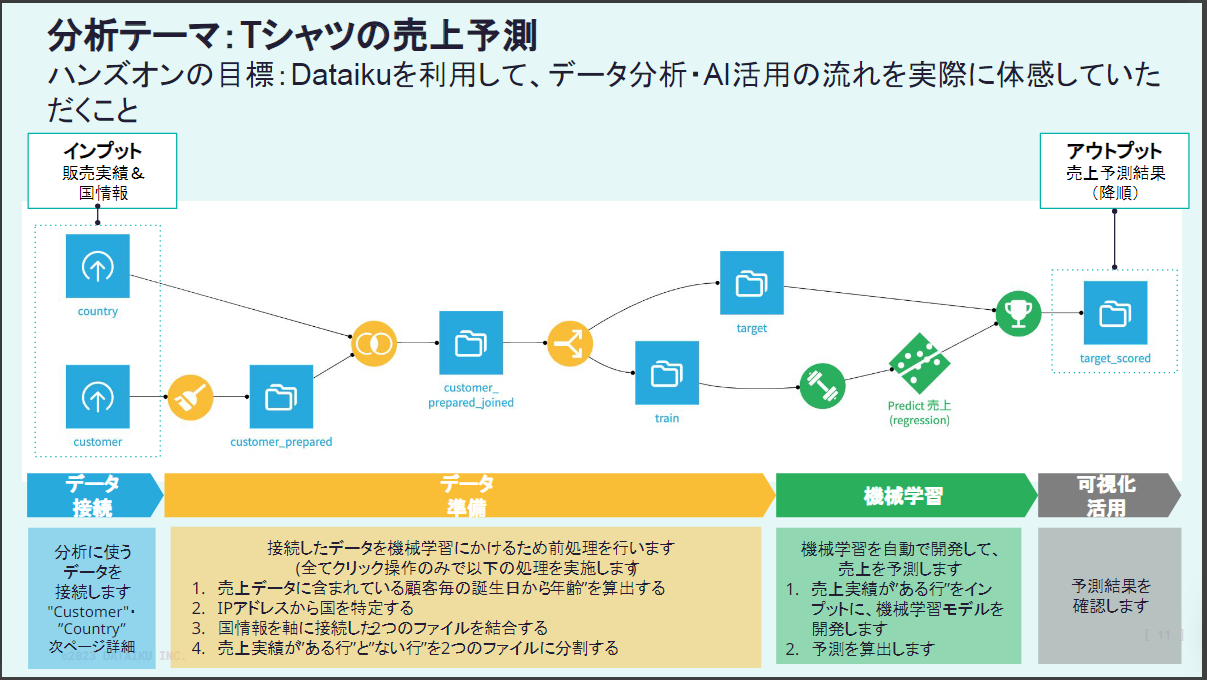
データソース
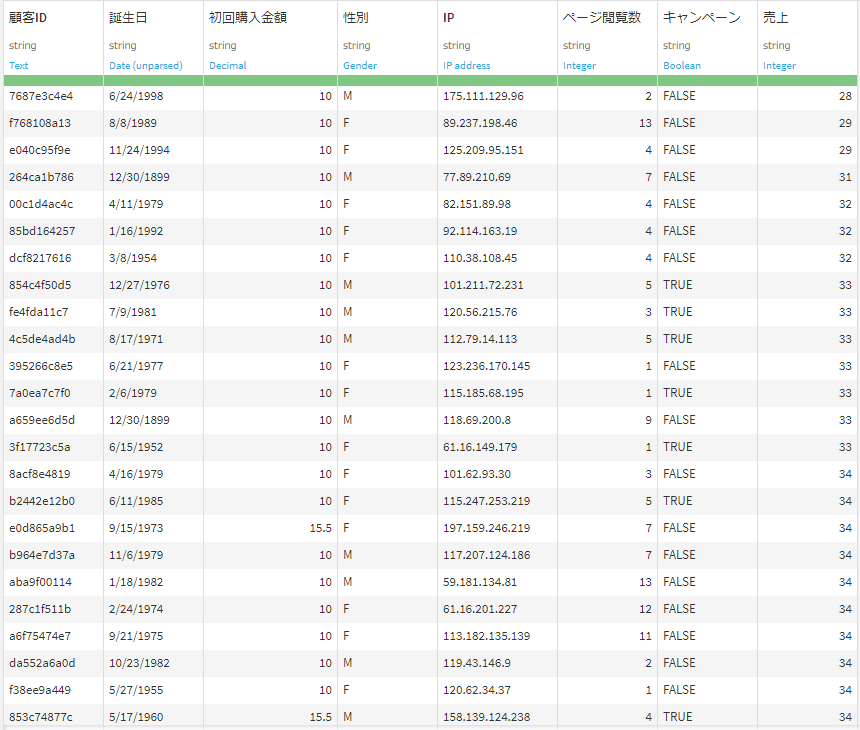
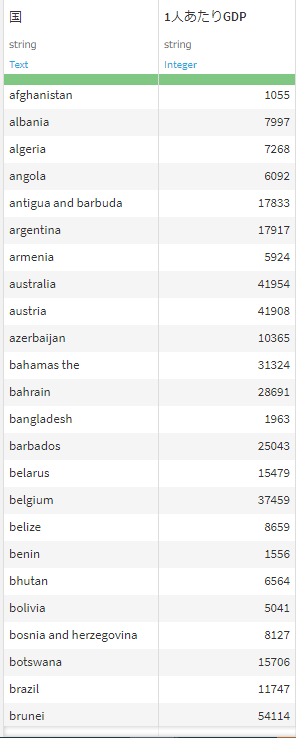
データソースは、①架空の顧客ごとの売上データ(Customer)と、②国ごとの1人当たりGDPデータ(Country)です。
①Customer
②Country
前処理
前処理では下記のことを実践しました。
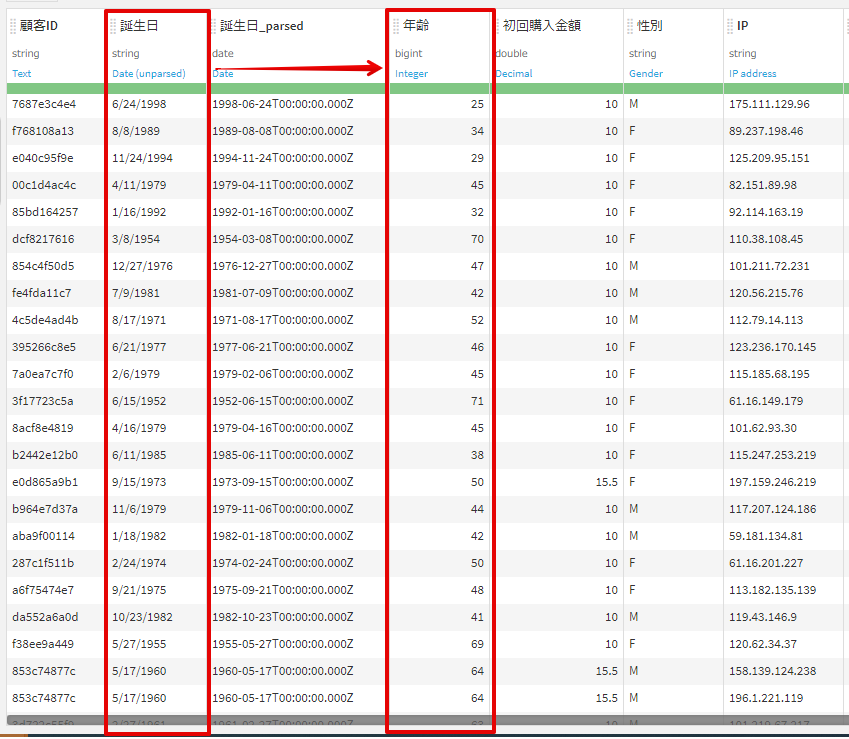
