ゲスト寄稿2回目のひめのです。アドベントカレンダーにお邪魔します!
今回のテーマはtableau 2022.3から追加になった表拡張機能です。(テーブル拡張とも言うらしい)
これまでのtabpyとの違いと、作成していて躓いたところなどをtipsとして書きたいと思います。
はじめに
表拡張機能を使うには拡張機能の設定とtabpyを起動しておくことが必要です。
設定方法はこちらにありますのでよろしければ拙筆ですがご覧ください。
Rでも使えますが、今回はpythonで実行しています。スクリプトの書き方などが違います。
データはtableauを開くとプリセットで表示される「World Indicators」のデータをcsvでローカルに保存したものを使っています。
新機能!表拡張!
表拡張機能を使ってみて個人的なイメージはこんな感じです。
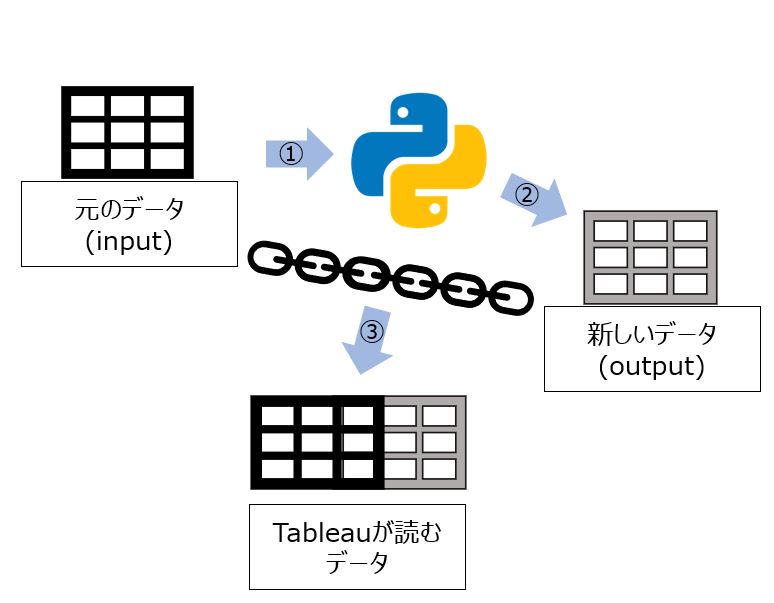
元のデータ(今回はWorld Indicators)を加工して、元のデータに結合しています。
必ずしも元のデータと結合するデータの素は同じではないみたいですが、別ソースはまたの機会に試したいと思います。
データ画面は最終的にこのようになりました。
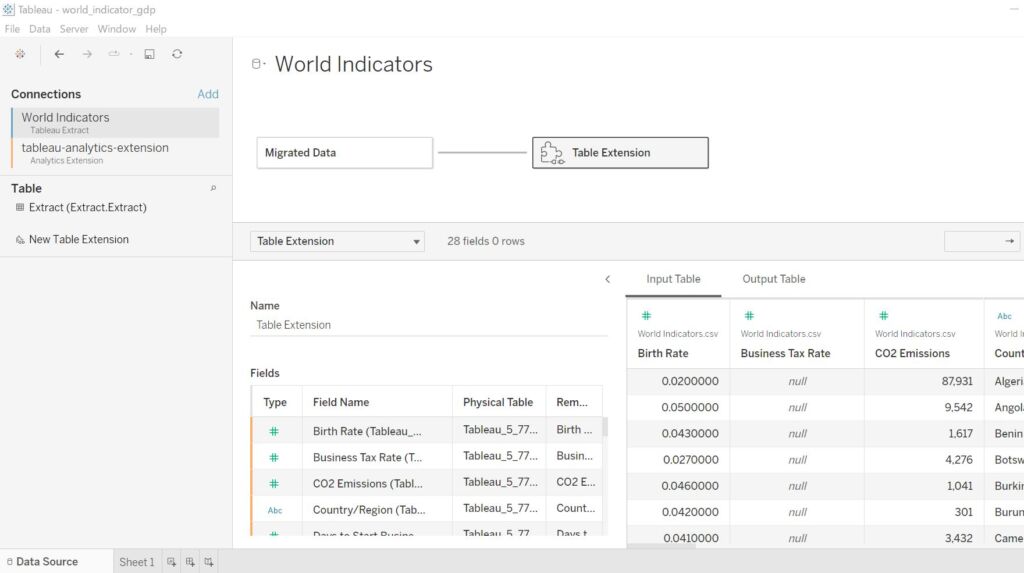
最終的に結合させる必要があるので、キーになるようなものを新しいデータ(output)側にも残したり、
結合の方法を念頭に新しいデータを作成するのがおすすめです。(だいぶ私は回り道もしました・・・)
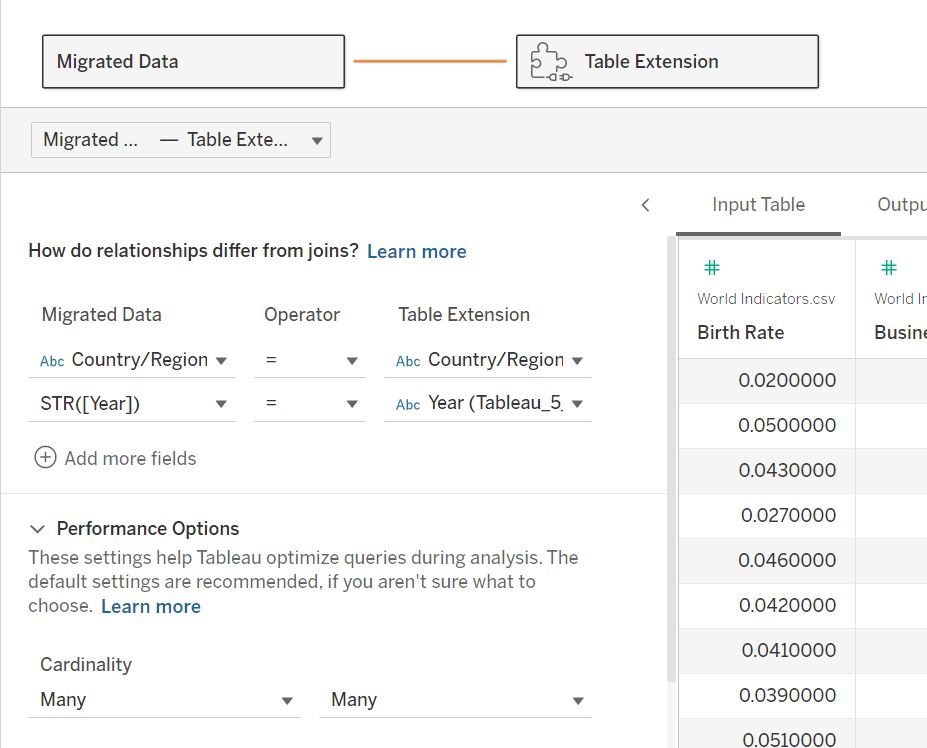
つないでいる線をクリックすると接続方法のより細かい設定も可能です。
今回は2フィールドで結合しています。
表拡張機能を使ってみよう!
まずはいつも通りデータソースに接続します。
csvを選択するといつもの画面に移行しますが、下の方に見慣れないものが…

「New Table Extension」をダブルクリックします。

今回は先ほどinputしたcsvをpythonで加工するので同じcsvを「Drag tables here」に持っていきます。
(ここで別テーブルを選択しても、ユニオンにしたりしてもいいみたいです。)
