Hello! ぼーです!
最近Snowflakeのユーザーさんも社内外共に増え、コストについてよく考えるようになってきました。
ウェアハウスをあげれば確かに早くなるのは知ってる!でもなるべく小さいウェアハウスでキチキチまでクエリを効率化してコストを抑えたい…!
そんな感じでSnowflakeのパフォーマンスをクエリチューニング方面で改善しようと頑張る方にとって便利な「クエリプロファイル」についてご紹介しようと思います!
Snowflakeのクエリプロファイルとは
Snowflakeのアクティビティ>クエリ履歴から実行したクエリを選択して見ることができる物で、クエリ全体のうちどこがボトルネックだったのか・どういう原因かなどクエリ実行におけるパフォーマンスを探ることができる機能です。
見た目はこんな感じ↓
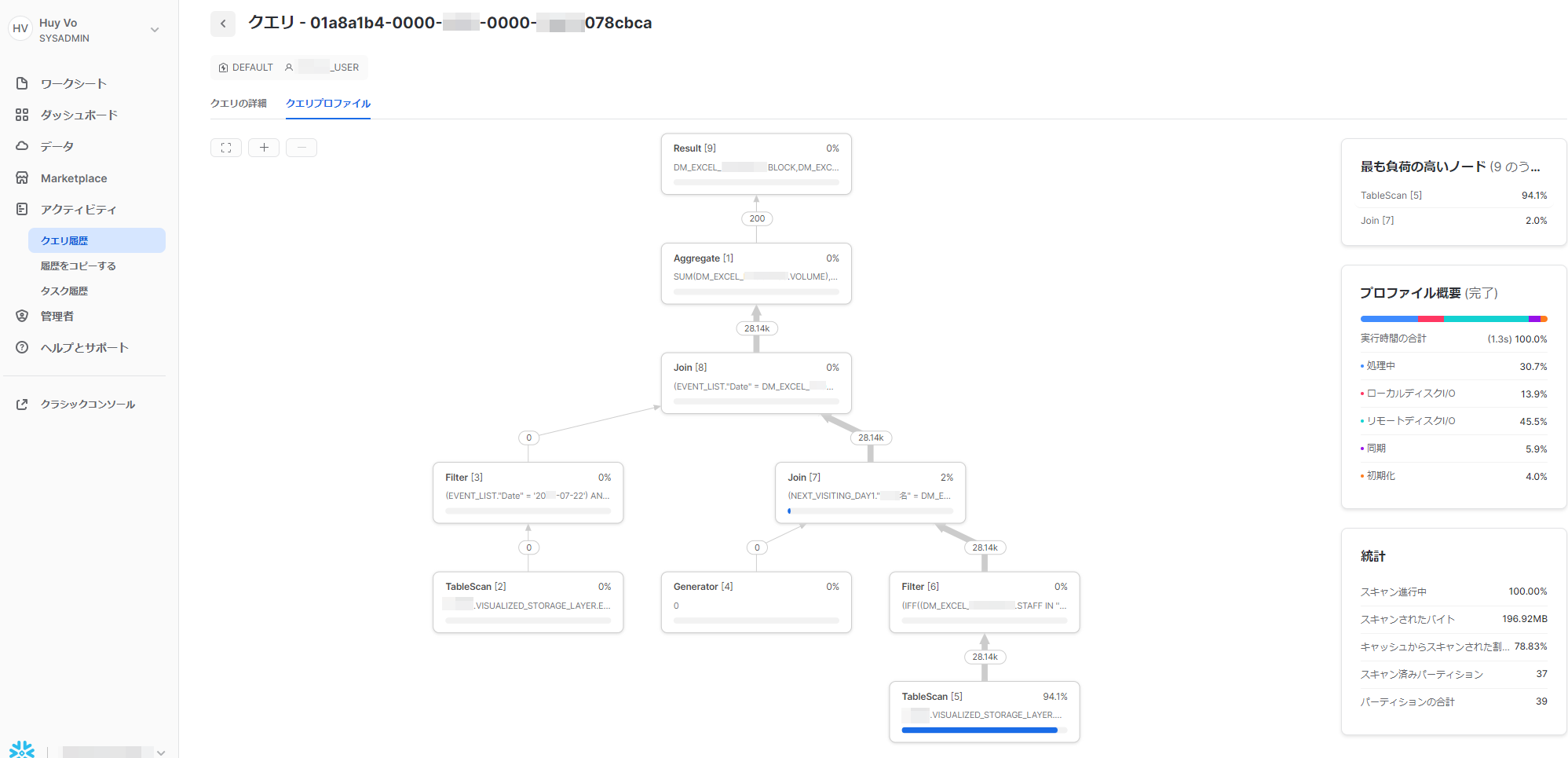
まるでゲームのスキルツリーみたい・・・
このようにグラフィカルに全体を俯瞰しつつボトルネックを見つけてどう改善していくか知ることができます。
直感的に悪いところが分かるようにはなっていますが、それぞれの項目の見方を知ることでより効率的に把握できると思うのでぜひ一緒に学んでいきましょう!
