
たびたびゲスト投稿させてもらってます、deepblueのひめのです。
Truestar時代にはごりごりAlteryx使ってまして、今もたまに使ってます。私はまだまだpython書くよりもAlteryxの方が作業が早いです。
今回は「AlteryxでウェブページのUI操作ってできるの?」というお題が社内の駆け込み寺に上がっていて、それに対してできました~というのがブログネタになりました。
弊グループの駆け込み寺に関してはこちら。(私もいつもお世話になってます。)
Alteryxでウェブページを操作しよう
ゴールはGoogle Chromeでウェブサイトにアクセスし、サイト上のデータを取って来てAlteryxで使えるようにする、です!
タスクを分解すると以下のようになります。
- AlteryxからGoogle Chromeを立ち上げる準備をする
- Google Chromeでウェブサイトにアクセスする
- ウェブサイトからデータを取得する
- Alteryxで使えるように整える
一つずつ見ていきましょう!
0.Alteryxでpythonツールを使う
今回はAlteryxのpythonツールを使用します。デベロッパーツール群の中にいます。(初期設定だと表示されていないかもしれないので、一番右の+ボタンから表示させてください)

ツールを置くとインプットは1つ、アウトプットは5つ出てきます。フロー上のデータを受け取ることもできますが、今回はインプット無し、めちゃくちゃシンプルなこの形を目指します。
フロー上のエラー表示はなぜか出てしまうんですよね…問題無く動きますので無視してください。
ツールを置いて、ツールをクリックするとこんな画面になります。(404とか出たら一回キャンバスの適当なところをクリックして再度ツールをクリックするといけます。最初の読み込みエラーがたまに出るみたい)
