こんにちは、ひめのです。
DataikuからSnowflakeに出力することはよくあるかと思いますが、
Application designerを使ってフローを実行したり、
ワークスペースにインスタンスを立てるとSnowflakeのテーブル名がそれぞれ設定されます。
今回はその命名規則のご紹介です。
通常のフローからのテーブル
プロジェクト名がBLOG_EXAMPLEのプロジェクトを作成して、
Snowflakeにblog_exampleというテーブルを書き込むことにします。
書き込む際にConnectionを選択します。
Connectionの設定でSnowflakeのどのデータベース、どのスキーマかは選択してあります。
フローを実行するなどしてテーブルをBuildするとSnowflakeのデータ一覧に表示されるようになります。
Connectionがexample_databaseという名前のデータベース、スキーマがexample_schemaで作成されていた場合、
example_databaseの下のexample_schemaの中に
BLOG_EXAMPLE_BLOG_EXAMPLEというテーブルが作成されます。
階層としてはEXAMPLE_DATABASE/EXAMPLE_SCHEMA/BLOG_EXAMPLE_BLOG_EXAMPLE
のようになります。
一般化すると以下のようになります。
[DATABASE_NAME]/[SCHEMA_NAME]/[PROJECTNAME][DATASET_NAME]
テストインスタンスからのテーブル
Application designerで作成したApplicationの途中経過を確認するためにテストインスタンスを立ち上げることができます。
テストインスタンスに関してドキュメントが見つけられていないのですが、チュートリアルのこの部分に記載があります。
よし、この内容でばっちり!と思ってテストインスタンスに移っても確認してみたらちょっと直したい…ということはよくあると思います。
(実際は私はそんなことばっかりで何回もやり直しをしています)
テストインスタンスを立ち上げると、その時点でのプロジェクトの内容をテストインスタンスにコピーするイメージです。
テストインスタンスで確認してこの部分を変えたい、と思ってテストインスタンス内で変更しても元のプロジェクトには反映されません。
なので、
プロジェクトが状態AでテストインスタンスAを立てる
↓
ミスを見つける
↓
プロジェクトを直す(状態Bになる)&テストインスタンスBを立てる
↓
ミスがあったら再修正
という流れを繰り返すのですが、テストインスタンスAとテストインスタンスBはIDが異なります。
プロジェクトのIDがBLOG_EXAMPLE_XXXXXXXXのように英数字8桁が末尾につきます。
このID付きのテーブルがSnowflakeには書き出されます。
例えばEXAMPLE_DATABASE/EXAMPLE_SCHEMA/BLOG_EXAMPLE_XXXXXXXX_BLOG_EXAMPLE が誕生しています。
一般化すると[DATABASE_NAME]/[SCHEMA_NAME]/[PROJECT_NAME]XXXXXXXX[DATASET_NAME] です。
IDはランダム生成なので、テストインスタンスAのIDはAAAA1234で、BのIDは98XYZ123だったりするのです。(適当です)
あくまでテスト用なので、このテーブルをStreamlitなどで参照するのはおすすめできません。
また、テストインスタンスを何回も立て直してやり直しをすると別名のテーブルがSnowflakeに大量発生することになります。
ランダム生成なIDが含まれていて、不要なテーブルは削除するようにしましょう。