1.生年月日から年齢を算出
文字列データである誕生日を日付形式に変換し、その日付から年齢を算出しています。
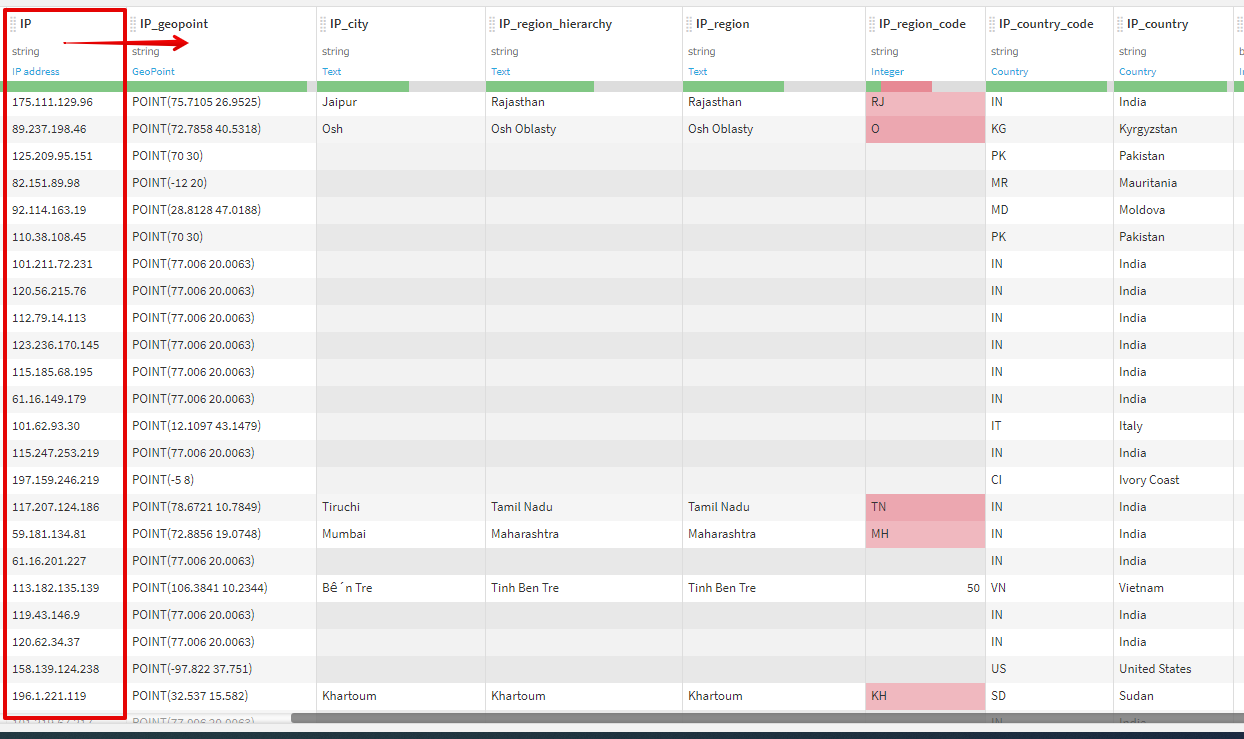
2.IPアドレスから地理情報を取得
IPアドレスから地理情報へ変換を行います。
IP_geopointカラムからIP_countryカラムまでが新たに生成されています。
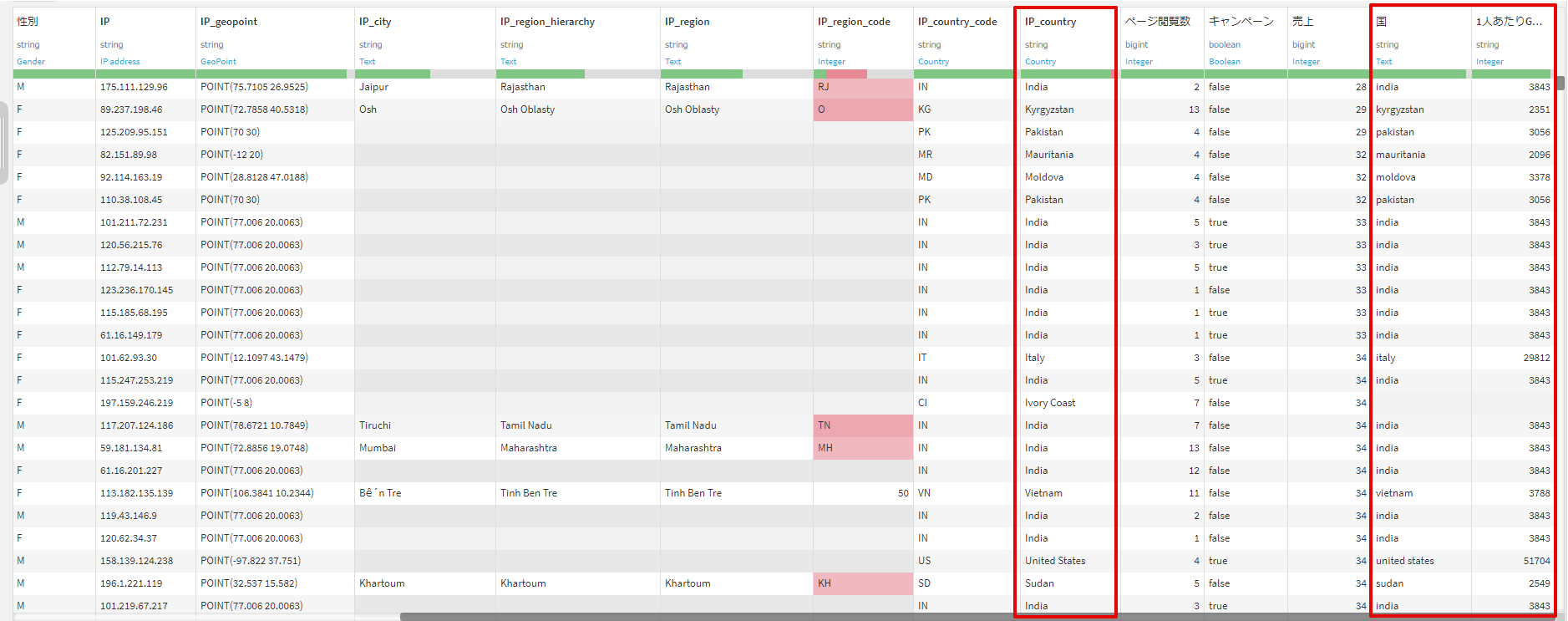
3.テーブルの結合
