初めまして!東京科学大学(旧東京工業大学)・修士2年の Ito Yusei と申します。
現在はtruestarのインターン生として、アプリ開発や、一部社内システムの保守・運用を任されています。
本記事では、Snowflake Native App 開発プロジェクトの一環として、SnowflakeのMarketplace上で近日公開予定の気象データ紐づけアプリをご紹介します。
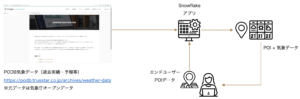
PODB気象データを活用したエンドユーザー向けアプリ
オープンデータを基にした「PODB」では、気象庁が展開する気象データに基づき、過去実績や予報を共有しています。
https://podb.truestar.co.jp/archives/weather-data
しかし、エンドユーザーのニーズは、単に観測所(AMeDAS)のデータにとどまらず、自社のPOI(Point of Interest)に特化した気象データの利用が求められています。
例えば、渋谷駅の過去気象データを知りたいとしましょう。気象庁は渋谷駅にAMeDASを持ちません。よって、渋谷駅の住所に最も近いAMeDASを探す必要があります。渋谷駅のみであればまだ一回調べるだけで終わりますが、たくさんの住所データを持つエンドユーザーにとってこの作業は非常に手間となります。
現在のPODBの提供形態では、このような個別のニーズに対応するにはある程度のコーディングが必要であり、利用のハードルが高い状況です。そこで、Snowflakeアプリを活用し、Web上でUIに沿ってボタンを押すだけでエンドユーザーのPOIに最適化された気象データを提供するアプリを作成しました。現在はプロトタイプを開発中なので、さらにブラッシュアップして年明けに本番アプリを有償でリリース予定となっています。
操作方法
①前準備
それでは、早速アプリを動かしていきましょう!本アプリでは上記の通り「住所データをもつテーブル」をエンドユーザーが持っている前提なので、もしそのようなデータをお持ちでない方は以下のSQLクエリをSnowflakeのworksheet上で実行して、サンプル住所テーブルを作成してみましょう!
