やしろです。
今日はDATA CLOUD WORLD TOUR TOKYOが絶賛開催中すね!
私も朝から参加していますが、Snowflakeのイベントは相変わらず熱気がすごいですねー!
こちらの様子は後日、参加メンバーからガシガシご紹介する予定です。
そして最近は、Snowflakeの新機能、Streamlit in Snowflakeのパブリックプレビューがまだか?まだか?とずっとそわそわしています。
それに向けて?社内ではStreamlit熱がとても高まっており、30DaysOfStreamlitに取り組むメンバーが続々増えています。
私も取り組んだ内の一人ですが、ついつい写経メインになってしまったので自分で色々表現したいなと思い、まずは弊社の展開しているPODBのデータを可視化してみました。
PODBについて
Prepper Open Data Bank、通称PODBとはtruestarがSnowflakeデータマーケットプレイスに展開しているサービスです。
e-Statで公開されている国勢調査などの商用・二次利用可能なオープンデータを、プレップ無しですぐにデータ分析ができるようtruestarが抽出・加工して無料で提供しています。
Snowflakeアカウントさえあればどなたでも無料ですぐにご利用できるので、このStreamlitアプリも簡単に試していただけます!
詳しくはこちらの専用HPを御覧ください。
今回使用したデータは、この日本の鉄道区間のデータになります。
Streamlitについて
StreamlitとはPythonでwebアプリを簡単に構築できるフレームワークのことです。
Pythonコードだけで実装できるので、早く手軽にアプリを作成できる、というのが大きな特徴です。
さぁ、それでは早速可視化してみましょう!
1.環境を構築する
まずは環境構築からです。
※使用PCはwindowsです。Macは操作が異なる箇所があるのでご注意ください。
私は今回Anacondaを使用しています。
Anacondaは、Pythonのプログラムを実行する「処理系」に加えて、AIやデータ分析に関連する多くの「ライブラリ」や、開発に役立つ各種の「ツール」を同梱しているソフトウエアです。
Anacondaの設定について今回は割愛させていただくので、詳細はPython JapanのHPをご確認ください。
Anacondaの初期設定が完了したら、新しい環境を作成しましょう。
Anacondaで以下のコマンドを実行します。
conda create -n <新しい環境名> python = 3.10

環境が作成できたらアクティベートします。
conda activate <新しい環境名>

アクティベートできたら、今回のアプリに必要なライブラリをインストールしておきましょう。
conda install snowflake-connector-python
conda install steramlit
conda install pandas
conda install plotly
コマンドはcondaでもpipでもOKです。どちらもパッケージ管理システムですが、pipはPythonパッケージに特化したシステムです。
必要なのは上記のパッケージです。
Snowflakeとの接続は、Python用Snowflakeコネクタを使用しています。
Streamlitと一緒にpandasやplotlyも使用するのでそれぞれインストールしておきましょう。
最後に、今回実行するPythonファイルを保存するための作業用フォルダを、任意のディレクトリに作成しておきましょう。
参考までに、私は以下のように作成しています。
![]()
2.Pythonシートを作成・編集する
作成したディレクトリに、Streamlitを記述するためのPythonシートを準備しましょう。
Pythonファイルを編集するためのエディタはサクラエディタなどのテキストエディタでも大丈夫ですが、Visual Studio Code(VSCode)などのIDE(統合開発環境)と言われるソフトを使うと編集しやすいです。
私はVSCodeを使用しているので、今回はVSCodeの画面での操作方法をご説明します。
細かい初期設定については、長くなってしまうのでこちらをご確認ください。
1.VSCodeを開いて、左上の”File”タブから”Open Folder…”をクリック、先ほど作成した作業用フォルダを開きます。
フォルダ名の右にあるボタンから、New Fileを選択します。
任意のファイル名に.pyを付けて保存すると、pythonファイルとして保存されます。
今回は"streamlit_blog.py"というファイル名にして保存しました。

2.いよいよコードを書いていきたいと思います。
まずは使用するライブラリのインポートからです。
先ほどインストールしたライブラリたちを使っていくので、こちらにも明記しておきましょう。
import streamlit as st
import pandas as pd
import snowflake.connector
import plotly.graph_objects as go
import json今回取得するgeoデータがGeoJSON形式なので、jsonもimportしています。
また、マップの可視化にplotlyのgraph_objectを使用しています。
次に、Snowflakeからデータを取得するための関数を記述していきます。
def
fetch_data(): # fetch_data関数の定義
# snowflakeへの接続
conn1 = snowflake.connector.connect(
user=st.secrets["snowflake"]["user"],
password=st.secrets["snowflake"]["password"],
account=st.secrets["snowflake"]["account"],
warehouse=st.secrets["snowflake"]["warehouse"],
database=st.secrets["snowflake"]["database"],
schema=st.secrets["snowflake"]["schema"]
)
# SQLクエリの定義
geo_data = """
select railway_line_name,polyline_railway from polyline_railway_01
"""
# クエリの実行
cursor = conn1.cursor()
cursor.execute(geo_data)
#データベースからのデータ取得が完了したら、カーソルと接続を閉じる
rows = cursor.fetchall()
cursor.close()
conn1.close()
# データフレームの作成
df = pd.DataFrame(rows, columns=['railway_line_name', 'polyline_railway'])
return df
# fetch_data関数を呼び出して、結果をdfに保存
df = fetch_data()
上記のコードで、Snowflake上にある”polyline_railway_01”の"railway_line_name"と”polyline_railway”カラムにアクセスしています。
Snowflakeへの接続情報は直接シートに記述してもいいのですが、機密データに当たるため別途管理するのが理想です。
そこでsecrets.tomlファイルというものを作成、またpythonシートと同じディレクトリ下に.streamlitフォルダを作り、その配下に保存します。