①テーブルの「IP_country」カラムと、②テーブルの「国」カラムをキーとして結合します。
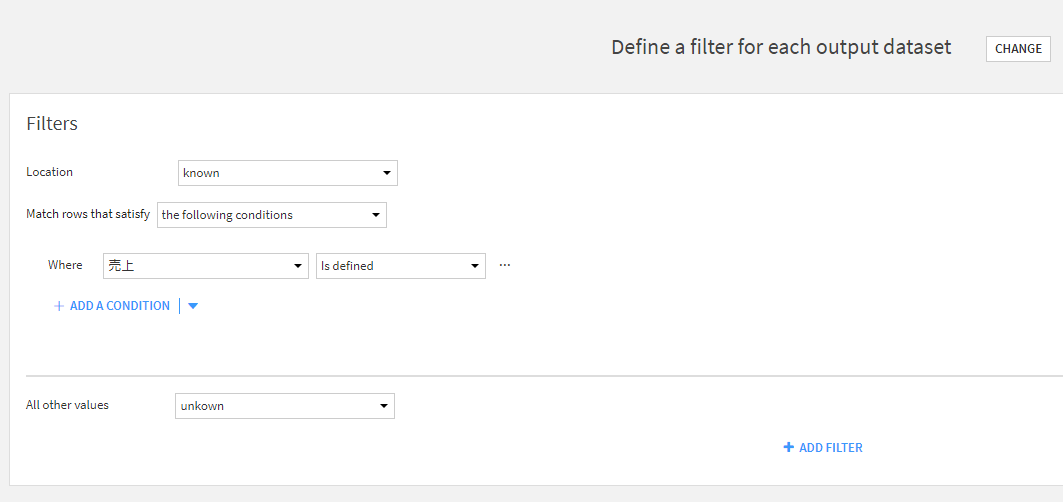
4.設定した条件に応じてテーブルを分割
「売上」カラムが空ではないレコードを「known」テーブルに、空のレコードを「unknown」テーブルへ分割します。
機械学習
データの前処理が終わったので、ここからはモデルの構築をおこないます。
流れとしては、先ほど「known」に分割した(売上が空ではなかったデータ)テーブルを使って売上の予測モデルを構築し、その