
追記:
こんにちは、truestarの田中です。前篇後編で書かせて頂きました「はじめてのA/Bテスト」を株式会社GRIさんのデータサイエンスすいすい会にてご報告させて頂きました。
主に前篇についてお話させて頂いております。後編の主題となる「ベイジアンA/Bテスト」についてはGRIの古幡様、望月様よりわかりやすい解説がされています。
是非ご視聴ください!https://www.youtube.com/watch?v=1Wxo-L6ZffU
こんにちはtruestarの田中です。
今回は今年3月に訳書が出版されたRon Kohavi 著「A/Bテスト実践ガイド 真のデータドリブンへ至る信用できる実験とは」www.amazon.co.jp/dp/4048930796
が大変勉強になりましたので、本書の内容をうすーーく踏まえつつ(本書329Pありまして内容は超盛沢山なんです)
A/Bテストの一部である「分析・評価」の箇所をExploratoryを使用してやってみようと思います。
ちなみに、今回は前篇とし、実践ガイドを参考にA/Bテストを始める場合のイロハについてまとめたいと思います。後編で実際にExploratoryを使用していきます。
ちなみに、本書内ではBingの広告ヘッドラインの文字数をA/Bテストの結果をもとに変更したことで、当時米国内だけで年間換算1億ドル以上の収益増加になったという最もうまくいった事例が載っています。これは変更によるリスクも少なく大変な好例ですが、
施策実施前の意思決定の素材としても、施策後の効果検証役としても古典的な手法ですがA/Bテストは重要だと感じます。
※A/Bテストは考慮する事項がものすごく多く、本ブログではさわり程度しかお伝え出来ません。A/Bテストにご興味のある方は是非実践ガイドをご一読ください
A/Bテストとは
多くの方がご存じかと思いますが、AとBの2つのグループを作成し、各グループのパフォーマンスを測定して、どちらがよりパフォーマンスが優れているかをテストすることです。
例えば、ECサイトでクーポン施策を実施するかどうか検討するとして、購入確認画面にクーポンコードの入力欄を追加した場合の影響を評価したいとします。そのような場合、ECサイトの購入画面に2つのパターンを用意し、グループAにはクーポンコードが表示されるページを、グループBにはクーポンコードが表示されないページを見せて、どちらのパターンがより収益が上がるか測定します。
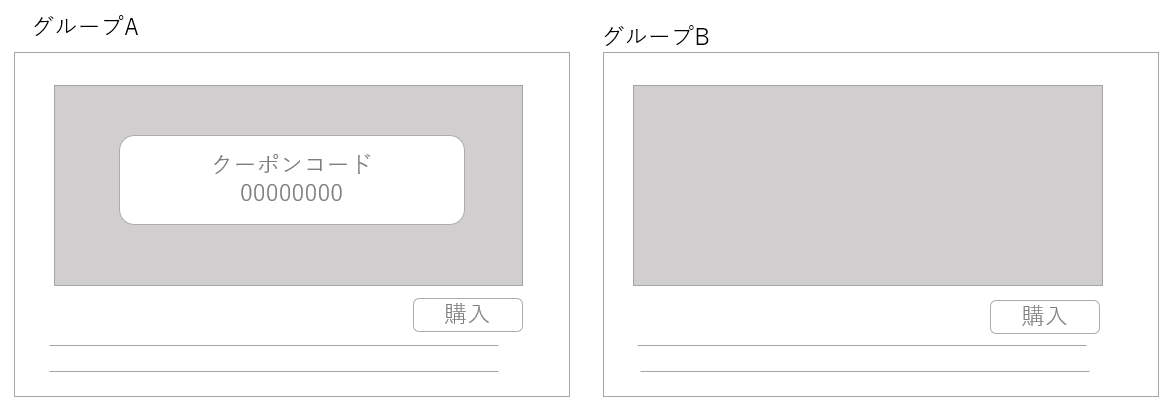
実験後、2つのグループ間で差が生じた場合、その差は偶々ではなかったのか?なにかバイアスがあったのではないか?デザイン変更だけが差の原因なのか?など、いろいろな懸念点を潰し、晴れて実証結果となります。
用語的なものですが、クーポンなしページが「既存ページ」だった場合、Aグループは介入群(変化あり)、クーポンなしのBグループはコントロール群(変化なし)と呼んだりします。グループ分けはランダムに実施し偏った特徴がないようにし、特に理由がなければ1:1にします
A/Bテストの流れ
上記の仮ECサイトを例に考えてみます
1.最大目標指標(評価指標)の決定と何を明らかにしたいのか(調査仮説)を決める
Ⅰ.まず、このA/Bテストで、最も明らかにしたい目標指標をきめます。OEC(Overall Evaluation Criterion:総合評価基準)といったりします。例えばユーザー一人当たりのアクティブ日数をOECとした場合、実験期間中にユーザーがアクティブだった日数がOECになります。OECは短期的(実験期間中)に測定可能で、かつ長期的な戦略目標を推進する原因となるものである必要があります
Ⅱ.OECに紐づくゴール指標(キーメトリクス)を決めます。これが一つしかないときはキーメトリクス=OECになります。今回の仮ECサイトの場合ユーザー一人当たりの収益をキーメトリクスとOECとしましょう。(OECはその名の通り複合的でありえるので、利用率と広告収入の組み合わせなどもありえます。)
Ⅲ.分母を考える
■サイトを訪問したすべてのユーザー:変更が行われた購入確認ページに訪問しなかったユーザーが含まれるのでちょっとノイズが大きいです
■購入プロセスを完了したユーザーのみ:購入を完了したユーザーへの影響ではなく、購入額に影響したかどうかを見たいので適切ではないです
■購入プロセスを開始したユーザーのみ:これが一番適切そうです