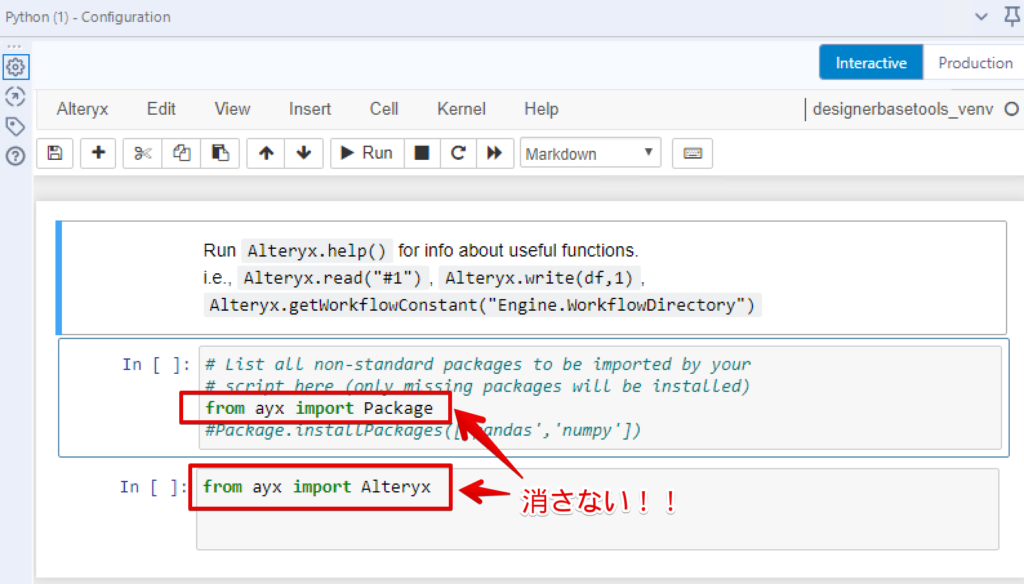
赤枠の「消さない!!」は上手く操作するためにおまじないだと思ってそのままにしておきましょう。
1.AlteryxからGoogle Chromeを立ち上げる準備をする
必要なライブラリをpythonツールでインポートします。消さないでおいたおまじないの下に書きましょう。
ウェブUIを操作するのはSeleniumというパッケージになります。
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
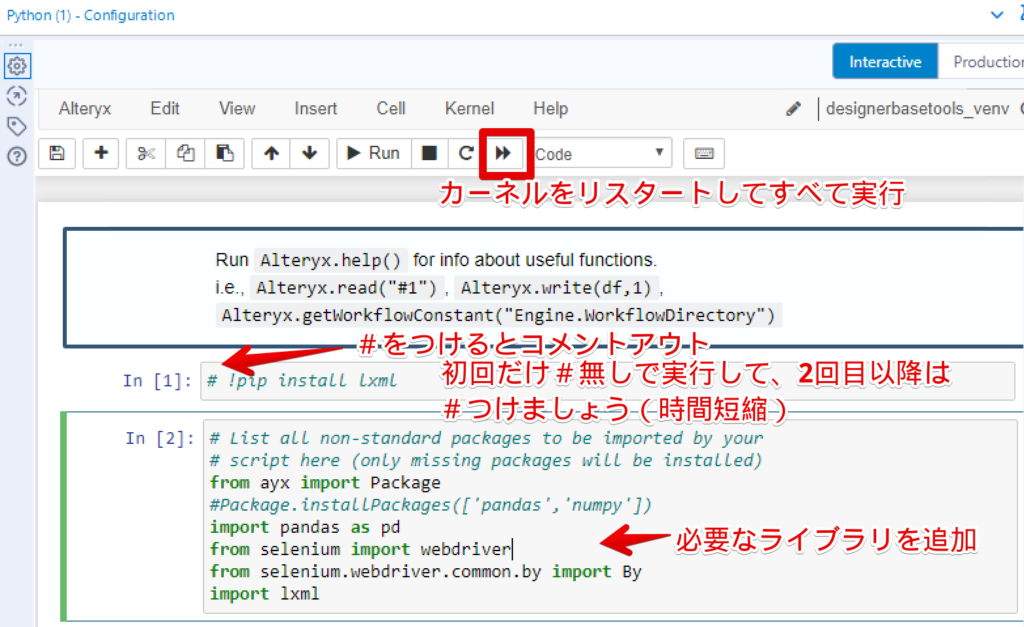
import lxmlno module… というエラーが出たら!pip install をする必要がありますが、初回だけ必要なので2回目以降はコメントアウトします。
再生ボタンみたいなのが「カーネルをリスタートして全部実行」にあたりますが、インポートなど設定変更したはずなのに反映されないときはこのボタンを押しましょう。
2.Google Chromeでウェブサイトにアクセスする
今回はこちらのサイトにアクセスします。 https://hotel.testplanisphere.dev/ja/
テスト自動化のための練習用サイトだそうです。ありがたいです。
Google Chromeを立ち上げる文を追加します。
# chromeでサイトにアクセス
driver = webdriver.Chrome()
driver.get("https://hotel.testplanisphere.dev/ja/")セルを実行するとChromeが立ち上がってサイトが表示されます。
3.ウェブサイトからデータを取得する
ウェブページから何を抜き取るのか決めます。Alteryxで使いやすそうなテーブルの情報を今回持ってこようと思います。