ドラッグしたら先ほどと同じデータが入りました。
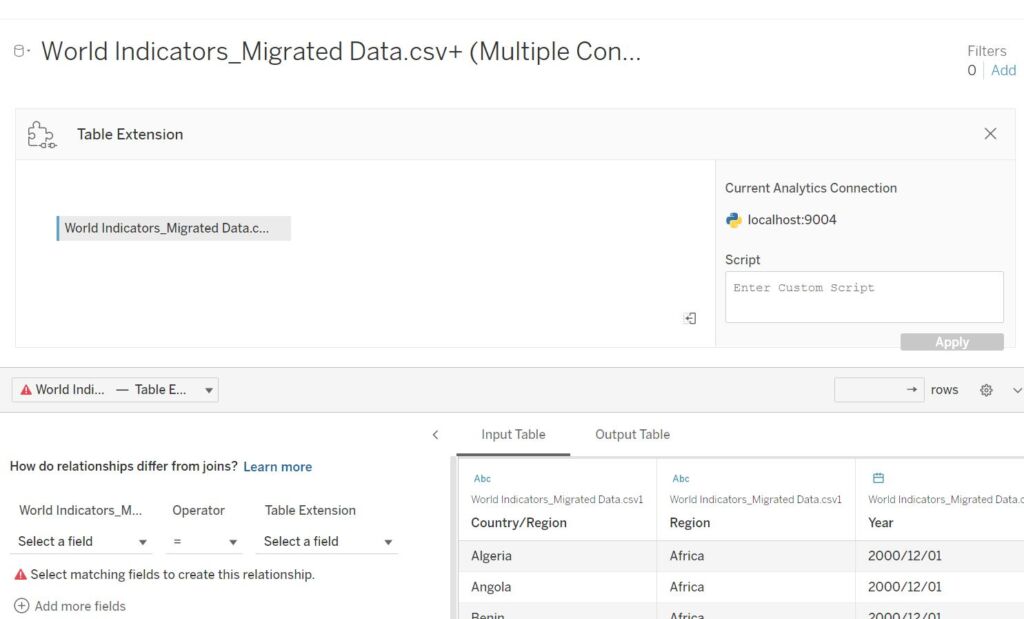
このデータを元にpythonで加工しましょう。
表拡張でLinear Regressionしちゃおう
スクリプトを「Script」の枠に入力します。
tabpyのお約束がいくつかあるので後にまとめて記載します。
まずはサンプルスクリプトです。
# ライブラリのインポート
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 表拡張のお約束その①
df = (pd.DataFrame(_arg1))
# 今回は目的変数をGDPにします
df_na = df.dropna(subset=['GDP'])
df_na.reset_index(inplace=True)
t = df_na['GDP']
# 説明変数を適当に絞る
x = df_na[['Birth Rate', 'Energy Usage', 'Population Total', 'CO2 Emissions', 'Tourism Inbound', 'Tourism Outbound', 'Mobile Phone Usage', 'Infant Mortality Rate']]
# あまりよろしくない手段かもしれませんが、とりあえずnanを0で埋める
# 本当は正規化とかも入れた方が良いと思う
x = x.fillna(0)
# データを分割する
x_train, x_val, t_train, t_val = train_test_split(x, t, test_size=0.3, random_state=0)
# モデル作成
model = LinearRegression()
model.fit(x_train, t_train)
pred = model.predict(x)
# 出力するテーブルを作成
y = pd.DataFrame(pred, columns=['predict'])
results = pd.concat([df_na, y], axis=1)
# 表拡張のお約束その②
return results.to_dict(orient='list')出来上がったら「Apply」ボタンを押します。
