ロジスティック回帰か?ランダムフォレストか?
こんにちは、truestarのuchiです。
唐突ですが、ある事象(従業員の離職など)が起きるかどうかを予測するようなモデルを作成するときに、ロジスティック回帰(統計的手法)とランダムフォレスト(機械学習)、どっちを使えばよいのかな、と悩むことはありませんか。
先日参加したExploratory社のデータサイエンスブートキャンプでそれぞれの手法の特徴についてとても分かりやすく学べたので、実際に試してみたいと思います。
その前に・・データサイエンスブートキャンプって??
truestarがデータ分析のツールとしてよく使用するExploratory。そのExploratory社が定期的に開催している、統計・データ分析・機械学習の基礎を体系的に学べる講座です!興味のある方はこちらをチェック
ロジスティック回帰とランダムフォレストの比較
それぞれの得意なこと・苦手なことは(とても)ざっくりとまとめると以下です
| ロジスティック回帰 | ランダムフォレスト | |
| 得意 | ・他の説明変数の影響を除いた、ある説明変数単体での目的変数への影響度がわかる ・結果にどんな要素が影響しているのか?の分析に向いている |
・線形でない関係も捉えられる ・多重共線性があっても予測はできる |
| 苦手 | ・線形の関係しか捉えられない ・説明変数間に多重共線性があるとうまく分析ができない |
・説明変数同士の影響は考慮しない |
※参考:Exploratory データサイエンスブートキャンプ#20 Days2トレーニング
今回は赤字で強調した、「線形の関係」に注目してみます。
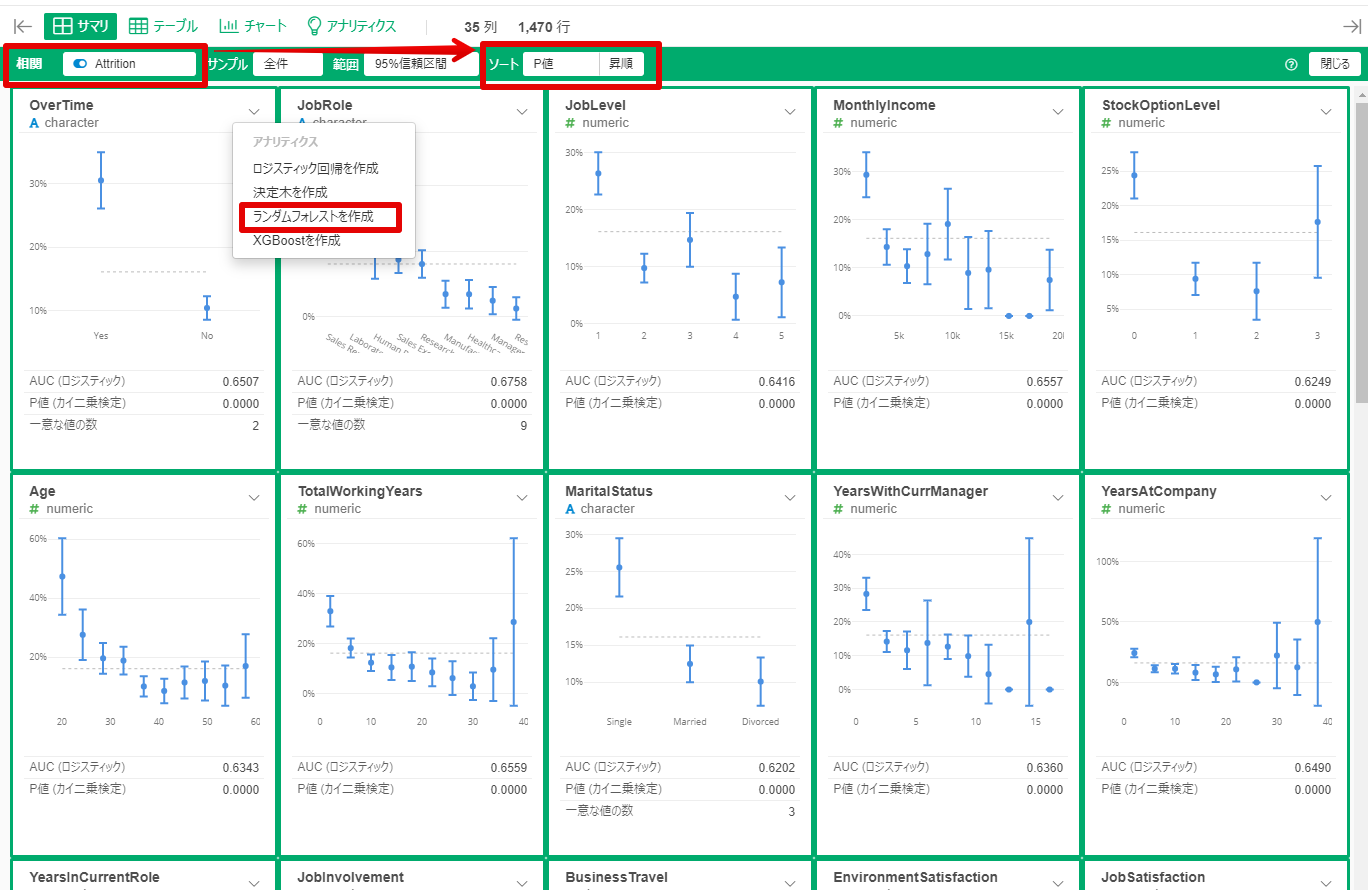
例として、従業員の離職有無を目的変数にした予測モデルを、ロジスティック回帰とランダムフォレストで作ってみました。
*使用データ:「従業員の離職(Attrition)についてのフィクションデータ」by Kaggle (https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset/data)
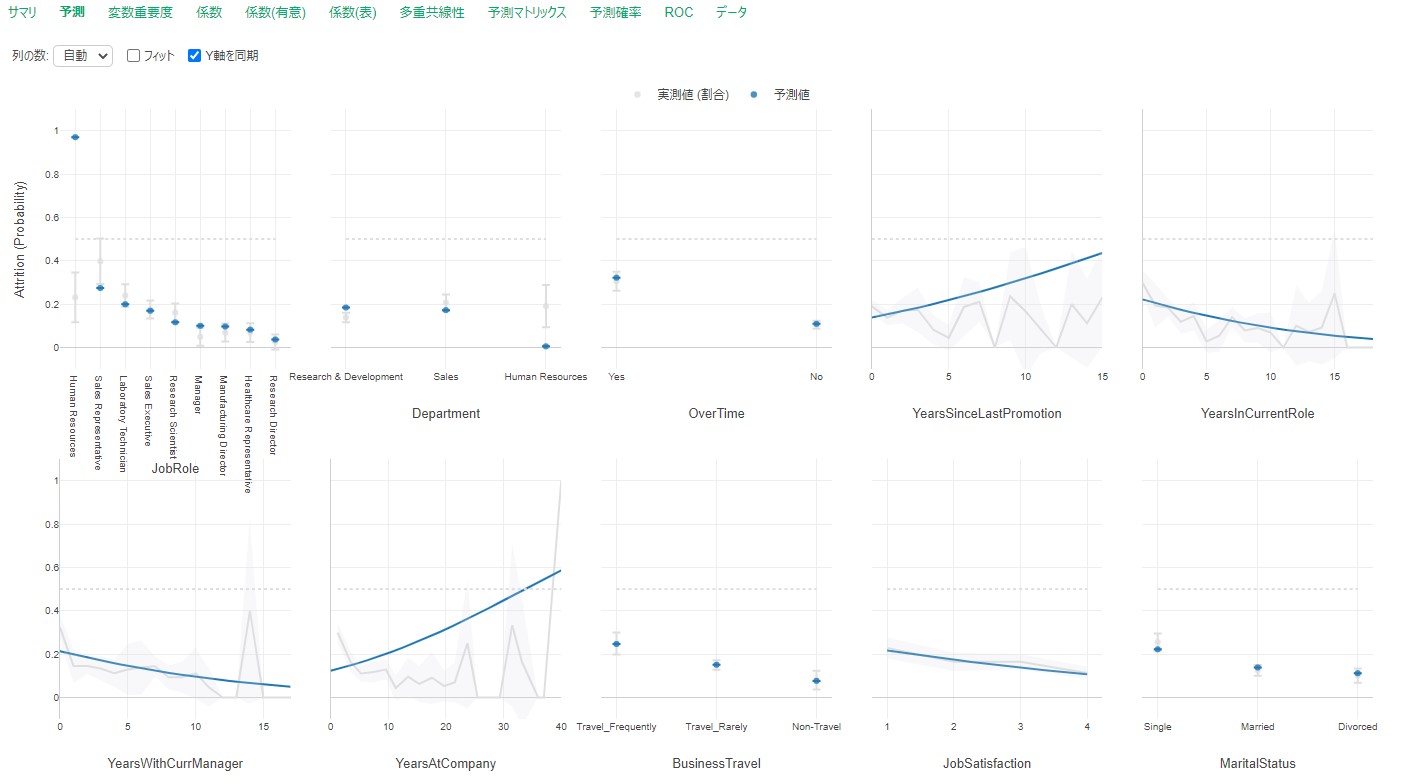
Total Working Years(勤続年数)と離職率の関係をみたとき、勤続年数が40年近くになると急に離職率が高まる(おそらく定年退職)のですが、この特徴をランダムフォレストはちゃんと捉えています。
ランダムフォレスト

ロジスティック回帰
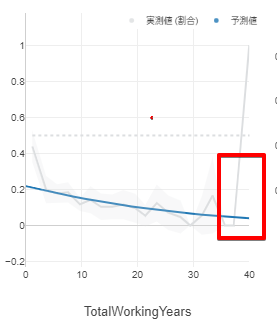
