
先日、Dataiku Tech BootcampというDataikuのパートナー企業向けのイベントへ参加してきました。
このブログではイベント内で行われたハンズオンの詳細について記載していきたいと思います。
概要
Dataikuの管理者向けのスキルトレーニングの内容がメインのセミナーで、2日開催で10時~18時のボリュームとなります。
管理者向けのトレーニングということで、FleetManagerからDesignノード・Automationノード・APIノードを立ち上げたり、AWSのEKSを使ったクラスターの構築や設定、各ノードやクラスターのCodeEnvの設定などDataikuでデータ分析を行う前段階の設定などを中心に学ぶ内容となりました。
そのため、参加にあたっては以下のような前提条件が設けられていました。

具体的な項目の詳細は次の章で説明します。
トレーニングの内容について
トレーニングのアジェンダ
2日間に合わって計13項目のハンズオンを実施しました。それぞれの内容は以下の通りです。
- Managing Dataiku with Fleet Manager
- Security Model in Dataiku
- Creating Connection Best Practices
- Containerized Execution Configuration
- Code Environments
- Spark Configuration
- Setup and Manage Audit Trails, Event Server
- Automating Projects_Macros & Senarios
- Monitor DSS, Disk Usage & Usage Reporting
- Using the Dataiku Public API
- Upgrading Fleet Manager
- DSS Backeups and Recovery
- Troubleshooting in Dataiiku
1~6の項目がDay1、7~13の項目がDay2で実施となりました。
各項目の詳細
ここからは各トレーニングの実施内容について記載します。
細かい内容を記載すると書ききれないため、今回は各ハンズオンの概要やポイントなどを記載するにとどまります。
必要に応じて参考となるドキュメントへのリンクなどを貼り付けますので、興味がある項目はそちらを見てみてください。
1.Managing Dataiku with Fleet Manager
FleetManagerを通してノードの管理を行うハンズオンです。
BluePrintを利用することで簡単に各ノードの構成を設定することができるため、今回はBluePrintを用いた設定を行いました。
今回の設定では、デザインノード、Automationノード、APIノードの三種類を立ち上げました。
他にもAutomationノードへのデプロイを行うためのデプロイヤーノードがありますが、今回はデプロイヤーの環境はデザインノード上に設定する形の構成をとりました。
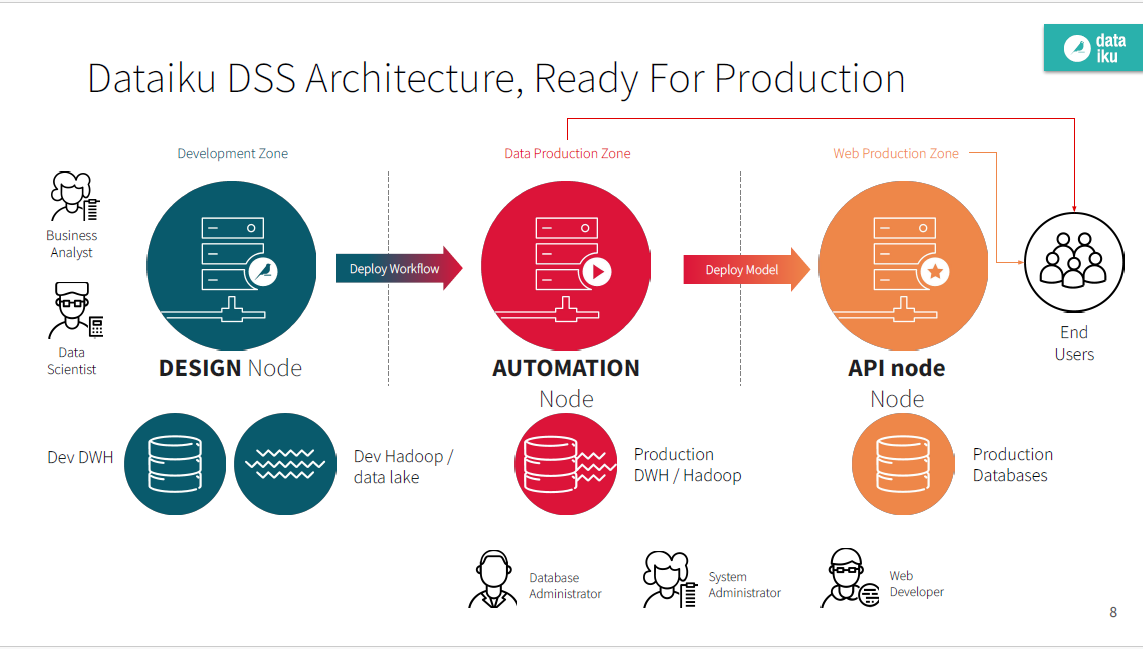 各ノードの関係図のイメージ。
各ノードの関係図のイメージ。
InstanceTemplateの設定で立ち上げ時にインストールするソフトウェアなども指定できるため、実運用時にはあらかじめ設定が必要なことも多いと思います。
また、今回はFleetManagerの構築にCloudStacksを利用しました。構築の方法についてはこちらを参考にしてください。
2.Security Model in Dataiku
ここでは一般的なDSSのセキュリティ設定のハンズオンを行いました。
いくつかのユーザーやグループを作成し、それぞれに応じた権限を設定しています。
また、パーミッションには以下の3つの区分があります。
- Global Permissions
- Project Permissions
- Resource Permissions
今回はプロジェクトごとにユーザーの権限を設定するところをメインに実施しました。
3.Creating Connection Best Practices
DSSと各種データベースへの接続設定に関するハンズオンです。
PostgreSQLやSnowflake、S3などへのコネクション設定を行いました。
Snowflakeの場合、"Auto fast-write connection"のチェックを有効化することでバルクアップロードができるようになります。