したがって、仮説は購入確認ページにクーポンコード入力欄を追加すると、購入プロセスを開始するユーザー一人当たりの購入完了率が低下するのではないか?(仮説の最後は上昇するのではないか?でもどちらでもいいのですが、本書ではクーポン施策を行ったことで購入完了率が減少し収益が下がった事例が載っていたので、このように設定しました)
2.グループ分けをするランダム化単位を決定す
ユーザーごとにランダム化するというのがよく用いられる方法です。すべてのユーザーを対象にテストするケースと、特定の特性をもつユーザーのみを対象にテストするケースがあります。特性の例としては、地理的特徴(日本国内のみ)、OS(IOSのみ)、デバイス(iphoneのみ)、性別(男性のみ)など様々です。
3.サンプルサイズを決定する
サンプルサイズは結果の精度を重視する場合、より多くのユーザーが必要になりますが、ユーザーがどのような反応をするかわからない場合はリスクが高いのでサンプルサイズは少なく始めた方がよい可能性があります。
※サンプルサイズの求め方などは無料の計算サイトが検定ごとにありますので使いやすものを見つけてください!(例えば、カイ二乗検定「Evan’s Awesome A/B Tools」 Evan’s Awesome A/B Tools はこちらのサイトをご覧いただくと設定方法などわかりやすいかと思います。)
サンプルサイズの決定は、A/Bテストの結果の信頼性をどれほど高めるか、AB間の差をどれくらいまで検出したいか、さらにその最小差の検出力をどれくらいにするか、などビジネス判断とかかわってくることであり実は統計的に一意に決められるものではありません。(例えば0.1%の収入差は見逃せても、1%収入の落ち込みは見逃せないといったように必要なサンプルサイズは大きくビジネス判断に依拠します。)
とはいえ、一般的な基準もありまして、信頼性は95%、差の検出力は80%程度あればといのが一般的です。ただ、最小検出可能効果(MDE)はビジネス判断(=つまり決め)によるところが大きいので上記で紹介しているサイトなどをご参照ください!
4.実験期間を決める
実験期間の設定は「何を見たいか」に大きく依存します。
例えば、デザインを一部変更した場合のA/Bテストは比較的短時間でも問題ありませんが、SNSの追加機能や販促促進機能の導入効果のA/Bテストなどはある程度長期間で結果を確認する必要があります。
また、どのケースにおいても「交絡効果」の影響を考慮しなければならず、考慮の仕方が短期テスト/長期テストで異なってきます。
交絡効果とは、例えば「UIの変更」が「売上」に影響があったように見えたが、実はクリスマスシーズンで放っておいても売上が上がっていたといった例で、観測されていない因子が観測された事象の原因である場合の影響のことです。交絡効果がある場合はデータ上では観測された事象同士がさも因果関係にあるように見えます。
簡単に留意点をまとめます。
■短期テスト
・曜日効果:平日と週末でユーザー行動の分布が異なります。テスト期間は最低1週間あると安心です。
・季節性:祝日など、ユーザー行動の分布が異なります
・プライマシー効果とノベルティ効果(実験初期の効果が大きくなったり小さくなったりする傾向のことです。UI変更後物珍しさにクリック数が伸びても時間の経過とともにクリック数は減少する場合がありえます。)
■長期テストと短期テストで効果が異なる場合(2週間のテストでは効果があったのに、2ヶ月テストしたら効果がなくなったぞ、、、というケース)
・ユーザーの学習効果:ユーザーが変化に対応するとユーザー行動が変化します。例えば実装からある程度時間がたってから有用性に気づく場合や、初期に熱心に探索を行うなど、このような場合ユーザーが最終的な均衡点に到達するまで、長期効果は短期効果とは異なる場合があります。
・ネットワーク効果:SNSなどは想像しやすいと思いますが、ネットワークの広がりによって新機能や新アルゴリズムの評価は変わるためどの時点で評価するか検討が必要です。
・体験と測定の遅延:ユーザー全体が介入効果(新機能の搭載など)を体験するまでには時間差がある場合があります。
・エコシステムの変化:エコシステム内の多くのことが時間の経過とともに変化し、ユーザーへの反応に影響します。(エコシステムの例としては他の新機能のローンチ、季節性、競合の状況、政府の方針、ソフトウェアの劣化)
