
こんにちは。Ozawaです。
最近、Snowflakeのデータリネージ機能がPublic Previewされました。(aws東京リージョンでもできる!)
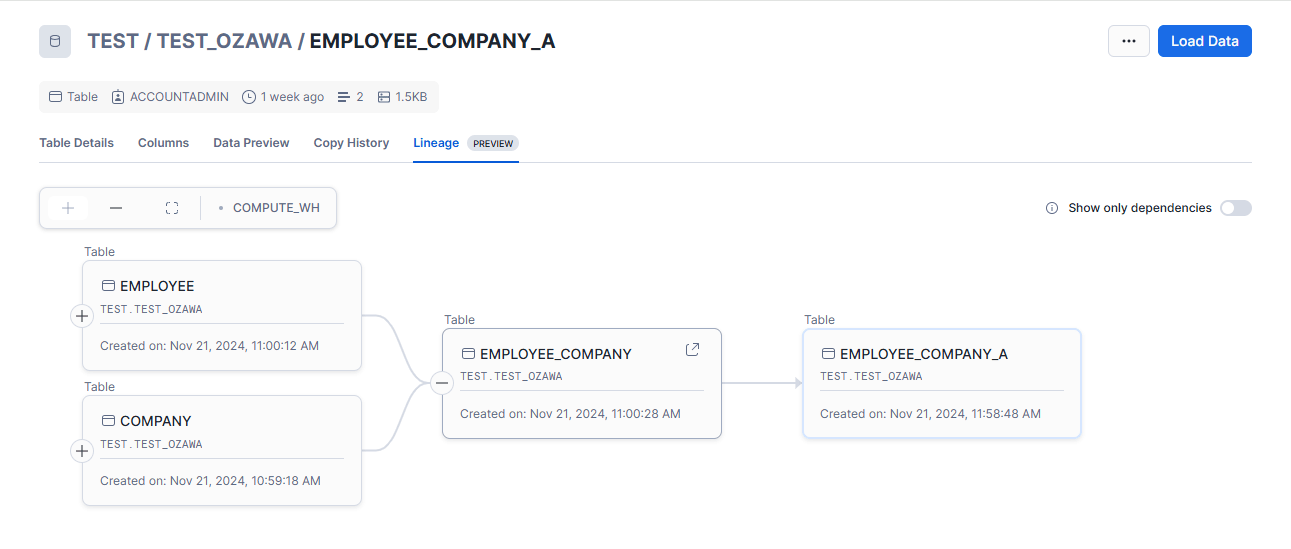
データリネージというのが、どのテーブルからどのテーブル作成されたかという依存対応表みたいなものとなります。(下図)
どのテーブルから作成されたかという点をパッと見ることができる点がリネージ図の強みとなります。
今回はデータリネージ図の表示、およびクエリでテーブルやカラムの依存関係を取得するといったチュートリアルブログとなります。
検証
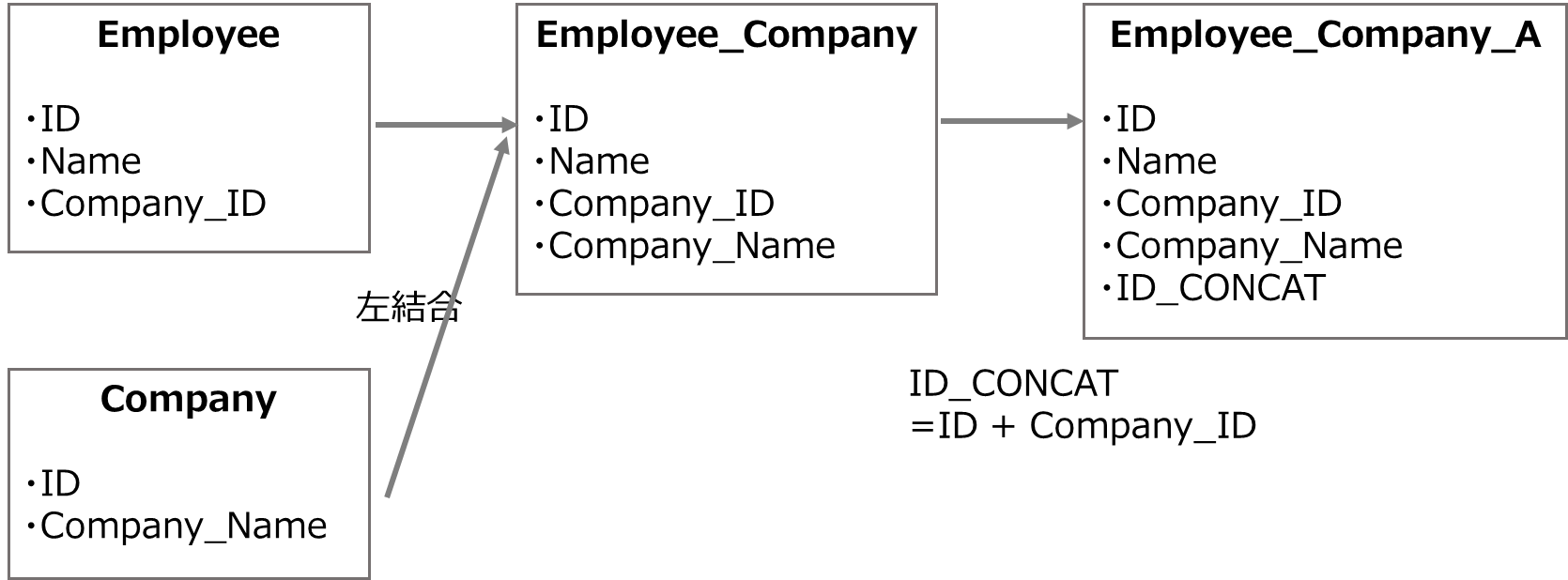
早速以下のように「Employee」テーブル、「Company」テーブル、結合済みの「Employee_Company」テーブル、そこからIDとCompany_IDカラムを結合したカラムを作成し「Employee_Company_A」テーブルを用意します。
データリネージ図の表示