secrets.tomlの記載内容はこんな感じです。
[snowflake]
account = "account" #"https://ooo.snowflakecomputing.com"のoooの部分
user = "user" #Snowflakeのユーザー名
password = "password" #Snowflakeのパスワード
role = "role" #使用したいロール
warehouse = "warehouse" #使用したいウェアハウス
database = "database" #使用したいデータがあるデータベース
schema = "schema" #同スキーマデータを取得できたら、次はGeoJSON形式の文字列で格納されている”polyline_railway”カラムを解析します。
def extract_coordinates(json_str): #extract_coordinates 関数の定義
try:
# JSON形式の文字列をPythonの辞書に変換
json_data = json.loads(json_str)
# coordinatesキーの値を取得し、緯度と経度のリストをそれぞれ作成して、それを含む
coordinates = json_data.get("coordinates", []) # 仮のデフォルト値
latitudes = [coord[1] for coord in coordinates]
longitudes = [coord[0] for coord in coordinates]
# 緯度と経度のリストを含むPandasシリーズを返す
return pd.Series((latitudes, longitudes))
#"json.JSONDecodeError"タイプのエラーが発生した時、空のリストを返す
except json.JSONDecodeError:
return pd.Series(([], []))
# DataFrameに新しい列を追加
df[['Latitudes', 'Longitudes']] = df['polyline_railway'].apply(extract_coordinates)
# 不要な列を削除
df.drop(columns=['polyline_railway'], inplace=True)
ここで行っている処理はJSON形式の文字列データをパースしてデータを抽出、新たに"latitudes"と”longitudes”というカラムに整理する、という工程です。
この新たなカラムを使って、データを可視化していきます。
# Plotlyオブジェクトの生成
fig = go.Figure()
# データフレームの各行(各鉄道路線)をループ処理・緯度と経度の座標を取得
for idx, row in df.iterrows():
latitudes = row['Latitudes']
longitudes = row['Longitudes']
railway_line_name = row['railway_line_name']
# 各ポリライン(トレース)をオブジェクトに追加
fig.add_trace(go.Scattermapbox(
mode='lines',
lon=longitudes,
lat=latitudes,
line=dict(width=3),
name=railway_line_name # 凡例の名称を設定
))
# マップのレイアウト設定
fig.update_layout(
mapbox=dict(
style='stamen-terrain',
zoom=12,
center=dict(lat=35.68, lon=139.76)
),
margin=dict(l=0, r=0, t=0, b=0),
width=800, # ここで図の幅を設定
height=600 # ここで図の高さを設定
)
# Streamlitで表示
st.title("日本の鉄道")
st.plotly_chart(fig)
ここではループ処理で各行(つまり各ポリライン)を描画する処理と、マップのレイアウトを設定しています。
add_traceでポリラインを描画させています。
凡例を表示させたかったので、"railway_line_name"カラムを使用してトレースの名前も設定します。
最後に、st.titleでタイトルを表示、st.plotly_chartでポリラインを描画します!
以上でコードの記述は完了です!
3.アプリを実行する
コードが書き終わったら実行です!
現在の環境が今回作成した仮想環境であること、現在いるのがpythonファイルのあるディレクトリであることを確認してください。
VScodeの場合、画面右下で確認できるので、もし別の仮想環境にいる場合はここをクリックして変更してください。

streamlitを実行するコマンドは”streamlit run”コマンドです。
![]()
実行してみると…
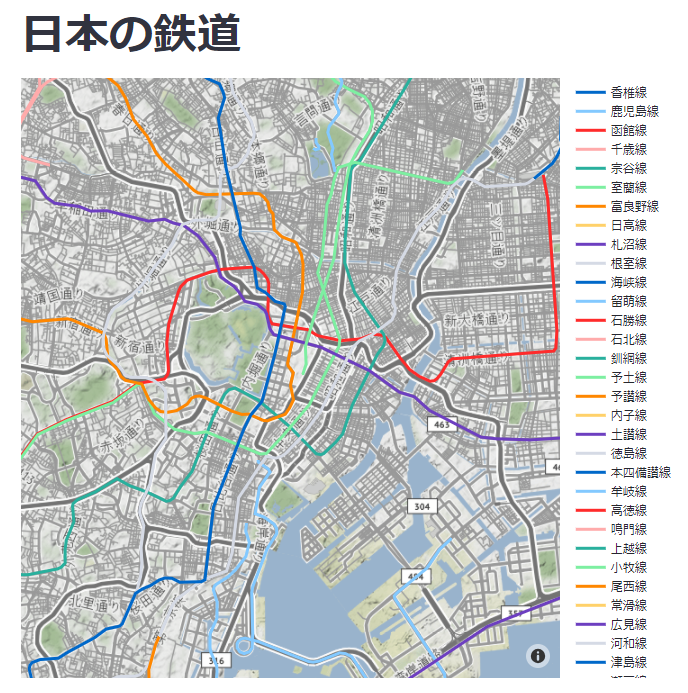
こんな感じで可視化されました!
タイトルとマップ、ちゃんと凡例まで表示されていますね。
ちなみに、凡例の路線名をクリックすると選択した路線がハイライトされるようになってます。
おわりに
今回はシンプルにマップを可視化したアプリですが、もちろん複数のグラフの表示やフィルターアクションなど様々な機能を追加していくことが可能です。
まだまだ勉強中の身なので、またいろいろ試してご紹介したいと思います!
Streamlit in Snowflakeのパブリックプレビュー、早く来い来い!
これまでのSnowflakeに関する記事はこちら