Truestarの三村です。
はじめに
TwitterとSnowflakeを連携させて、「つぶやけば処理が走る仕組み」をご紹介いたします。
例えば。。。
userAが 「#Mission1…」とつぶやく → Snowflakeのテーブルにつぶやき情報が入る → タスク管理されたストアドが検知し、テーブル更新や再計算処理(Mission1)を行う・・・
という感じです。これなら携帯さえあれば、いつでもどこでも仕事の命令を出せますね。
この仕組みを利用して、分析用に使いやすく加工したオープンデータを共有する Prepper Open Data Bank を、Snowflakeの正式なアカウントがなくてもお試しいただけるようにしています。
是非下記サイトも合わせてごらんください。
Prepper Open Data Bank トライアル用アカウント作成方法
仕組み説明
では、その仕組みについて 弊社の取り組みを例に ご説明いたします。
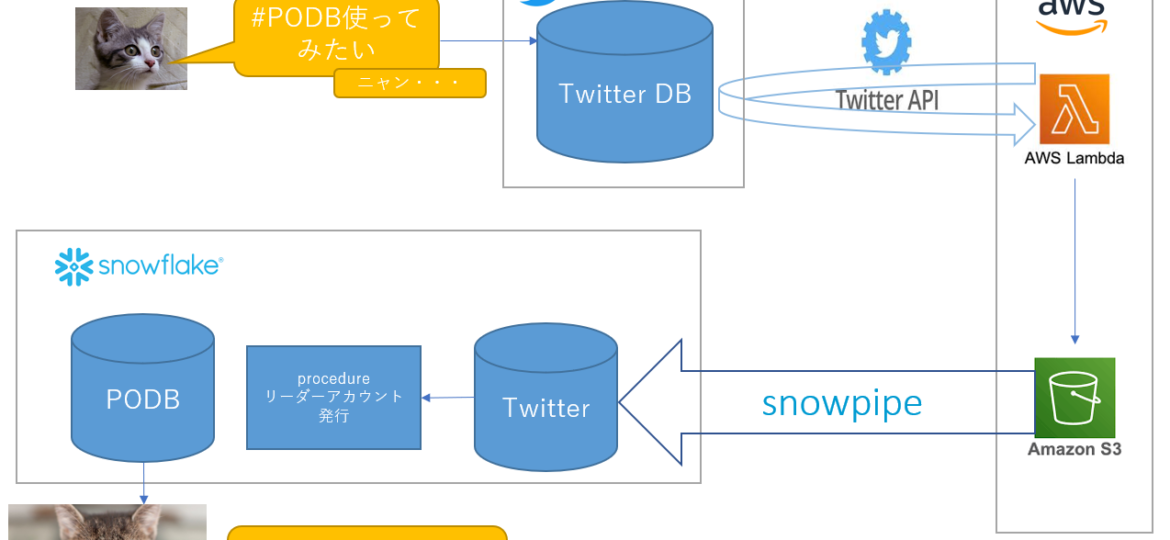
全体の概略図を記します。
①#PODB使ってみたい とつぶやくとTwitterのDBに蓄積されます。
②AWSのLambdaに、TwitterAPIを使ってTwitterDBからデータを取得してS3に格納するプログラムを置き、定期的に起動するように設定します。
※TwitterDBからデータを取得し、S3に格納するプログラムを載せます。よろしければ参考にしてください。
# --- coding: utf-8 ---
import tweepy
import boto3
from datetime import datetime
### Twitter API KEY
Consumer_key = 'XXXXXXXXXXXXXXXXXXXXXX'
Consumer_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
Access_token = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
Access_secret = 'XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX'
### TwitterAPI認証用関数
def authTwitter():
auth = tweepy.OAuthHandler(Consumer_key, Consumer_secret)
auth.set_access_token(Access_token, Access_secret)
api = tweepy.API(auth, wait_on_rate_limit = True) # API利用制限にかかった場合、解除まで待機する
return(api)
def printS3(s):
s3 = boto3.resource('s3')
bucket = 'XXXXXXXXXXXXXXX'
key = 'test_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') + '.csv'
file_contents = s
obj = s3.Object(bucket,key)
obj.put(Body = file_contents)
return
### Tweetの検索結果を標準出力
def printTweetBySearch(s):
api = authTwitter() # 認証
tweets = tweepy.Cursor(api.search_tweets, q = s,# APIの種類と検索文字列
include_entities = True, # 省略されたリンクを全て取得
tweet_mode = 'extended', # 省略されたツイートを全て取得
result_type="mixed",
).items()
p = 'id,created_at,screen_name,name\n'
for tweet in tweets:
p += str(tweet.id) + ',' # tweetのIDを出力。ユニークなもの
p += str(tweet.created_at) + ',' # 呟いた日時
p += str(tweet.user.screen_name) + ',' # ユーザー名
p += str(tweet.user.name) # アカウント名
p += "\n"
print('==========')
print('twid : ',tweet.id) # tweetのIDを出力。ユニークなもの
print('date : ',tweet.created_at) # 呟いた日時
print('user : ',tweet.user.screen_name) # ユーザー名
print('user : ',tweet.user.name) # アカウント名
#S3出力
printS3(p)
def lambda_handler(event, context):
text = '#PODB使ってみたい'
printTweetBySearch(text)
None③S3 → Snowflakeの内部ステージング → テーブル へ転送されるように、Snowpipeを作成します。
--クラウドストレージ統合を作成
CREATE OR REPLACE STORAGE INTEGRATION S3_role_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = S3