インターフェース構成
先ほどの画面を例にすると大きく分けて以下の要素で構成されています。
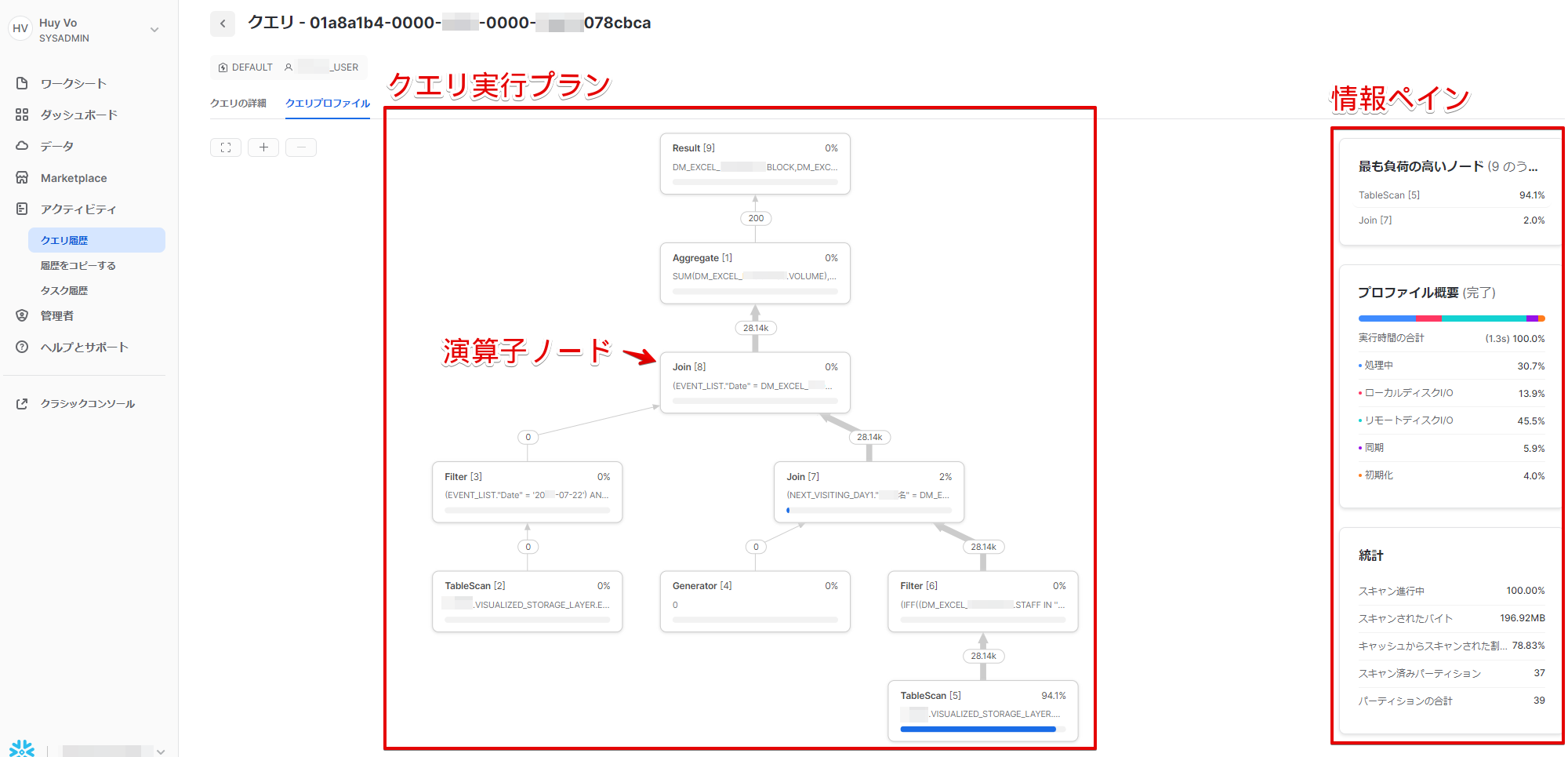
クエリ実行プラン
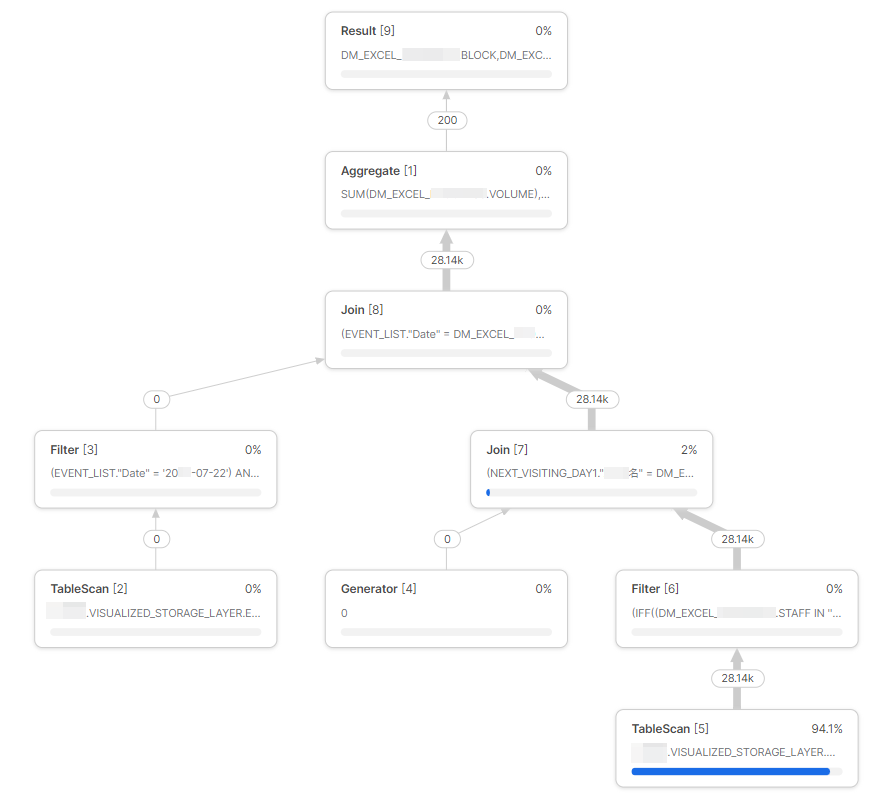
各ノード間の関係やクエリ処理などをグラフィカルにツリー形式で表現したもの。下から上へ流れていき、矢印には処理ごとに何行次のノードに流れたか数字と矢印の太さで分かるようになっています。
結合によるレコード爆発(レコード激増のこと)などここですぐ発見できそうですね。
演算子ノード
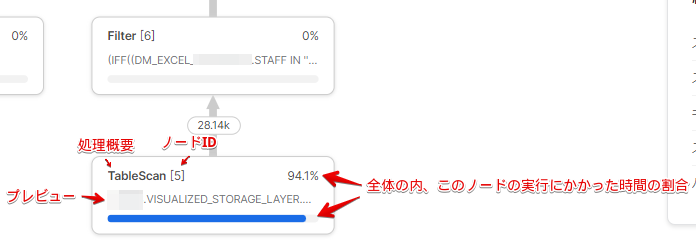
クエリ実行プラン内にある四角いブロックの事を演算子ノードと呼びます。上から順に見方を
・処理概要(演算子)[ノードID]
・クエリプレビュー
・このノードの実行時間。クエリ全体の内このノードに何%時間が使われたかを青いバー&右上の数字で表現しています。
ちなみに単純に縦に積み上げてくれるUNION ALLで事足りるのに重複を除外も兼ねているUnionを無意味に使ったりすると、ノードがUnionallノードとAggregateノードに分割されパフォーマンスが悪くなります。
処理概要がUnionall→Aggregateと続いていて尚且つその二つのノードから出てる行数が同じ場合は注意してみましょう。
情報ペイン
ここはクエリ実行プランのどこをクリックしたかで出る物が変ったりします。
基本的には以下の4つが表示されます。
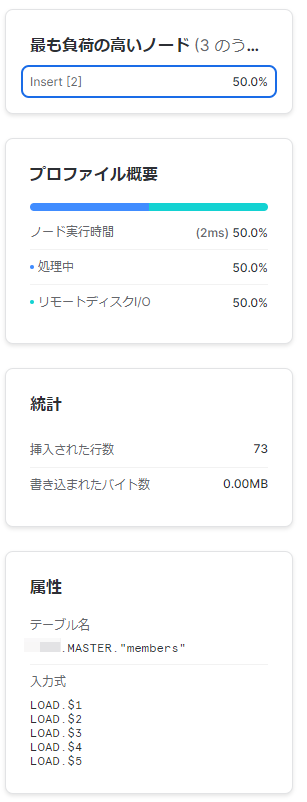
・最も負荷の高いノード