ワークスペースに立てたインスタンスからのテーブル
IDがランダム生成されてしまうようなテーブルは本番稼働には適していません。
テストインスタンスで確認し、求めているものが出来上がったらワークスペースに移します。
ワークスペースに関してはDataikuの解説があります。
ここで先ほどまでApplication designerで操作していたものをApplicationとして確定させます。
先にワークスペースを作成しておきましょう。DSSのホームから追加できます。
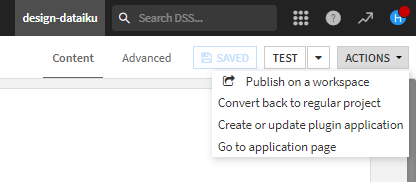
一番上のPublish on a workspaceで作成しておいたワークスペースに作成します。
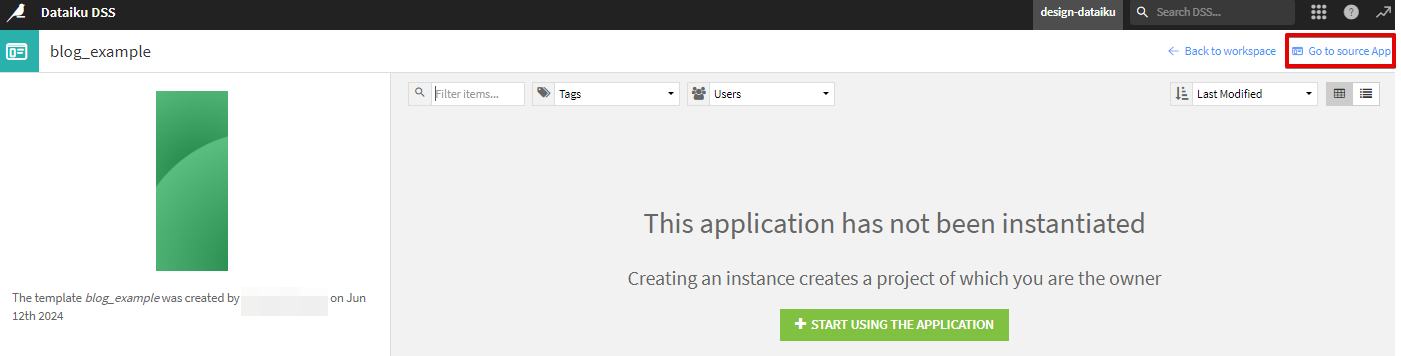
ワークスペースから今回のプロジェクト(私の例だとblog_example)を選択し、
右上のGo to source Appをクリックします。
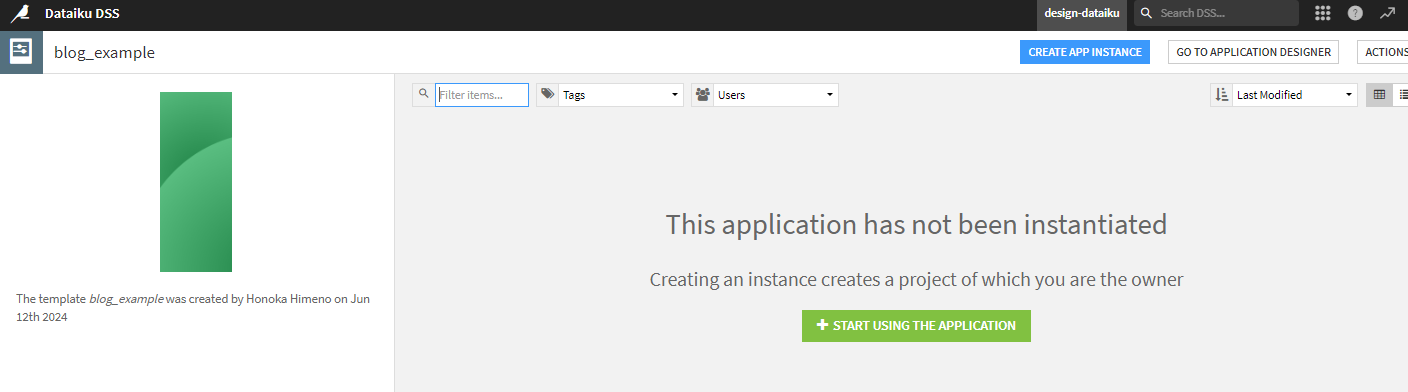
ここで[CREATE APP INSTANCE]を押します。
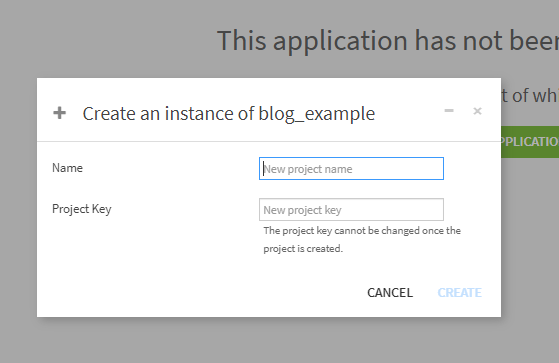
Nameを入力するとProjectKeyが自動で作成されますが、自分で修正もできます。
NameはDataikuのワークスペース上に見える名前ですが、Snowflakeのテーブル名に入ってくるのはProject Keyです。
Project Keyは被ることができません。
ただし、以前使ったことがあってもインスタンスを消して再作成する場合は使いまわしができるようです。
(実験しました)
これでできあがったインスタンスから書き出したテーブルは以前のプロジェクト名を継承していないので
一般化すると [DATABASE_NAME]/[SCHEMA_NAME]/[NEW_INSTANCENAME][DATASET_NAME] になります。
インスタンスまで出来上がった段階で、例えばStreamlitからテーブルを参照するときは
NEW_INSTANCE_NAMEが入ったテーブル名を指定するようにすると
このあと元のプロジェクトを直したり、誤っていじってしまった場合でも影響されません。
元のプロジェクトを直して、インスタンスにも反映させたいときは作り直しになります。
まとめ
通常のフローからのテーブル
→ [DATABASE_NAME]/[SCHEMA_NAME]/[PROJECTNAME][DATASET_NAME]
テストインスタンスからのテーブル
→ [DATABASE_NAME]/[SCHEMA_NAME]/[PROJECT_NAME]XXXXXXXX[DATASET_NAME]
ワークスペースに立てたインスタンスからのテーブル
→ [DATABASE_NAME]/[SCHEMA_NAME]/[NEW_INSTANCENAME][DATASET_NAME]
※[DATABASE_NAME]と[SCHEMA_NAME]はConnection作成時に設定します。
参考になれば幸いです!
truestarでは、Snowflake導入検討、導入支援や環境構築まで幅広くサポート可能です。
Snowflakeに゙興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらから相談ください!
また、truestarではSnowflake Marketplaceにて、加工済みオープンデータを無償提供するPrepper Open Data Bank、全国の飲食店の情報を集めたデータセットの販売を行っております。(サービスリンク)
これまでのSnowflakeに関する記事はこちら





