
こんにちは、ひめのです。
DataikuのApplication designerでノンコーダー向けインターフェースが組めたので、
次はノンコーダー向けにアウトプットの形を考えたいと思います。
データの分析+データ管理+アウトプットを合わせて「データ分析アプリ」と呼ぶことにします。
今回アウトプットは分析したデータの可視化をしたダッシュボードを作ろうと思います。
(最近弊社内ではSnowflakeとともにStreamlitのブームも来ています。)
やってみて難しかったことや限界も見えてきたので、まだまだ完璧とは言えませんが、
データを分析して終わり、ではなく意思決定などに活用できるような形まで一気通貫で作ってみたレポートです!
概要
ざっくり今回のイメージを図にします↓
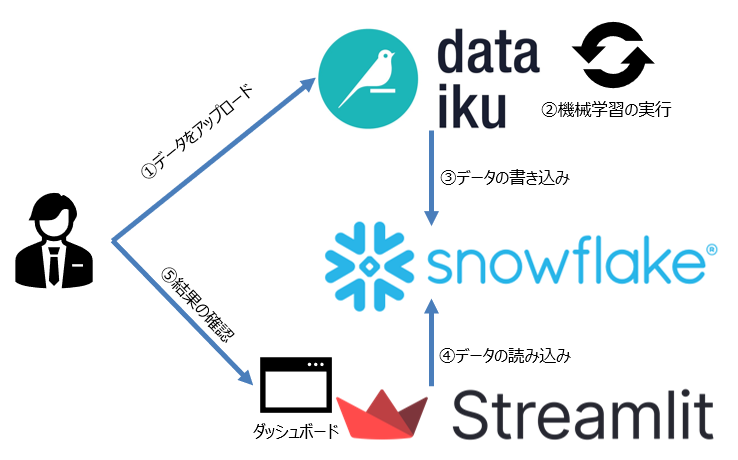
ユーザーはDataikuのApplication designerで作成したインターフェースにデータをアップロードし、
ちょっと待つ(機械学習が実行されてアウトプットのデータが更新される)と
ダッシュボードが更新されて今回のデータで分析した結果が出てくる、という仕組みです。
ユーザーにはダッシュボードを見て次のアクションを考える、などのタスクに集中してもらって
機械的に楽できるところは徹底的に自動化してしまいましょう!
Dataiku
機械学習のレシピや、コードレシピで処理したアウトプットのデータを出力します。
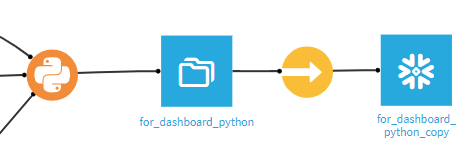
↑
この例ではPythonコードレシピからデータセットを出力し、SyncでSnowflakeに書き出してます。
試行錯誤が終わったら中間のデータセットとSyncをなくして直接Snowflakeに書き込んでしまっても良いと思います。
中間ファイルをSnowflakeに一気に書き込まないでDataikuのマネージドファイルにしておくことで
無駄なSnowflakeの処理(=課金)を避けつつ、フローの他の部分でも使いやすくしています。
Snowflakeとの接続(クラウド版Dataiku)はこちらのブログをご参照ください。
※注意
DataikuからSnowflakeに書き込む際にインスタンス名が自動でテーブル名にくっつきます。
インスタンス名(フローから作成した場合はプロジェクト名)→instance、指定したテーブル名→table、だった場合、
Snowflakeに作成されるテーブルは「instance_table」になります。
アプリケーションデザイナーを使用して出力した場合、
テストインスタンスや、名前を付けて作成したインスタンスの名前が付くことになります。
テストインスタンスはアップデートの度にIDが変わります。
同じテーブルを上書きしたつもりでも別テーブルが作成されていることがあるので確認が必要です。
例:テストインスタンスからSnowflakeに書き込むとinstance_abcdefgh_tableみたいになる。
何がまずいかと言うと、Streamlitで参照するテーブルを上書きしたいのに、別で作成されてしまうと
ダッシュボードが自動で更新されなくなるのです。
おすすめはある程度仕様を固めて、テストインスタンスとは別のインスタンス(例えばapp)を作成し、