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::XXXXXXXX:role/snowflake_role'
STORAGE_ALLOWED_LOCATIONS = ('s3://ts-snowpipetest/')
desc integration S3_role_integration;
--S3バケットを参照する外部ステージ(ステージエリア AWSSTAGE)を作成
create or replace stage awsstage
url = 's3://ts-snowpipetest/'
storage_integration = S3_role_integration;
--自動インジェストを有効にしたパイプを作成
create or replace pipe twitter.public.awspipe auto_ingest=true as
copy into twitter.public.TARGET_TWEETS_Lambda
from @twitter.public.awsstage
file_format = (TYPE = CSV skip_header = 1)
--セキュリティ
use role securityadmin;
create or replace role S3_role;
grant usage on database twitter to role S3_role;
grant usage on schema twitter.public to role S3_role;
grant insert, select on twitter.public.TARGET_TWEETS_Lambda to role S3_role;
grant usage on stage twitter.public.awsstage to role S3_role;
grant ownership on pipe twitter.public.awspipe to role accountadmin;
grant role S3_role to user MIMURA;
alter user MIMURA set default_role = S3_role;
--------------------------------------------------
--ここまででパイプ設定完了
--内部ステージの確認
LIST @twitter.public.awsstage
--内部ステージからファイルを削除 ここを消すとAWSのS3からも消える
REMOVE @twitter.public.awsstage
--パイプを開始 このタイミングではステージに滞留しているファイルをコピーしない。次のイベントでコピーする。
ALTER PIPE twitter.public.awspipe SET PIPE_EXECUTION_PAUSED=falseSnowpipe については次のドキュメントをご覧ください。Snowpipeの紹介
④ストアドプロシージャで、データベースのテーブル内容を確認し、他テーブルに再計算して格納する等のビジネスロジックを実行します。
弊社の取り組みでは #PODB使ってみたい とつぶやいた方に、Snowflakeのリーダーアカウントを発行して 弊社のサービスである OpenDataを参照できるようにしています。
この仕組みについては、Snowflakeプロダクトマーケティングマネージャーの KTさんから直々に教えていただきました。
(丁寧に教えていただき、ありがとうございました!)
KTさんのサイトで詳しくご説明されています。
【完全公開】Twitter投稿した人を自動的にSnowflakeへ登録して、イベント参加者にデータベースアクセスできるようにするスクリプト
ーー 追記 ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
KTさんから教えていただいたタスクを※サーバーレスにして実行したところ、なんとクレジットが…見えない…(笑)
(実行時間 降順です)
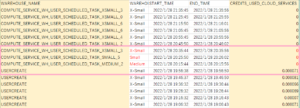
実際は、0.000000 の表示でした。Excelに貼り付けたので 0 になっています。きっと小数点第 X 位には数字が入っているでしょう(笑)
※サーバーレス
create or replace task タスク名
USER_TASK_MANAGED_INITIAL_WAREHOUSE_SIZE ← このオプションを指定しない
2022/02/17 大安吉日
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
以上で 「つぶやけば処理が走る仕組み」が完了です♪
TwitterDBからデータを取得し、S3に格納し、SnowpipeでSnowflakeまで持ってくる作業は、Snowflake Partner Connect の MATILLION を使うと、より簡単にできます。
概略図を以下に記します。
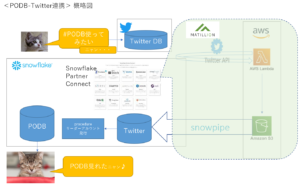
AWSでの処理やSnowpipeを意識することなく、Snowflake Partner Connect の MATILLION の設定だけで Twitterデータを取得できるので、より楽にできますね。
いかがでしたでしょうか? Snowflakeを使っての業務構築は、是非弊社にご相談ください♪