joinのキーを指定します。今回はCountry/RegionとYear(日付型なのでstrで文字列に変換が必要)にしました。
するとOutput Tableができ…………………ないんだな、これが。

このエラーが何回でも出ます。バグなのかエラーコードで調べても何も出ませんでした。(2022年11月1日現在)
だがしかし、ここまでの内容を名前を付けて保存し、開きなおすとなぜかエラー出なくなります。もっと良い回避方法見つけたいです…
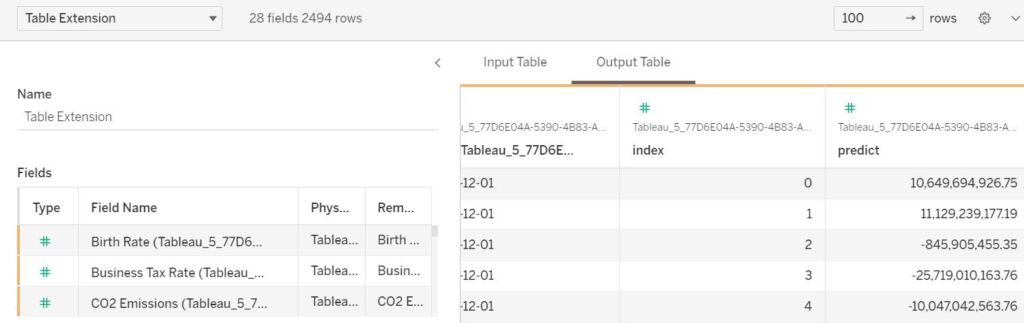
twbファイルを開きなおしてOutput Tableを見るとしっかり追加したかった「predict」の列が追加されているのを確認できます。
結果をvizにしよう
今回のLinearRegressionの精度がどれくらいだったのか確認する散布図を作ります。
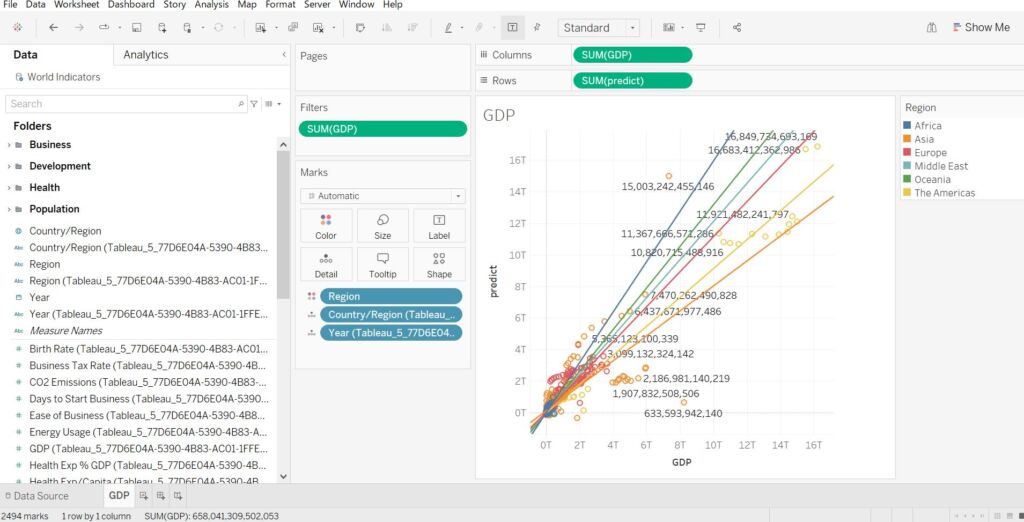
メジャーやディメンションの名前の後ろにTableau_……とめちゃくちゃ長い名前がついているものは表拡張由来の列です。
参考にしたブログに書いてあったのですが、表拡張で都度hyperが作成されているそうです。
表拡張を使ってみることを優先しすぎて予測値がマイナスになっている部分もありますがご容赦ください…
データリレーションを設定する必要もない(事前にやってるからなんですけど)のでそのままほいほいvizが作れます。
オセアニアの予測精度は良いけど、アメリカ大陸はいまいちだな~とすぐにわかります。
お約束事&tips
まず表拡張のお約束事です。
- pandasのデータフレームとしてインプットファイルを読み込む
- to_dictして結果をreturnする
まずデータフレームとして読み込む必要があります。
従来のscript関数で使用していた_arg1です。(pythonの場合)
df = (pd.DataFrame(_arg1))script関数でもreturnが必要でしたが、dictで返す必要があるので最後にはこのような1文が入ります。
return results.to_dict(orient='list')次にtipsです。
- エラーが出ても焦らない!まずは保存して閉じよう。