ではこのような、交絡効果が入ってしまいそうな場合はどうすればいいのか、、、。
いくつか検証方法はあると思います。まずコストを無視すれば、何度かA/Bテストを繰り返すことです。例えば新機能が解約率にもたらす効果を検証しよと考え、新機能実装した介入群と実装しないコントロール群でA/Bテストを実施したとします。結果、新機能を実装した方がよいという結果になったとしても新しい機能を使うユーザーはヘビーユーザーなだけではないか?という疑問も生じます。この場合再度新規ユーザー群とヘビーユーザー群に分けてA/Bテストをするとうことも考えられます。
ただ、これはかなりコストが高いので、結果に交絡効果の可能性が考えられる場合は基礎集計などで一点だけ異なるセグメントがないか、など地道に明らかにしていく方法もあります。また、差分の差分法(Difference in Difference)を利用して介入効果を推定する方法などもあります。これはまたどこかでご紹介いたします。
5.実験の実施とデータの収集:こちらは組織内部(どこまでコストをかけられるのか)、インフラまわりのお話になりますので一旦割愛いたします。
一点、集まったデータを確認する中で、サンプル比率が意図通りになっていない、、、などの事例が生じるかもしれません。
例えば、最も多いデザインは1:1の比率かと思いますが、実験デザインでは比率1.0と設定していたにもかかわらず、実際の比率が0.99よりも小さいあるいは1.01より大きいような場合は何か起きている場合があります。また比率の検定をしてp値が0.001以下(あまりに良すぎる結果。通常p=<0.05で十分)の場合も何かバグが生じていないか確認すべきです。
この点に関してだけ、どのようなことが起こっている可能性があるかいくつか代表例列挙します。
・ブラウザのリダイレクト
・介入群(UI変更などを行った群)とコントロール群でのパフォーマンスの違い:介入群に遅延が生じ指標に影響を与えている
・ボット
・特定のブラウザやブラウザバージョンでのバグ
・計測の欠損
・残留効果または繰り越し効果:いわゆるバグの混入
・時間効果:メール送付などで、適切にグループはランダム化されていたが、メールの送付順番が介入群、コントロール群など固定されており受け取る時間帯にそもそも時間差があった
何か異常が生じていそうな場合は、上流時点(ランダム化など)~インフラまわりまで再度チェックが必要ですがセグメントごとにサンプル比率を確認するというのも実直な一つの方法です。例えば日ごとに確認して異常な出来事がなかったか、特定のブラウザの挙動がおかしくなかったか、新規ユーザーと再訪者の比率などこのあたりはやはり基礎集計で異常値チェックをしていくことになります。
一旦まとめ、今回の実験デザインは以下のようになります。
1.ランダム化単位はユーザー
2.全てのユーザーを対象にして、購入確認ページに訪れたユーザーを分析する
3.1ユーザーあたりの収益の1%以上の変化に80%の検出力を持たせるとして、サンプルサイズを決定
4.サンプルサイズが集まるまでの最小4日実験する(これは仮定でサンプルサイズが集まる日数はサイトの流入量などに大きく左右されます。)必要があるが、曜日効果を考慮するため一週間実施しプライマリー効果などを検出した場合は実験期間を長くする。
6.データ分析と結果の解釈:やっと分析まわりがでてきましたが、こちら後編で。この分析で対立仮説が棄却された場合(差はなくない)、仮説は正しいことになります。
7.意思決定
当たり前ですが、A/Bテスト実施の目的は、意思決定を促すためのデータ収集かと思います。そのため以下のようなことも併せて検討する必要がありそうです。
・改修によってトレードオフになる指標がないか(局所的改善をしても大局的にマイナスになるケース)
・改修コストが回収できるのか
・ローンチ後の保守運用コストは改修に見合うのか
このような判断をしなければいけない時に、やはり使用してほしい判断材料の一つが分析結果です。後編になってしまいますが、介入(UIの変更など)が介入群とコントロール群で指標に対して(例えば一人当たりの収益など)どのような差があったのか??(その結果がどれくらい確からしいのか)その検証をExploratoryでやってみたいと思います。次回もよろしくお願いします。
truestarでは様々なデータ分析業務を承っています。こちらからぜひご相談ください。







