
前回に引き続き、Dataikuのインストール版からクラウド版に移行できるか
検証した内容(フォルダ関連)をお届けします。
今回はPythonレシピ(ノートブック)から書き込み・読み込みです。
PythonはRと少し違いまして、ざっくりイメージ図はこちらです↓
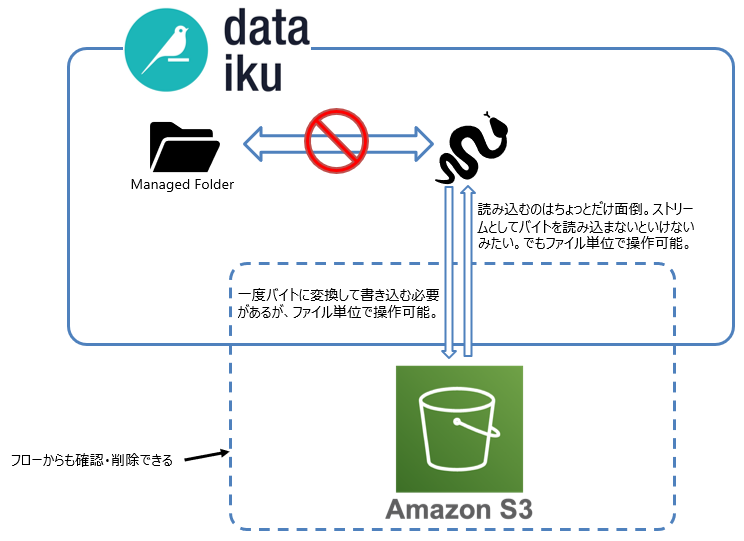
temp_dirのような一時保存ファイルを作成する必要はないのですが、
一度バイトに変換する必要があるみたいです。
Pythonレシピで読み込む場合
import io
import dataiku from dataiku
import pandasutils as pdu
import pandas as pd
# Read recipe inputs
dataiku_folder = dataiku.Folder("XXXXXXXX")
path_for_id = "ids.csv" #任意のファイル名に変更してください。
df_ids = pd.read_csv(io.BytesIO(dataiku_folder.get_download_stream(path_for_id).data))pandas でCSVを読み込む際にDataikuのフォルダー(ここではリモートにあります)から
streamという形式に一度変換してByteを読み込むらしい。
公式のドキュメントはこちらです。
リファレンスはこちらです。
ちゃんと読んだんですけど、あまり理解できなくてサポートの方にご協力いただきました。m(__)m
pandasのデータフレームとして読み込めてしまえばこっちのものですね!
この後は普通にPythonコードをノートブックなどで書きます。
Pythonレシピから読み込む場合
加工が終わったらフォルダに書き出します。
(Snowflakeなどに直接テーブルを書き込むことももちろんできます。これはクラウド版でもインストール版でも同じでした)
# Write recipe outputs
output_folder = dataiku.Folder("YYYYYYYY")
# データフレームを作成するためのデータを定義
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve'],
'Age': [25, 30, 35, 40, 45],
'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Phoenix'] }
# データを使用してデータフレームを作成
df = pd.DataFrame(data)
import io
# データフレームをCSV形式のバイトストリームに変換
buffer = io.StringIO()
df.to_csv(buffer, index=False)
buffer.seek(0) # カーソルを先頭に戻す
# io.StringIO() は文字列用なので、バイト型に変換する
bytes_data = buffer.getvalue().encode()
with connection_test.get_writer("your_file_name.csv") as w: w.write(bytes_data)適当なデータフレームを作成してcsvファイルとしてフォルダに格納しました。
もし上手く行かない、という場合にはレシピ(あるいはノートブック)のInput/Outputで
書き込みたい・読み込みたいフォルダがしっかり追加されているかを確認してください。
インストール版ではフォルダは別にInput/Outputで指定していなくても
フォルダのIDさえわかれば好きに書き込んだりできた(あまりお勧めしないかもですが、できちゃうの知ってる)ところ
クラウド版ではちゃんと明示的に指定する必要があるみたいです。
何も考えずにぽんぽん保存出来るのが仮構築中とかはマネージドフォルダの良いところだと思っていたのに…
Pythonはちょっと変わるだけなのでまだいいのですが、
Rは一時保存フォルダの中身をまるごと(いらないのも含めて)コピーする方法にしかたどり着けていないので
(サブフォルダを指定したりいろいろ実験はしたんですが、うまく行かず)
ごみを溜まったままにしないようなシナリオを組むとかした方がいいだろうな、と思いました。