Snowflake上のデータリネージでは、テーブルの依存関係とカラムの依存関係を見ることができます。
データリネージ図の表示方法は、SnowSightのDatabases→任意のテーブル→Lineagesを選択。
図のようにテーブルの依存関係を見ることができます。
今回でいうと、「Employee」と「Company」から「Employee_Company」が紐づけされ、「Employee_Company」から「Employee_Company_A」が紐づけされていますね!
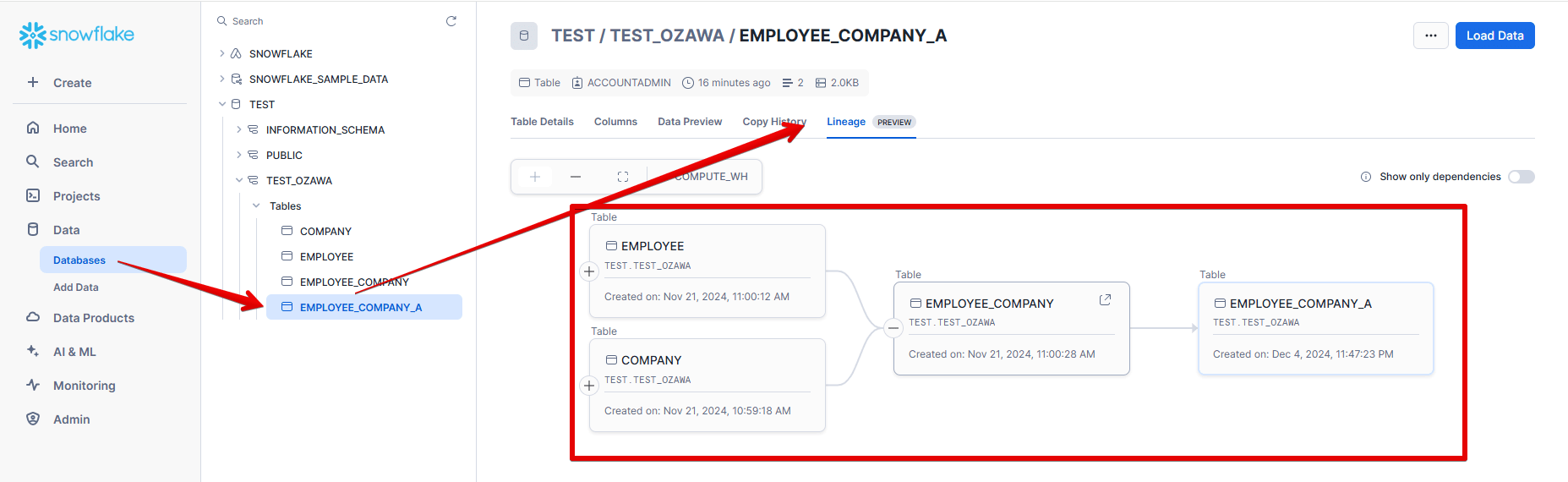
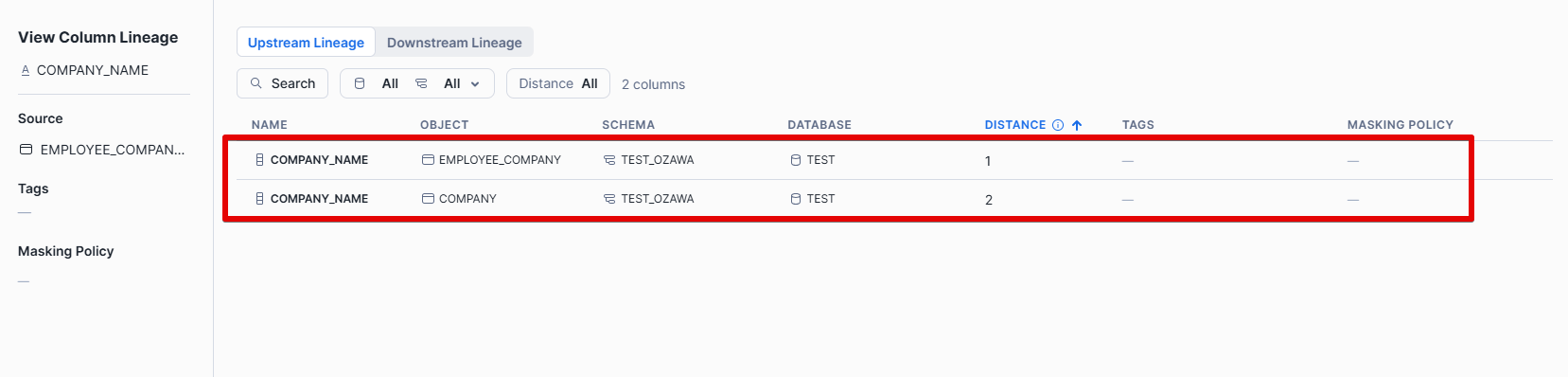
また、テーブルを選択し、任意のカラムでView Lineageを選択すると、、、(今回は末端「Employee_Company_A」テーブルのCompany_Nameを選択)
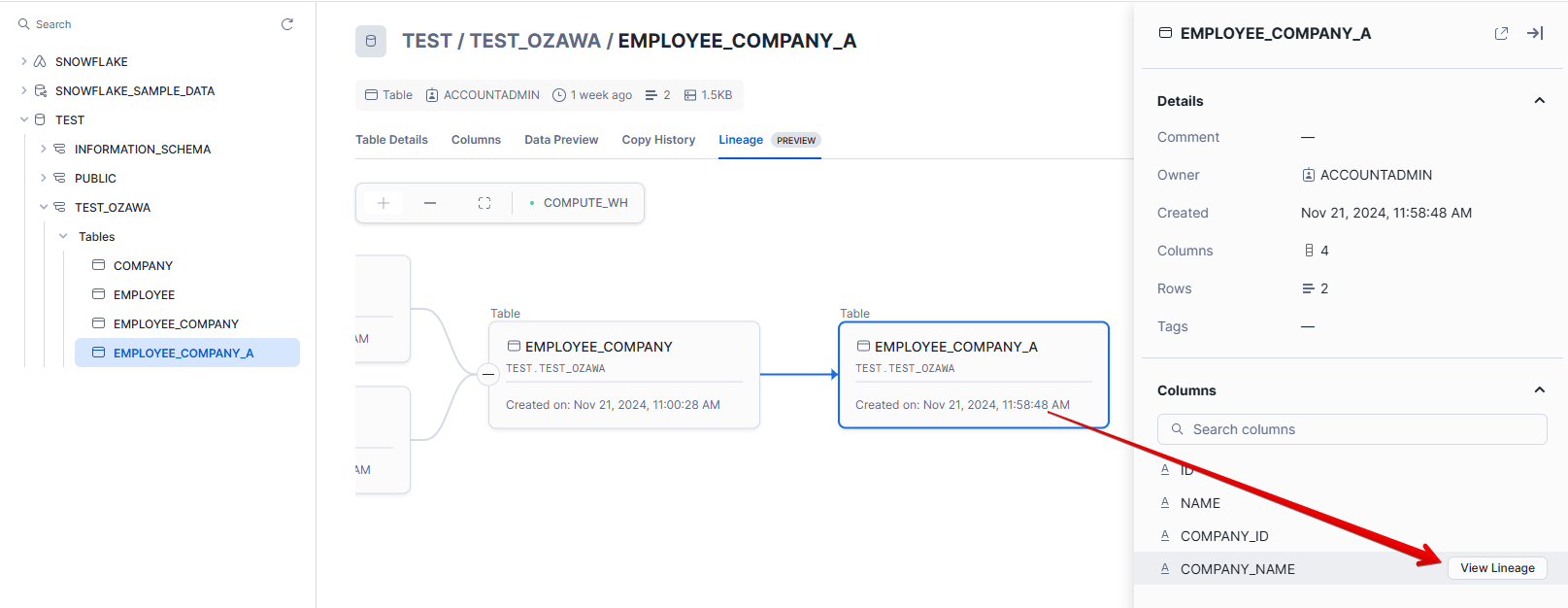
選択したカラムの元となる、上流の「Company」テーブルおよび「Employee_Company」テーブルのカラムのCompany_Nameの情報が表示されていることが分かります。
※ちなみに、Upstream/Downstream Lineageとは何かという話ですが、依存関係の調査を上流へと調べていくのか、下流へと調べていくのかということです。
Upstreamは選択したテーブルやカラムよりも上流の参照元を一覧化します。Downstreamは選択したテーブルやカラムよりも下流を一覧化します。
クエリでのデータリネージの取得方法
次に、クエリ上でSnowflakeのリネージ情報を表示する方法を紹介します。
リネージ情報はSNOWFLAKE.CORE.GET_LINEAGE関数を使用します。
まずは、「Employee_Company_A」テーブルの依存関係を調査してみます。
・引数1:Employee_Company_A(テーブル名)
・引数2:TABLE(テーブルの調査/カラムの調査)
・引数3:UPSTREAM(上流/下流調査)
・引数4:2(何個先のテーブル/カラムまで調べるか?)