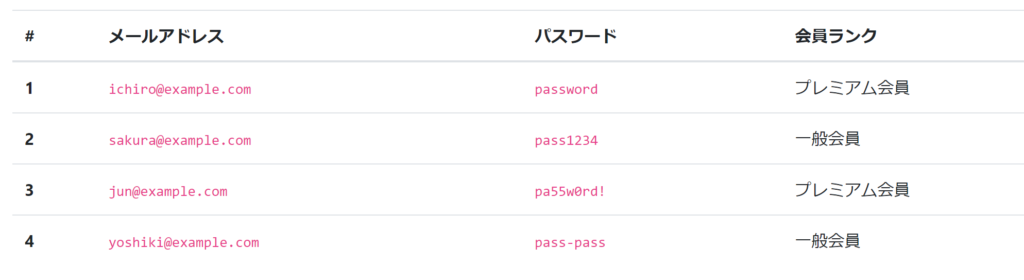
サイトを開いてF12を押して、↑のテーブルのXPathをコピーします。
深い構成になっている中から頑張って探します。(htmlあんまり詳しくないのでもうちょっといい方法あるんでしょうか…我流ですみません)
右側の行にマウスオーバーすると左側でどの部分かハイライトされるのでたどって行くと…

あった!!すかさず赤枠の部分を右クリックしてXPathをコピーします。
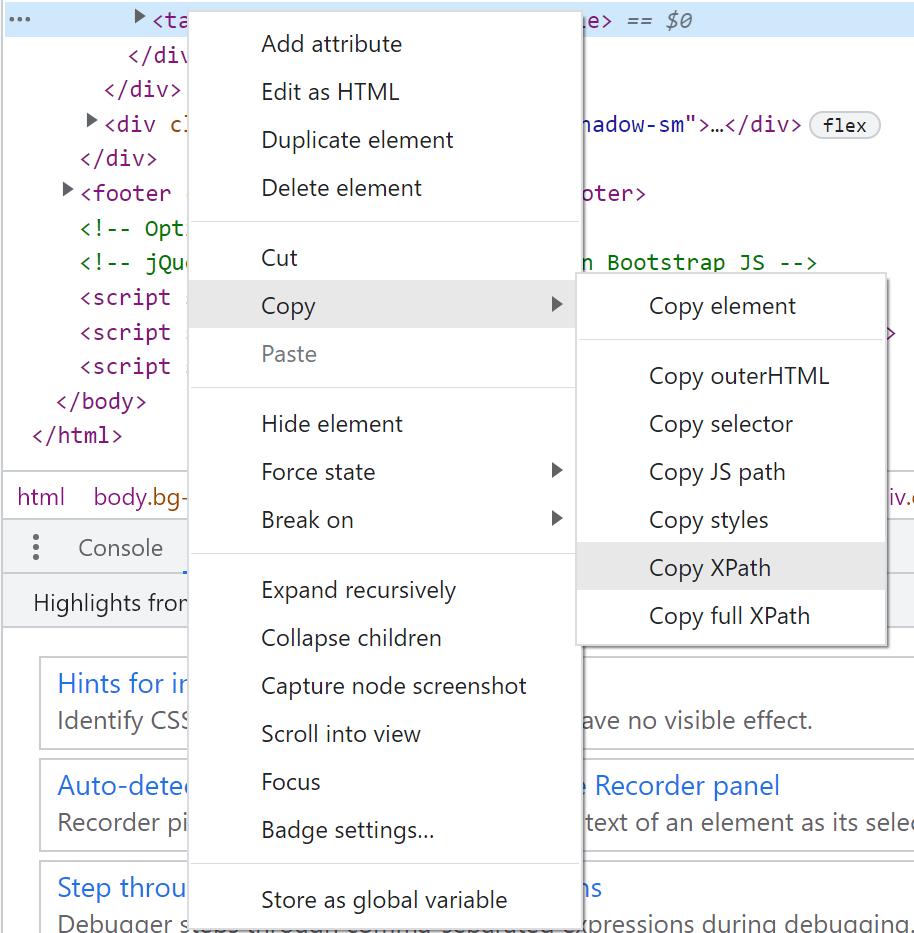
pythonツールでこのXPathを取ってくるようにスクリプトを追加します。
elem_table = driver.find_element(by=By.XPATH, value="/html/body/div/div[2]/div/table")
html = elem_table.get_attribute('outerHTML')
dfs = pd.read_html(html)[0]
print(dfs)value=の後に入っているのが先ほどコピーしたXPathです。
dfsというのがpandasのデータフレームです。Alteryxは今のところpandasのデータフレームでないと出力ができない仕様になっているので形式を合わせる必要があります。
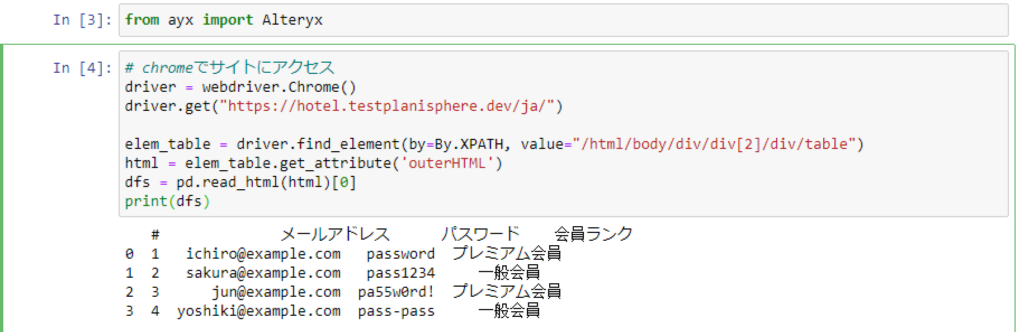
残しておいたおまじないと、サイトの立ち上げも併せてここまでのコードの中身を確認します。
dfs = pd.read_html(html)のままだと形式がリストで、アウトプットができないので注意です。[0]でどの部分を取ってくるかの指定が必要です。
printでdfsの中身を見てみると、テーブルがしっかり表示できているのがわかります!