-- サンプル住所テーブルを作成
CREATE OR REPLACE TABLE <DB_NAME>.<SCHEMA_NAME>.SAMPLE_ADDRESS (
ADDRESS VARCHAR,
METADATA VARCHAR);
-- サンプル住所テーブルに住所とデータの特徴を挿入
INSERT INTO <DB_NAME>.<SCHEMA_NAME>.SAMPLE_ADDRESS (ADDRESS, METADATA)
VALUES
('東京都港区芝公園4-8-1', '普通の住所'),
('大阪府北区', '町丁目名がない'),
('東京都', '市区町村名と町丁目名がない'),
('静岡県浜松市天龍区二俣町二俣481番地', '異体字が含まれる'),
('東京都新宿区四ツ谷', '表記揺れがある');2列目に使われているMETADATAの意味については、後ほど説明します。
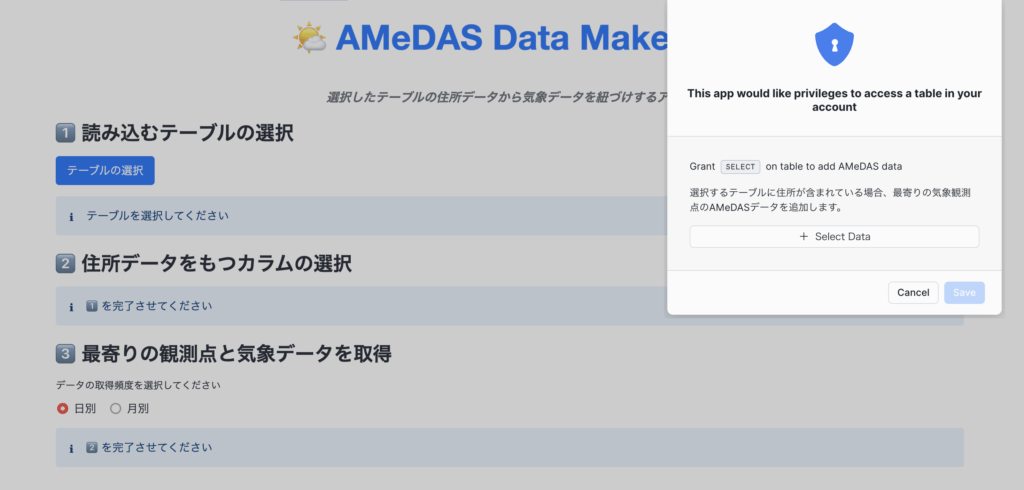
②住所テーブルを選択
初期画面のUIに従ってまずは気象データを紐づけたい住所データを含むテーブルを選択しましょう。今回は、先ほど作成したSAMPLE_ADDRESSテーブルを使っていきます。ちなみに勝手にアプリ名を「AMeDAS Data Maker」と名付けましたが、まだ正式名称は決まっていません。


③住所データを含む列を選択
今回は「ADDRESS」列を選択します。
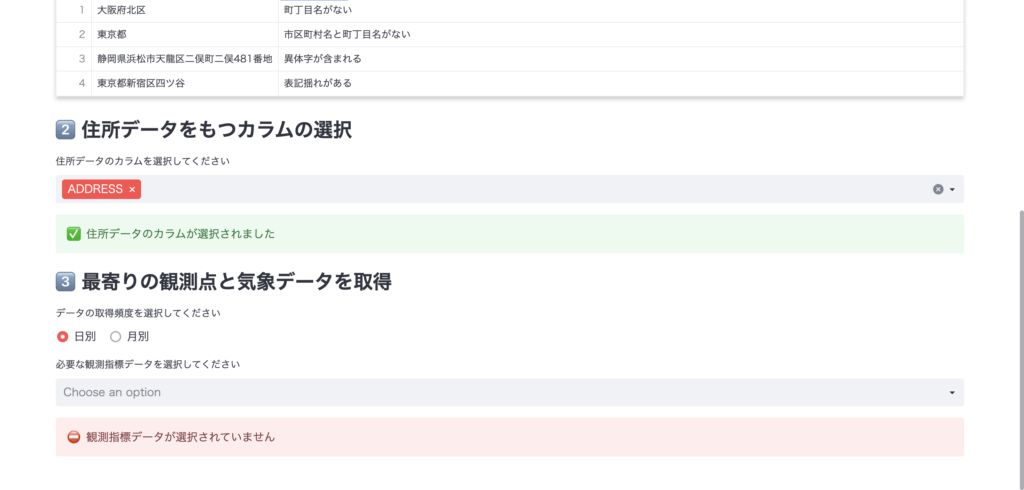
④いよいよ実行!
データの取得頻度を選択できます。日別と月別があるので、今回は日別を選びます。
結果が見やすいように、2024年元旦のデータのみ取得してみましょう。
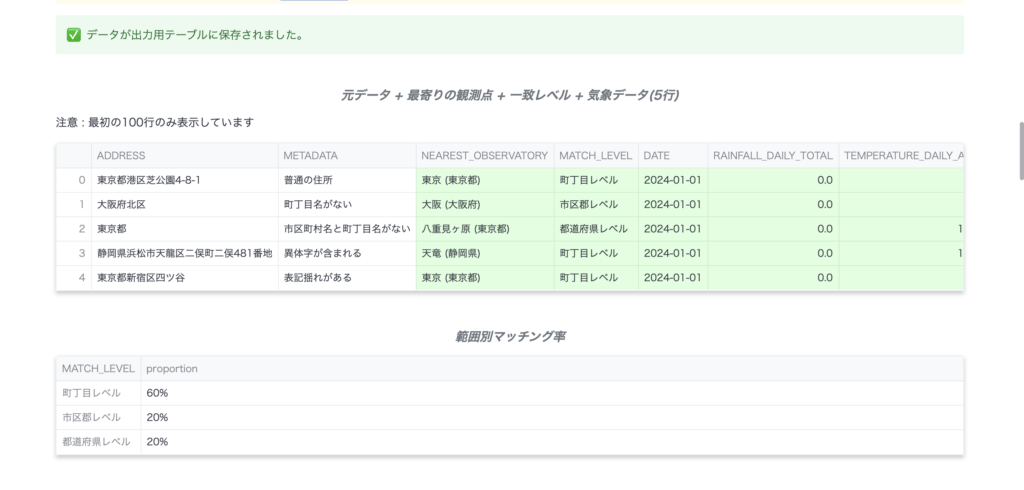
選択した観測指標と日付がしっかりマッチしていることが分かりますね!
