こんにちは、truestarのk.takahashiです!
最近streamlitで半構造化データの演習をしていた際、
Snowflakeでの半構造化データの仕様を調べたため今回は一般知識編、
次回は実践編として記述したいと思います。
半構造化データとは
半構造化データとは、リレーショナルデータの表構造に従わないデータになります。
リレーショナルデータと比較して違いを確認しましょう。
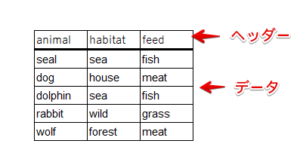
リレーショナルデータ
リレーショナルデータの表構造とは馴染み深い、CSVなどの形式です。
ヘッダーがあって、各カラムのデータ型に対応した要素が含まれている。
他の形は例外として認めない形式となります。
半構造化データ
一方で半構造化データは、構造化データと非構造化データのハイブリッドになります。
要するに、記述のルールはある程度存在するけど、列の並びやデータの入れ方にリレーショナルデータほど構造を厳密に求めないデータになります。
JSONを例にとると、Keyとvalueがペアになっている構造で各値が格納されています。
この形はカラム名と値の関係に似ていますね。

一方で、"animal": "dolphin”の属性情報として"habitat”や"feed”をネストして持たせてもJSONとして機能します。このように半構造化データは記述のルールに則れば柔軟なかつ複雑な構造を持つことができ、ユースケースに合わせて変形させやすいためAPI間のデータの受け渡しなどには重宝されているデータになります。

Snowflakeの半構造化データサポート
Snowflakeでは主に、JSON、Avro、ORC、Parquet、XMLの半構造化データをネィティブでサポートしています。
つまり、サポートしている半構造化データは一度Snowflake上のTABLEに取り込んでしまえばリレーショナルデータと同様の扱いができるということになります。(この点がELTとして使い勝手が非常に良いポイント、、、!)
データ型としてはARRY、OBJECT、VARIANTがサポートされており、データ型を意識しないVARIANT型が重宝されています。
– ARRAY
可変長の配列。例えば[1. 2. 3.] のように配列されたデータをカラムに格納する
– OBJECT
KeyとValueを対応させた型{“id”:1, “animal”:”dolphin”, “habitat”:”sea”,”feed”:”fish”}のような半構造化データをカラムに格納する
– VARIANT
標準SQLに加えてARRY、OBJECTの両対応の型。基本これを使用すればいい。ただし1行あたり最大60メガバイトまでの圧縮データしか保持できないので注意。
半構造化データのロード
半構造化データのロードはステージに上げ、テーブルにCOPY INTOをするといった
基本的に他のデータと変わらない順序を踏みます。
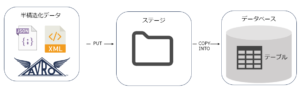
異なる点は各半構造化データに対応するために、ファイルフォーマットを指定する必要があります。
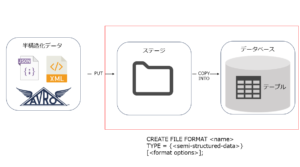
ロードの具体的な流れ
具体的な記述は次回に回しますが、ここでは大まかな流れとSTEP①②のサンプルコードを記載いたします。
簡易的なステップとしては、以下の通りになります。
①ファイルフォーマットをして
②ステージを準備して
③SnowSQLからアップする
/* TABLE_AであらかじめVARIANT型で用意 */
USE ROLE ACCOUNT ADMIN;
USE Warehouse DEMO_WAREHOS;
USE DATABASE DEMO_DB;
USE Schema TEST;
CREATE TABLE or REPLACE TABLE_A(
V VARIANT
);
/* ファイルフォーマットを指定 */
CREATE FILE FORMAT JSON_DATA_LOAD
TYPE = 'JSON'
COMPRESSION ='AUTO'
ENABLE_OCTAL =FALSE
ALLOW_DUPLICATE = FALSE
STRIP_OUTER_ARRAY = TRUE
STRIP_NULL_VALUE = FALSE
IGNORE_UTF8_ERRORS = FALSE;
/* ファイルをステージングさせる場所を用意 */
CREATE STAGE IF NOT EXISTS
JSON_STAGE FILE_FORMAT = JSON_DATA_LOAD;
LIST @JSON_STAGE;最後に
半構造化データ、特にJSONは半構造化データの標準になっているので適切な扱い方を理解したいですね。
次回は実際にSnowflake環境でJSONデータをアップさせたいと思います。
それでは。