//EMPLOYEE_COMPANY_Aテーブルの2個上流まで依存関係を調査
SELECT
DISTANCE, //EMPLOYEE_COMPANY_Aテーブルから何個離れているか。
CONCAT(SOURCE_OBJECT_DATABASE, '.', SOURCE_OBJECT_SCHEMA, '.', SOURCE_OBJECT_NAME) SOURCE_TBL,
CONCAT(TARGET_OBJECT_DATABASE, '.', TARGET_OBJECT_SCHEMA, '.', TARGET_OBJECT_NAME) TARGET_TBL
FROM TABLE (SNOWFLAKE.CORE.GET_LINEAGE('EMPLOYEE_COMPANY_A', 'TABLE', 'UPSTREAM', 2));「Employee_Company_A」のテーブルの依存関係が表示されました。
| DISTANCE | SOURCE_TBL | TARGET_TBL |
| 1 | EMPLOYEE_COMPANY | EMPLOYEE_COMPANY_A |
| 2 | EMPLOYEE | EMPLOYEE_COMPANY |
| 2 | COMPANY | EMPLOYEE_COMPANY |
SOURCE_TBLをもとに、TARGET_TBLを作成する、という見方です。
例えば、2個上流の「Employee」と「Company」テーブルにより、「Employee_Company」が作成され、1個上流の「Employee_Company」から「Employee_Company_A」が作成されていることが分かります。
次にカラムの依存関係を表示してみましょう。例として、「Employee_Company_A」テーブルのID_CONCATカラム(IDとID_Companyの結合)を見てみます。
・引数1:Employee_Company_A.ID_CONCAT(カラム名)
・引数2:COLUMM(テーブルの調査/カラムの調査)
・引数3:UPSTREAM(上流/下流調査)
・引数4:2(何個先のテーブル/カラムまで調べるか?)
//EMPLOYEE_COMPANY_AテーブルID_CONCATカラムの2個上流まで依存関係を調査
SELECT
DISTANCE,
CONCAT(SOURCE_OBJECT_DATABASE, '.', SOURCE_OBJECT_SCHEMA, '.', SOURCE_OBJECT_NAME, '.', SOURCE_COLUMN_NAME) SOURCE_COLUMN,
CONCAT(TARGET_OBJECT_DATABASE, '.', TARGET_OBJECT_SCHEMA, '.', TARGET_OBJECT_NAME, '.', TARGET_COLUMN_NAME) TARGET_COLUMN
FROM TABLE (SNOWFLAKE.CORE.GET_LINEAGE('TEST.TEST_OZAWA.EMPLOYEE_COMPANY_A.ID_CONCAT', 'COLUMN', 'UPSTREAM', 2));
「Employee_Company」から「Employee_Company_A」への過程で、IDとCompany_IDカラムをもとに、ID_CONCATが作成されていることが分かります。
| DISTANCE | SOURCE_COLUMN | TARGET_COLUMN |
| 1 | EMPLOYEE_COMPANY.ID | EMPLOYEE_COMPANY_A.ID_CONCAT |
| 1 | EMPLOYEE_COMPANY.COMPANY_ID | EMPLOYEE_COMPANY_A.ID_CONCAT |
| 2 | EMPLOYEE.ID | EMPLOYEE_COMPANY.ID |
| 2 | EMPLOYEE.COMPANY_ID | EMPLOYEE_COMPANY.COMPANY_ID |
おわりに
truestarでは、Snowflake導入検討、導入支援や環境構築まで幅広くサポート可能です。
Snowflakeに゙興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらから相談ください!
また、truestarではSnowflake Marketplaceにて、加工済みオープンデータを無償提供するPrepper Open Data Bank、全国の飲食店の情報を集めたデータセットの販売を行っております。(サービスリンク)
これまでのSnowflakeに関する記事はこちら