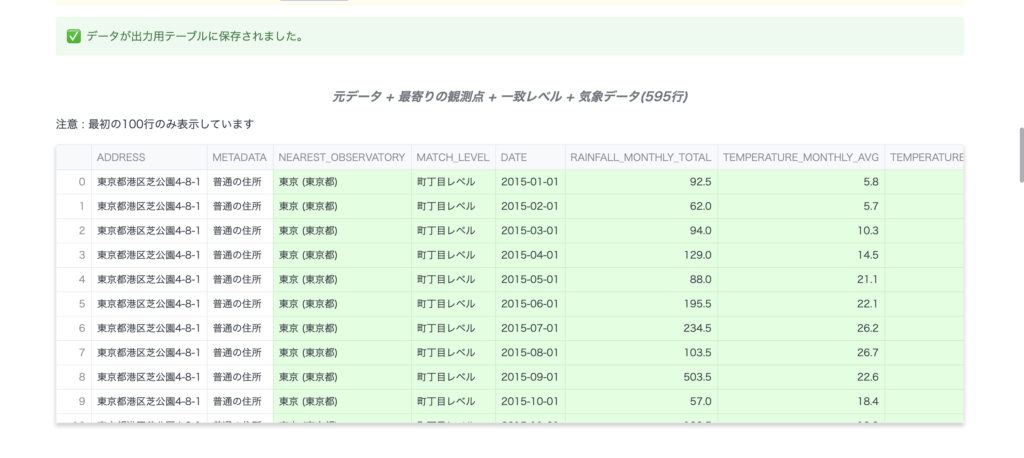
せっかくなので月別データもとってみましょう。こちらは、現在取得できる最大量のデータ(2015年1月~2024年11月の119ヶ月分)を指定してみます。
日付は全て1日になっていますが、しっかり月別の統計量がとれていることがわかります。

アプリ上では100行までしか表示されませんが、オリジナルの住所データや取得する気象データの指定日数によって、実際に得られるデータ量は100行を超えます。全体のデータテーブルを取得したい場合は、アプリ最下部に表示されているSQLクエリをSnowflakeのWorksheet上で実行しましょう。
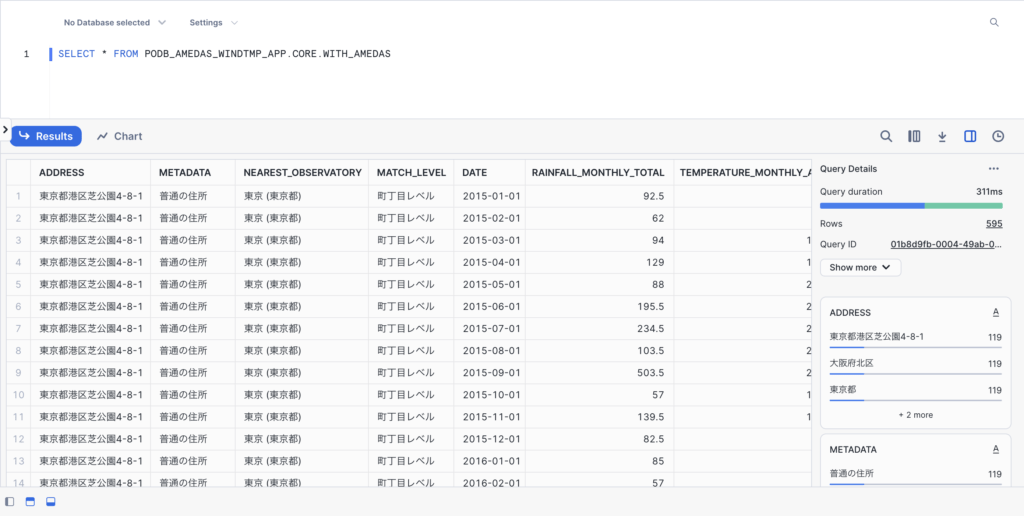
5行×119ヶ月=595行、しっかり取れていますね!👏
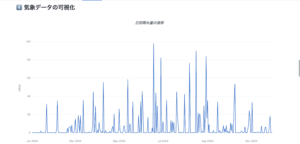
気象データの可視化
最後におまけ要素として、注目した住所に追加された気象データの時間推移を見ることができます。今はテストアプリ段階なので、先頭行のレコードのみ可視化していますが、今後エンドユーザーが指定したレコードの気象データ可視化もできるようになる予定です。以下の画像は東京都港区芝公園の2024年日別降水量の推移です。やはり梅雨や台風の多い夏秋は多く、乾燥した冬は少ないですね。イメージ通りの結果です!
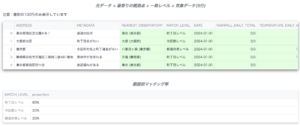
一致レベルとは
さて、ここまでアプリの仕様を一通り見てきて何か忘れた気になっていないでしょうか?
そうです。サンプル住所データにわざわざ入れた「METADATA」ですよね。実はこれは、アプリ内のUIに存在する「一致レベル」という項目を説明するために入れているのです。
そもそも、エンドユーザーが持っている住所データは「不完全な」場合が多いです。
