こんにちは、truestarたまるです。
弊社では #Exploratory についての記事を 毎週更新しております。
今回は、データ分析コンぺサイトであるKaggleのコンペに挑戦してみます。
その中で、Exploratoryだとこうできます、というのを実践レベルでみて頂ければと思います。
※執筆時点で最新のVersion6.3.3時点の機能を前提とします
今回は『Kaggleコンペティション チャレンジブック』という本
https://book.mynavi.jp/ec/products/detail/id=119629

の4章で扱っている「ポルトセグロ 安全ドライバー予測コンペティション」という過去コンペでの上位ランカーの手法をベースに再現してみましょう。
こちらの本はPythonベース、ExploratoryはRベースという違いもあるので、そのままExploratoryで真似しきれない部分もあるのですが、できるだけ代替してみようと思います。
ちなみにデータはKaggleにログイン後、当該コンペに参加することでDLできます。
https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
コンペ内容
主催者:
Porto Segro(ポルトセグロ)…ブラジル最大手の自動車・住宅保険会社
問題の類型:
二重クラス分類…「安全なドライバー」と「そうでないドライバー」を、登録データからどう分類できるかという問題
安全なドライバー=事故の可能性が低いドライバーには少ない金額を、事故の可能性が高いドライバーにはそれなりの金額を、月々の請求額とするような合理的な運営を目指したいという動機があるようです。
データの形式:
テーブル形式(ただし、目的変数以外は変数名が匿名化されている)
評価の基準:
正規化ジニ係数…こちらはExploratoryですぐ確認・実装するのは難しそうでした…ただ一般的な評価指標は確認できますので、今回はそれを見ていきます
データ内容
ダウンロードできるデータはTrainとTestの2種類のCSVファイルのみで、どちらもすぐに分析にかけられる形式にまで整っていて、前処理の必要はありません。( ありがたい、、)
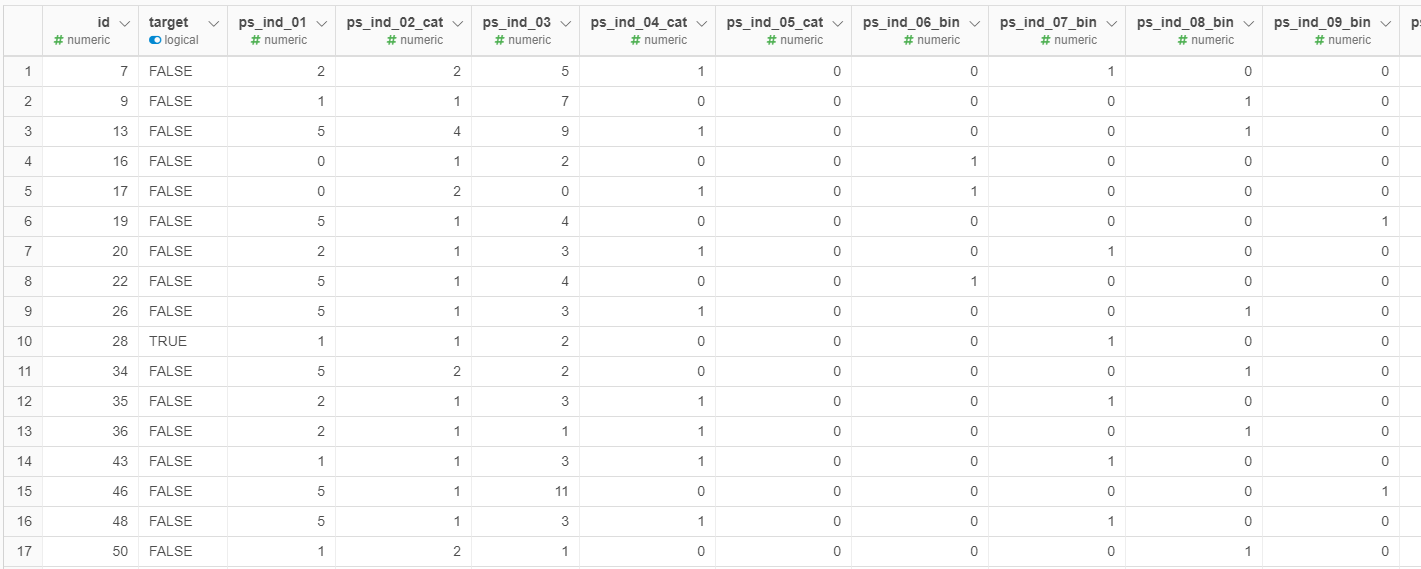
ということでさっそく、TrainデータをExploratoryにインポートしてみましょう!
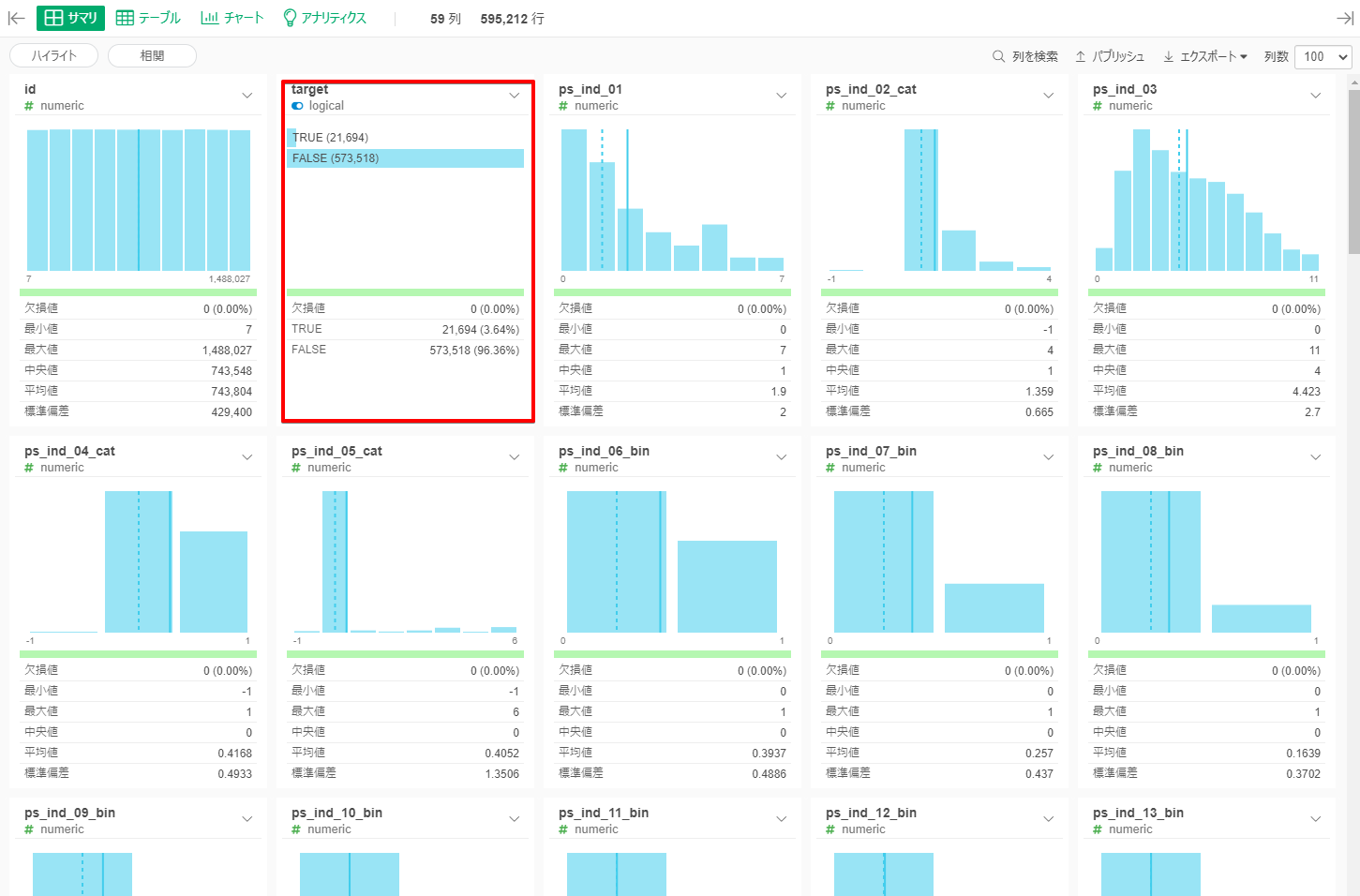
他の記事でも何度も言っているのですが、データをインポートしてすぐこのサマリがみられるのは、本当にありがたいですよね。
前述の通り、予測に使えそうな変数はすべて匿名化されているので、なにを示しているカラムなのかはわからないんですよね。
ただ