後、「unknown」テーブル(売上が空のデータ)に対して売上の予測を行っていきます。
1.モデルの構築
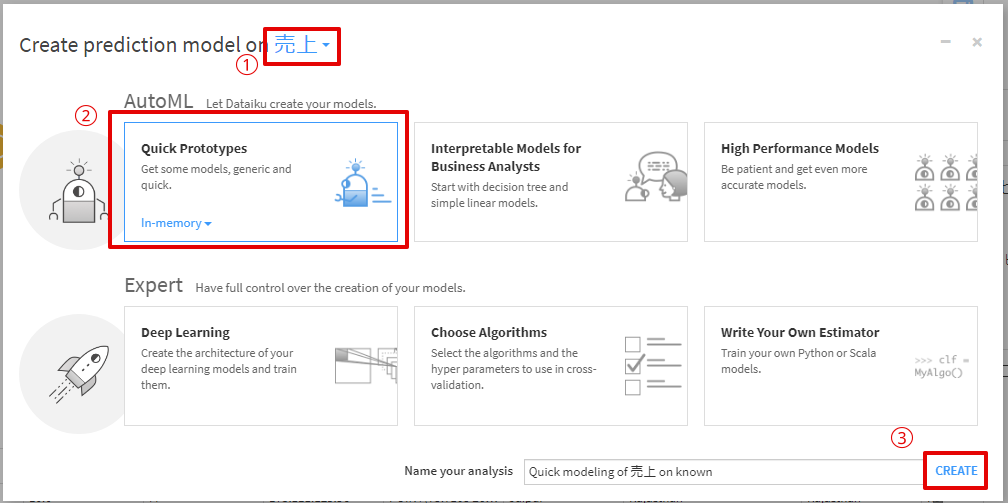
機械学習のモデルを構築するといっても作業自体はとても簡単です。
dataiku上の設定画面で、目的変数を「売上」に設定し、「Quick Prototypes」を選択し、「Create」を押すだけで、dataikuがいい感じにモデルの構築を行ってくれます。
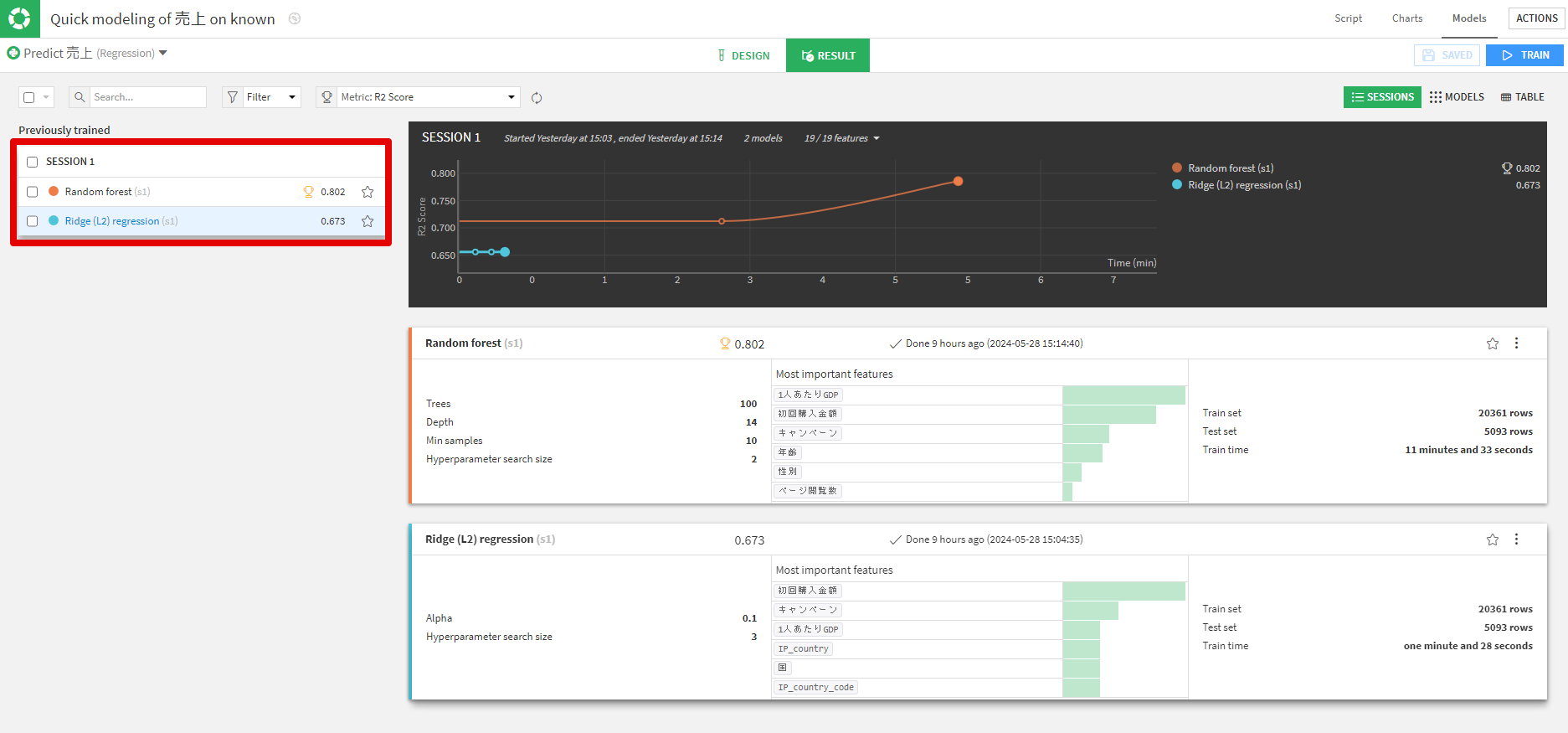