今回のように、あるポイントを超えると目的変数への影響が強くなる、という一般的な特徴がある場合は、ランダムフォレストの方がその傾向を捉えた精度の高いモデルを作成してくれます。
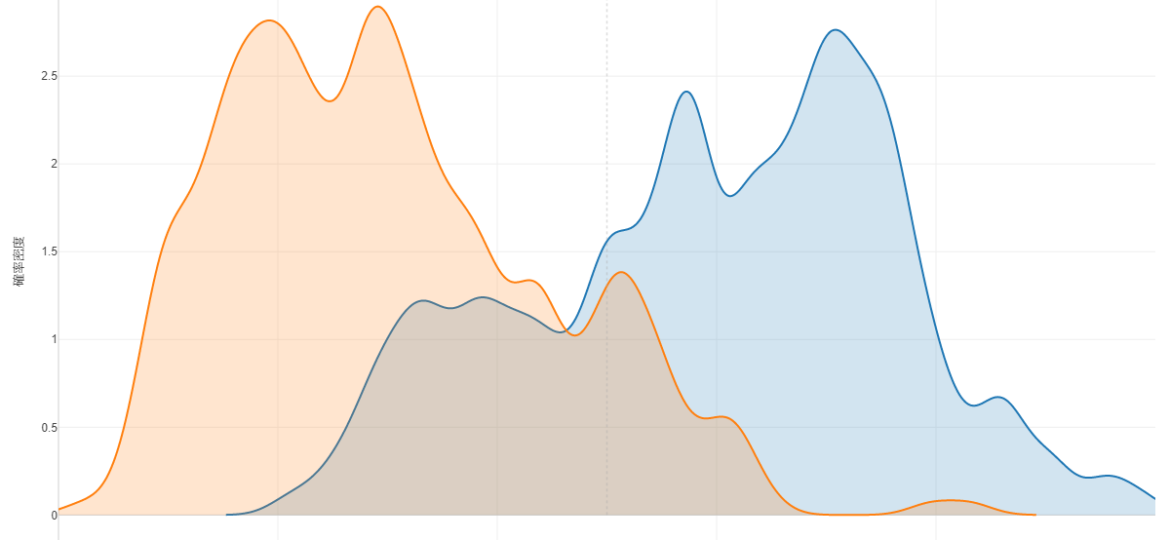
実際にモデルの予測精度比較もしてみます。これはAUCという指標から見られます。1に近いほど精度がよいです。
ランダムフォレスト

ロジスティック回帰

今回の予測ではランダムフォレストの方が精度が高そうです。
反対に、トレーニングデータでたまたまそういう傾向があっただけの場合、ランダムフォレストではそのたまたまの特徴をよくとらえた予測モデルを作ってしまうので、汎用的なモデルとしての精度は落ちてしまうかもしれません。ランダムフォレストのAUCが、トレーニングと比較してテストで0.1程度落ちているのはそのためです。
まとめ
予測モデルを作るには、予測の目的やデータの特徴を踏まえて手法を選択する必要があります。Exploratoryは様々な手法での解析や結果の比較がとても簡単にできるので、最適なモデルを選定するための考察により多くの時間を割けてとても便利です・・!
truestarではこの他にもExploratoryを使ってさまざまな分析・予測を行っています。これからも紹介記事を更新していきます!