・Targetの”TRUE"の割合が5%しかない不均衡なデータである
・値はすべて数値化されていて、各変数間の関係なども不明(もともとCategoryを表していたカラムか、二値のカラムか、は変数名や値の入り方である程度予測が立つ)
・どのカラムも一見欠損地(NULLやNA)はなく、なんらかの値が入っているが、中には-1といった例外的な値もあり特別な意味がありそう
というようなことが読み取れれば、現段階ではOKかなと思います。
Exploratoryでの戦略 – XGBoostとLightGBM,ランダムフォレストとの比較
Exploratoryでの二値分類のアプローチとしては様々考えられますが、今回はXGBoostを使おうと思います。
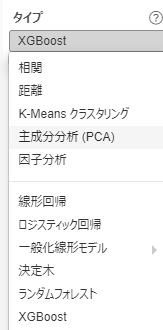
参考書籍の方では LightGBMというモデルを採用しているのですが、Exploratoryにそのものはないので、それに一番近い手法になります。
ちなみに LightGBM はその名の通り、Xgboostに比べて計算量が軽く、学習速度が速いのが一番の違いのようです。(LightGBMの方が後発)
どちらも 勾配ブースティング木(GBDT:Gradiant Boosting Disicsion Tree) という考えをもとにしていて、
ランダムフォレストが決定木を並列に作成するのと違い、勾配ブースティングでは直列に決定木が作成されます。
ちょうど、
並列 ≒ 専門家が横並びで、各々の結論を出し、それぞれに対して評価をするようなイメージ

直列 ≒ 一列に並んだ専門家が、それぞれの結論を考慮して目標への差を修正しつつ、伝言ゲームをしていくようなイメージ

のような理解でおります。(ざっくり)
『Kaggleで勝つデータ分析の技術』
https://gihyo.jp/book/2019/978-4-297-10843-4
によると勾配ブースティングのほうが
・精度が高い
・パラメータチューニングをしなくても精度が出やすい
・不要な特徴量を追加しても精度が落ちにくい
(P234)
また
LightGBMはXgboostと比べると速度は速く、精度は同程度と考えられているようです
(P238)
とあります。よって、今回とれる手段としては XGBoost が適していると考えました。
ちなみにLightGBMをベースにXGBoostとの違いや考え方は以下のサイトがわかりやすかったです。
(同じ直列の決定木でも、新しい分岐の作られ方に違いがある、など解説されています)
https://www.codexa.net/lightgbm-beginner/
今回はここまで
インプットがメインでしたが、結構な分量になってしまったので、
実際にコンペに取り組んでみるのはまた別の記事にしようかと思います!
ここまで読んで頂き、ありがとうございました。