インスタンス名付きのテーブル(instance_app_table)をSnowflakeで使用することです。
別のインスタンスを作成した場合、テストインスタンスをアップデートしても内容が反映されないので
ある程度仕様を固めておかないとプロジェクトの本筋で変更した内容を別のインスタンスでも再度
変更しないといけなくて面倒です…
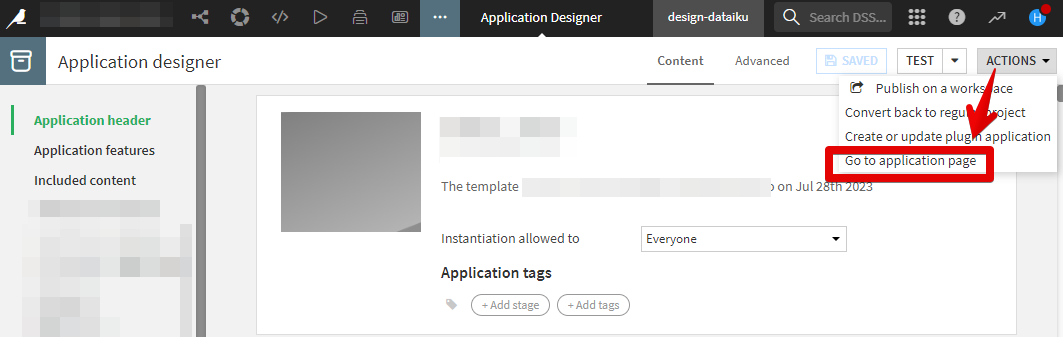
ACTIONS→Go to application pageを選択します。
CREATE APP INSTANCE で新しくインスタンスを作成します。
インスタンスという言い方をしていますが、新しくノードを立てたりしているわけでは無いそうです。
めちゃくちゃ課金が増えるわけではないそうなので、間違えて作ってしまっても消せば大丈夫です。
Streamlit (in Snowflake)
Streamlitアプリの作り方はこちらの記事をご参照ください。
SnowflakeにおいてあるStreamlitからSnowflakeのデータにアクセスするためにセッションを作成するのですが、
Streamlitの.pyファイルがあるところ以外に接続するのはできないようです。
そこで、以下のコードでセッション情報を取得し、どこを参照しているのか確認します。
from snowflake.snowpark.context import get_active_session
session = get_active_session()Dataikuから書き込んだテーブルをビューの形で参照しているスキーマに置く必要があるのです。
Snowflakeに詳しいTruestarのm.yashiroさんに方法を教えてもらいました!↓
〇ビューについて
権限周りとビューの作成についていろいろ複雑なのですが、ビューは2回作成しなければならないようです。
①既存のSnowflakeテーブルをapplication packageの任意のスキーマにビューを作成
accountadminで行います
1.application packageに任意のスキーマを作成
2.使いたいビューをこのスキーマの中に作成②snowflake側での権限設定→これもaccountadminで行います
1.①_1で作成したスキーマのusage権限をapplication packageに付与
2.①_2で作成したビューの参照元テーブルが存在するdatabaseのreference_usage権限をapplication packageに付与
3.①_2で作成したビューのselect権限をapplication packageに付与③setup.sqlの中でのビュー作成と権限設定
1.application roleとapp_instance_schemaを作成して、app_instance_schemaのusage権限をapplication roleに付与
2.”①で作成したビューをもとにしたビュー”をapp_instance_schemaの中に作成
3.②_2で作成したビューへのselect権限をapp_instance_roleに付与
こちらは弊グループの駆け込み寺で教えてもらいました。m.yashiroさん、いつもありがとうございます!