データの書き込み速度が上昇するので設定をしておいた方が良いとのことです。(通常だと1件ずつinsertするような動きになるので時間がかかる。)
また、S3などAWSのリソースに対しては複数の認証情報の設定に関してはSTS AssumeRoleを用いた設定を有効化することを推奨しています。
(キーペアを用いた認証情報の設定はお勧めしていない。)
詳細はこちらのリンクから確認してみてください。
4.Containerized Execution Configuration
AWS EKSを利用したクラスターの作成に関するハンズオンを実施しました。
クラスタを構成することで、DSS上で実行する処理をクラスタに任せることができます。それによりDataikuの実行ノードに処理をさせないように処理を切り出すことができます。
このクラスタはコンテナ化されており、処理に応じてスケーリングさせることが可能です。そのため、”Containerized execution configuration”の項目で、どの程度の処理能力を持たせたクラスタをどれだけ立ち上げるかを設定します。
また、コンテナ化されたクラスタは複数設定することができるため処理に応じてどのクラスタを利用するかを設定することができます。具体的にはCodeEnvironmentごとにどのクラスタをデフォルトで使用するかなどの設定が可能です。
また、このクラスタに処理を任せる設定はこれまではPythonレシピなどの一部の機能でしか設定できませんでした、Dataikuの最新版(12.6以降)では通常のビジュアルレシピの処理もクラスタに任せることができるようになるとのことです。
5.Code Environments
PythonやRのコード環境の構築のハンズオンを実施しました。実行する処理に応じて、Pythonのバージョンや必要なライブラリを設定します。
Add Set of Packagesの項目で追加するライブラリを指定します。(複数のライブラリ群をまとめてインストールすることも可能。)
作成したCodeEnvを利用できるユーザーやコンテナに対してのPermissions設定なども指定します。
また、プロジェクトでPythonノートブックを作成し手順で作成したコード環境を用いてコードを実行しました。
このノートブックはDSS上でも立ち上げられますが、EKSクラスタ上にも立ち上げることができます。ただ、その場合ノートブックを実行している間にクラスタが起動されるため、利用が終わったり不要なノートブックは削除しないと、クラスタの課金が発生してしまうので注意が必要です。
6.Spark Configuration
Sparkに関する設定のハンズオンです。
Dataiku上でSparkを用いた処理を行うことが可能です。その場合も同様にEKSのクラスタ上でSparkを実行することになるため、クラスタに関する設定を行います。
また、クラスタの実行環境は複数設定することができるため、Pythonやビジュアルレシピの実行環境とSparkのための実行環境を分けて作成を行いました。
Sparkで必要なリソースとPython処理で必要なリソースは異なるため、効率の良いクラスタの構築を行った方が良いためです。
また、Sparkの実行環境でも処理内容に応じて設定を分けて設定を行いました。(Standard、Large、High-Memoryなど用途に応じて使えるように。)
コンテナの実行環境の設定は、Sparkに限らずデザインノードとAutomationノードの両方に設定をする必要があるので若干面倒な手順でした。
7.Setup and Manage Audit Trails, Event Server
イベントサーバーの設定を行うハンズオンです。
この設定を行うことで各DSSの監査ログをためることができます。
今回のハンズオンではAutomationノードやデザインノードのログを、デザインノード上に書き込む設定を行いました。
その他にもログの保管場所はS3を設定することもできます。
イベントサーバーについての詳細はこちらのドキュメントを参照してみてください。
8.Automating Projects_Macros & Senarios
シナリオを用いていくつかの処理を自動化するハンズオンです。
ログ消去のマクロを設定しました。プロジェクトを作成してシナリオを作成します。
シナリオのステップから、マクロの実行を選択して行いたい処理を選択します。
今回は、ジョブログの削除やプロジェクトに構築した使われていないNotebookの削除設定、業務時間外にクラスタを自動停止するステップなどの設定を行いました。