モデルが作成されると下図のような画面が表示され、各モデルの精度を評価するスコアまで示してくれます。
ちなみに、dataikuの初期設定ではランダムフォレストとリッジ回帰がアルゴリズムとして選択されていますが、それ以外のアルゴリズムも自分で好きなように選択可能です。
各モデルの学習の結果、今回はランダムフォレストの方がスコアが高いためこちらを採用します。
2.売上の予測
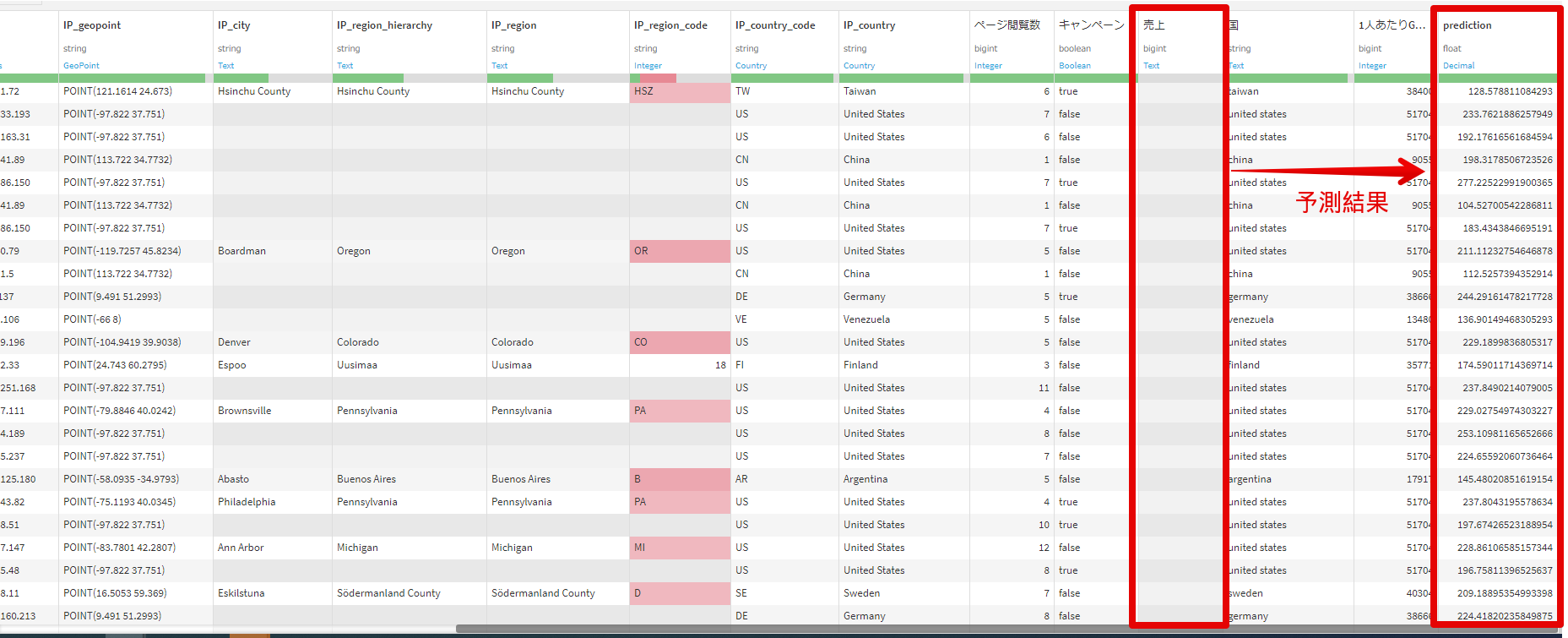
構築されたモデルを用いて、前の処理にて売上が空として分割していたunkownテーブルの売上を予測させます。
予測結果は下図のとおりで、ひとまずきちんと予測できていることがわかります。
終わりに
約1時間という非常に限られた時間の中でも、非常に簡単ではありますが、このように売上データを予測することができました。
ここでは紹介しきれませんでしたが、機械学習モデルがブラックボックス化しないための工夫として、モデルの中身を詳細に確認できる機能も体験会の中では紹介されていました。
dataikuがあればデータ分析がもっと身近なものになると改めて認識した体験会になりました!