- 表拡張を複数twbで同時作業するのはおすすめしない
- script関数と書き方違うから気を付けよう
- プレビュー列は700までの制限がある
- 相対的な列指定はできないかも
上にもあるようにしょっちゅうエラーポップアップで出ますが、閉じて開きなおすと問題無くなります。なぜだ…
一応保存してあるかだけ確認しましょう。
表拡張を2ファイルで同時にいじっていたらPCのメモリ消費が100%になってしまいました。一度に作業するのは1ファイルにしましょう。
_arg1が出てきたりreturnを含める必要がありますが、それ以外はpythonの書き方です。script関数よりシンプルですがややこしいので注意です。
誤ったデータ操作の結果、3000列くらいになったのはプレビュー表示ができず、700までしかプレビューできません、と表示されました。
あとやっているうちに気付いたのですが、ilocが使えませんでした。列を名称で指定すると上手くいったので、相対的に列を指定するのがいけないのかもしれないです。
従来のtabpyとの違い
従来のtabpyはデータソースを読み込んだ後の表に新しく列を追加するイメージだったのに対し、
新しい表拡張では別のテーブルを結合させて新しいデータソースを作るイメージです。
例えばあるメジャーAとBの相関係数を求めようとしたとき、
従来のscript関数ではフィルターを適用させて表示されているデータポイントに絞った相関係数を計算できます。
(tabpyで相関係数を計算する方法はこちらのブログをご覧ください)
表拡張で相関係数を計算して列(メジャー)を追加した場合、すでに計算されている状態からフィルタをかけて再計算、ということはできません。
データ加工・整理の一環としてメジャーを予め追加しておきたいときは表拡張の方が良い気がしています。
またモデルをデプロイし、パラメータで入力値を変化させてシミュレーションをする、ということもscript関数ではできました。
(この内容もいつかブログ化したいと思います)
パラメータはデータソースに後から追加するものなので、表拡張では使用できなさそうです。
これからも新しい機能が追加されそうでtableauはますます楽しみですね!
皆様、メリークリスマス!そして良いお年をお迎えください!