4.Alteryxで使えるように整える
アウトプットアンカーからデータを取れるようにします。
すでにデータフレームなので5つあるアンカーのどれから出力するのかをAlteryxの書き方で指定します。
Alteryx.write(dfs, 1)Alteryx.write([何を], [何番から]) という書き方になります。今回は一つしかないので1番から出せばいいですが、複数アウトプットも一度に作成できるということですね。
(from ayx import Alteryx はこれを使うためにはおまじないでした。)
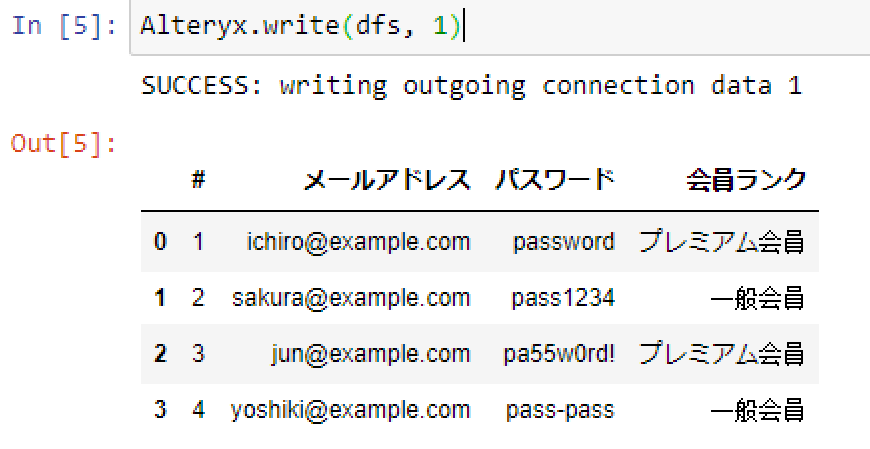
実行するとSUCCESSというのと、書き込まれた結果が出ます。printした内容と一緒なので一安心です。
最後に開きっぱなしのChromeウィンドウを閉じます。閉じるコードも入れないと手動で消すことになってちょっと面倒なので入れておきましょう。
#インスタンスウインドウを閉じる
driver.quit()Alteryxのフローの中で使えるようになったか確認するためにブラウザツールを付けてみましょう。
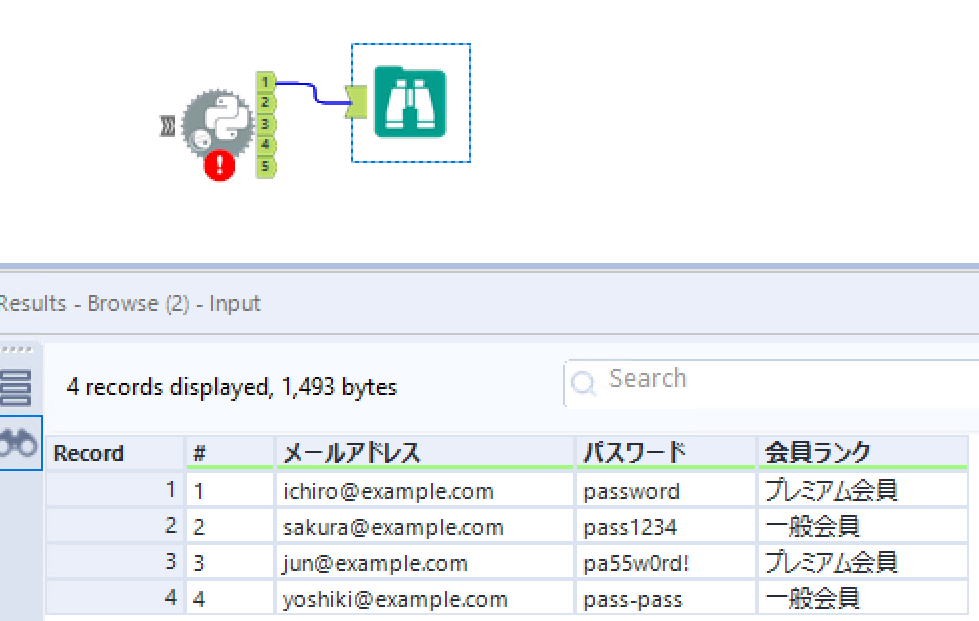
データがフローの中で使えるようになりました!
まとめ
今回のコードの中身を通しで見るとこんな感じになります。セルは分けてもくっつけてもどちらでも良いです。
# 実行される方の環境次第では初回のみライブラリをインストールする必要があるかもしれません
# !pip install lxml
# List all non-standard packages to be imported by your
# script here (only missing packages will be installed)
from ayx import Package
#Package.installPackages(['pandas','numpy'])
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
import lxml
from ayx import Alteryx
# chromeでサイトにアクセス
driver = webdriver.Chrome()
driver.get("https://hotel.testplanisphere.dev/ja/")
# 取得する要素を指定
# 今回はXPath
elem_table = driver.find_element(by=By.XPATH, value="/html/body/div/div[2]/div/table")
html = elem_table.get_attribute('outerHTML')
dfs = pd.read_html(html)[0]
print(dfs)
# 出力する
Alteryx.write(dfs, 1)
#インスタンスウインドウを閉じる
driver.quit()pythonツールでseleniumを動かせるとAlteryxでできることの幅が広がりますね!
ぜひお試しください!