例えば、東京都渋谷区東3丁目9-19 VORT 恵比寿 maxim 8F は完全なtruestarのオフィス住所ですが、これのどこかが欠けている場合や、「霞が関」と「霞ヶ関」、「国分寺」と「國分寺」のように、データによって表記揺れがある場合でも、ある程度は住所を正しく認識したいわけです。
そこで、住所を①都道府県、②市区郡、③町丁目というように大まかに3等分します。番号が大きいほど細かい住所になるわけですが、どのレベルまで細かく住所を解析できたのかを表示したものが、一致レベルなのです。表記揺れに関しても、あらかじめ旧字と新字の対応リストを作っておいて、旧字が来ても新字に調整しています。
ここでもう一度先ほどの日別データのおさらいをしてみましょう。METADATAの列と一致レベル列を照らし合わせてみると、その関係がとてもよくわかると思います。その下には全データの中でどの一致レベルがどのくらいの割合存在するのかを示した範囲別マッチング率も表示されています。
ちなみにこういった住所の分解作業のことを「正規化」と呼びます。開発者向けにこのロジックとそれに付随するプログラミングコードについては別の記事で紹介する予定です。
まとめ
いかがでしたでしょうか?今回は気象データ紐づけアプリについて、その機能と操作方法を簡単に紹介しました。やはりGUIを活用することで、エンドユーザーにとってハードルの高いプログラムを組むことなくデータの加工をできるようになる点は、Snowflake Native App の大きな強みといえます。
今後も引き続き、このような「ノーコーダー・ローコーダーに優しいデータ加工ツール」を開発・リリースしていく予定なので、ぜひご期待ください!
ちなみに、本記事でしたアプリの説明を圧縮したものを実はアプリ内で見ることができます。右上のインフォメーションマークから「Readme」というアイコンが出ますので、もしこの記事の内容を忘れても安心ですね。(まだアプリは公開されていないので、公開後にインストールしたらぜひお試しください!)

それではみなさん、良いデータライフを!