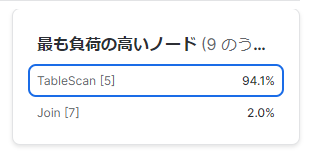
そのまんまです。クエリ全体の内、処理に時間がかかった割合1%以上のノードが高い順でリストされています。クリックすることでそのノードのその他情報を表示することもできます。
・プロファイル概要
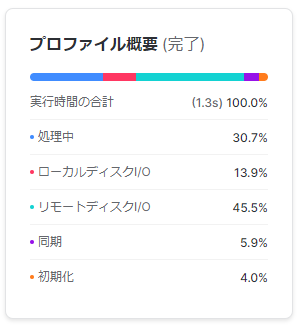
全体でかかった処理の時間の内訳を表しています。ノードをクリックすることで特定のノードでの時間の内訳も表示できます。
- 処理中:ウェアハウスのCPUを使って処理した時間
- ローカルディスクI/O:ウェアハウスにあるストレージ(SSD)にアクセス(読み書き)した時に掛かった時間
- リモートディスクI/O:ウェアハウスではなくクラウドストレージにアクセスした時に掛かった時間
- 同期:プロセス間の色んな同期アクティビティにかかっている時間
- 初期化:クエリ処理に関する設定に掛かった時間
- ネットワークコミュニケーション:データ転送待ち時間
・統計
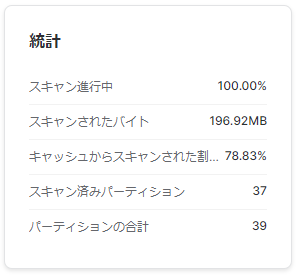
ノード次第で様々な統計情報が表示されます。
種類が多いので公式ドキュメントから引用させていただきます。

多い・・・ですね・・・
どれがどういいかは目的によってそれぞれかと思いますが、2つ例をあげるとするとPruningとSpilingが分かりやすいかなと思います。
Pruningの「スキャンされたパーティション」がパーティション合計数に対して少なければ少ないほど”効率が良い”と言えます。何故そうなるかについてはまた別の機会にということで割愛させていただきます。