streamlit_app.pyに試しに記述してみた内容は以下です↓
# Import python packages
import streamlit as st
from snowflake.snowpark.context import get_active_session
# Write directly to the app
st.title("Example Streamlit App :balloon:")
# SnowflakeでSQLを実行
database: str = 'YOUR_DATABASE'
schema: str = 'YOUR_SCHEMA'
view_1: str = 'YOUR_VIEW_1'
view_2: str = 'YOUR_VIEW_2'
query_1 = f'select * from {database}.{schema}.{view_1} '
query_2 = f'select * from {database}.{schema}.{view_2} '
# ローカル環境では.streamlit/secrets.tomlからSnowflake接続情報取得、
# Snowflake環境ではアクティブセッション(Snowflakeにログインしているユーザー)を使用
session = get_active_session()
session
df_1 = session.sql(query_1).to_pandas()
df_2 = session.sql(query_2).to_pandas()
# 取得データをテーブル表示
st.write(df_1)
# 標準バーチャート表示
df_1 = df_1.astype({'value': float})
st.bar_chart(df_1, x='channels', y='value')
# plotlyバージョン
import plotly.express as px
bar = px.histogram(
data_frame=df_1,
x='channels',
y='value',
color='channels',
title='Bar plot (by use Histogram)')
st.plotly_chart(bar)
# 円グラフを追加
import plotly.graph_objects as go
from plotly.subplots import make_subplots
st.write(df_2)
# 2つの円グラフを含むサブプロットを作成
fig = make_subplots(rows=1, cols=2,
subplot_titles=('original', 'adjusted'),
specs=[[{'type':'domain'}, {'type':'domain'}]])
# 各円グラフをサブプロットに追加
fig.add_trace(go.Pie(labels=df_2['index'], values=df_2['original'], name="original", sort=False), 1, 1)
fig.add_trace(go.Pie(labels=df_2['index'], values=df_2['adjusted'], name="adjusted", sort=False), 1, 2)
# タイトルの設定
fig.update_layout(title_text="title_here")
# グラフの表示
st.plotly_chart(fig)Matplotlibはダメでしたが、Plotlyはいけます!
これはNative App(後述)よりもだいぶダッシュボードが作りやすいです!!
その他検討した手段
SnowflakeのNative App
Streamlit in Snowflakeがつい最近公開されましたが、それまではNative Appのインターフェースを
Streamlitにする、という方法でした。
Snowflakeのanacondaライブラリに入っているものでも使えない、などの制約があります。
(詳しくはドキュメントを参照。)
MatplotlibやPlotlyを封じられて棒グラフか折れ線グラフしか出せない…
Streamlit in Snowflakeがオープンになる前に試していたので方法の一つのように思えましたが、
Streamlit in Snowflakeが出てきた今、Streamlitを使うのであればあまりこちらを採用する理由は無さそうです。
Snowflake外からStreamlit
StreamlitのコミュニティクラウドにデプロイしたアプリからSnowflakeのデータにアクセスする方法です。
こちらも実現はできたのですが、権限の管理やデータをSnowflakeの外に出すことになってしまう、
という点でデメリットがありました。
しかし、こちらはSnowflakeによる制約が無いので、Streamlitでできることはすべてできます。
Matplotlibは現状Snowflakeでホスティングすると使えないみたい(2023年9月現在)なので、
どうしてもMatplotlibじゃないといけない場合はこの方法が有力になりそうです。
Dataikuの機械学習プラットフォームとしての良さはSnowflakeのデータ基盤能力、
Streamlitのウェブアプリという形式を組み合わせるとさらに使いやすくなりそうです!
truestar、DeepblueではSnowflakeの検討、導入支援や環境構築からアプリ開発まで幅広くサポート可能です。
Snowflakeに゙興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらからご相談ください!