また、シナリオのトリガーをtimebasedのものにすることでバッチ処理の設定が可能です。
ただし、契約しているプランによってはデザインノード上ではシナリオは2個までしか有効かできないため
3つ以上のシナリオを有効化したい場合はAutomationノード上のプロジェクトでシナリオを有効化する必要があります。
また、APIを利用することでシナリオを実行させることも可能です。
DSSとは別の環境でPythonからシナリオ実行のAPIを叩く形にすればデザインノード上でも3つ以上のシナリオを実行させることが可能なので運用時には検討してみてもよさそうです。
9.Monitor DSS, Disk Usage & Usage Reporting
イベントサーバー上に溜まったログをDataikuのダッシュボード上で可視化するハンズオンです。
CPUの使用率などの各種メトリクスを可視化できるような設定を行いました。
ダッシュボードは一から構築することも可能ですが、すでにダッシュボードが準備されているプロジェクトを選択して作成したほうが効率が良いとのことで
今回のハンズオンでは新しいプロジェクトを選択し、Dataiku Solutionの中にある「Data Resource Usage Monitoring」のテンプレートを利用しました。
プロジェクトのセッティングからAuditingの項目を選択し、作成したイベントサーバーとのコネクションを設定しました。
正しく設定を行うことで、ダッシュボードの画面から監査ログが見れるようになります。
詳細はこちらを参照してください。
10.Using the Dataiku Public API
DataikuのAPIを使ってDSSの操作を行うハンズオンです。
ハンズオンではPythonを利用してAPIを実行するため、プロジェクトにNotebookを作成してコードを実行しました。
ユーザーの作成をAPI経由で行うことができました。
API経由だとユーザー削除などの重要な処理の場合でも確認するステップもなく実行されるので注意が必要です。
その他コード環境の更新の自動化や追加ユーザーに対するプロジェクトの権限付与など実運用時に活用できる内容などがありそうでした。
Pythonを経由したAPIの項目はこちらを見てみてください。
DSS外部環境からAPIを叩く場合はこちらを参照してみてください。外部から呼び出す場合はデザインノードのプライベートIPやポート番号の情報が必要とのことでした。
11.Upgrading Fleet Manager
FleetManagerのアップグレードを行うハンズオンです。
手順としてはFleetManagerを一度バックアップしてから、最新版で作成してリストアをかけるようなイメージです。
詳細な手順はこちら。
オンプレ環境でDSSを構築する場合はこちらのアップグレードを行う機会は多いと思うので、詳細な手順を理解しておく必要があります。
12.DSS Backeups and Recovery
DSSのバックアップとリカバリを行うハンズオンです。
FleeetManager上で各ノードのスナップショットを取得する設定が可能です。そのスナップショットをもとにリカバリーも可能です。
こちらも細かい内容なため詳細はドキュメントに記載されているので確認ください。
13.Troubleshooting in Dataiku
Dataikuのトラブルシューティングを行うハンズオンです。
基本的にはJobログの見方やサポートにログを提出する際のダウンロード手順などについて学びました。
学んだこと
今回のイベントの参加するにあたり、正直不安が不安が結構ありました。
というのも参加の事前条件が結構しっかりと書かれていて、その要件を私が満たしているか正直微妙なところもあったからです。
また、Dataikuの資格はいくつか取得していましたがアーキテクチャについてもよくわからなかったので
事前準備でいろいろと設定しているとよくわからない単語がいろいろあって焦りました。(FleetManagerとか何なのかわかってなかった)
ただ、添付のドキュメントを読むことで理解は進められたので良かったです。
トレーニングを通してDataiku全体の理解や具体的な導入時に検討すべき事項などについて学ぶことができました。
また、後日ハンズオンを実施した対象者にむけてのAdmin Examがありましたがそちらも無事に合格することができました!
(合格証などがもらい次第こちらにもアップしようと思います。)
弊社ではDataikuのパートナーとして導入や活用の支援を行っております。
導入をご検討の方がいましたらお気軽にお問い合わせください。