Spilingについてはここが多いとパフォーマンスが結構落ちてしまうことがあるため注意してみたほうがいい指標となります。
Spillingとは処理で扱う中間データがウェアハウスのメモリに乗り切らず、他のストレージに”こぼして”しまう状態のことを指します。メモリから溢れたデータを他のストレージを間借りして何とかするイメージでしょうか。
- 「ローカルストレージに流出したバイト数」=メモリからウェアハウスのSSDにこぼれたバイト数。ここが多いと黄色信号。
- 「リモートストレージに流出したバイト数」=上記でも足りなくて更にウェアハウスではなくクラウドストレージにこぼれたバイト数。ここまでくると物凄く遅くなるので赤信号。
特にこの上2つの信号を覚えておくだけでもパフォーマンス改善につながると思います。
・属性
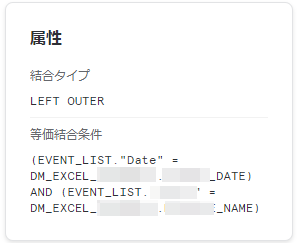
各ノードの処理の詳細情報が表示されます。
Joinだったら結合キーだったり、集計だったらグループ化キーや集計関数だったり・・・
「この処理って実際なんだっけ?」と思ったらとりあえず属性を見れば思い出せるかと思います。
まとめ
以上がクエリプロファイルの見方となります。
色々見方がありますが、まとめると下記の点について気を付ければひとまず窮地は乗り切れると思います。
- クエリ実行プランを見てレコード爆発が無いか注意する
- 無意味なUnionをしてないかUnionall→Aggregateを演算子ノードを見て気を付ける
- スキャンされたパーティションが少なければ少ないほど大概はいい
- Spillingについてローカルは黄色、リモートは赤信号レベルで注意
これで皆も果てないクエリ改善の沼にはまってくれればいいなっ!¯_(ツ)_/¯