こんにちは。truestarの田中です。
前編(https://blog.truestar.work/exploratory/20200316/38810/)
を書いてからかなり時間が経ってしまいました。
前篇ではExploratoryに実装されたProphetパッケージを使用して時系列予測モデルを作成してみました。
後編では作成したモデルの精度向上を目指してみたいと思います。
※前回のおさらい
データ:家具の日別売上データ(3年半分)
目的変数:売上(月単位)
外部変数:なし
設定:Prophetのデフォルト設定(周期性・トレンド)を使用
感想:超簡単にそれっぽい予測ができた!けど、これはそのまま使って大丈夫なのか?
モデルの評価
さて、「精度を上げる!」と先走ってしまいましたが、まず作成したモデルの「評価」(どれくらい予測精度があるのか?)を
しなければ精度を調整する(=モデルのチューニング)ステップには入れません。
Exploratoryではモデル評価も簡単に確認することができます。
モデルの評価ステップ①:交差検証(Backtesting)
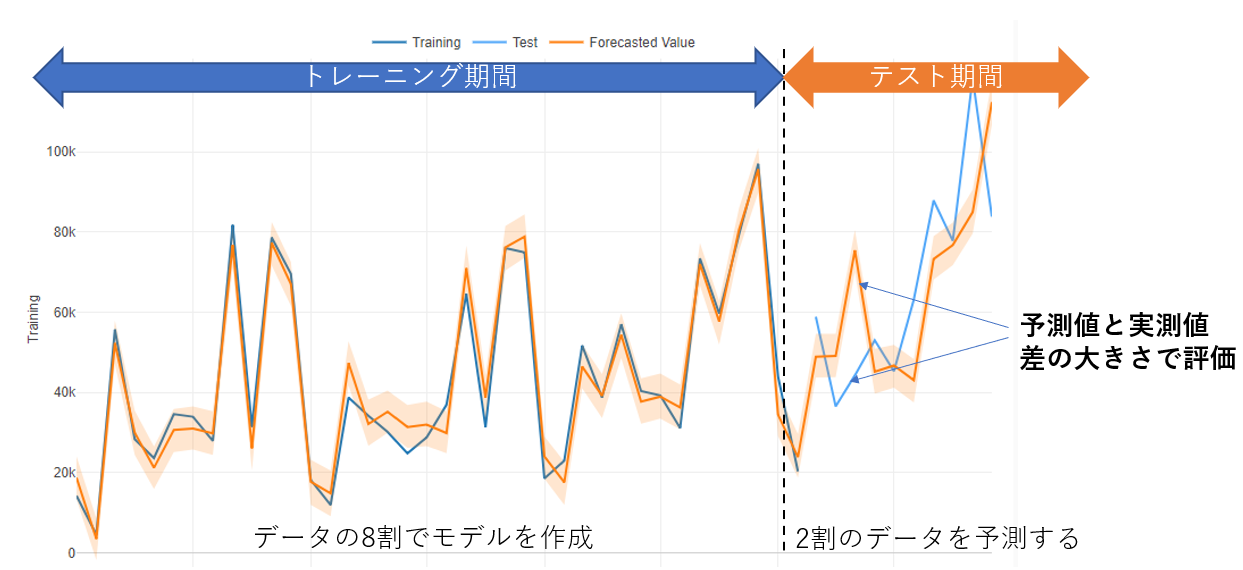
交差検証とは、具体的にはデータの7~8割を選びトレーニングデータとし、残り2~3割をテストデータとし
前者でモデリングを行った上で後者を予測し、予測誤差に基づいてモデルの調整を繰り返すことです。
これによって、トレーニングデータにだけ当てはまりが良く予測に適さないモデルを排し、真に予測に資するモデルを選ぶことができます。
※Exploratoryでは留意する必要はありませんが、時系列データの場合トレーニングデータ・テストデータを抽出する際、ランダムサンプリングは避けましょう。
さっそく、トレーニングデータ期間とテスト期間を分けて検証をしてみましょう。
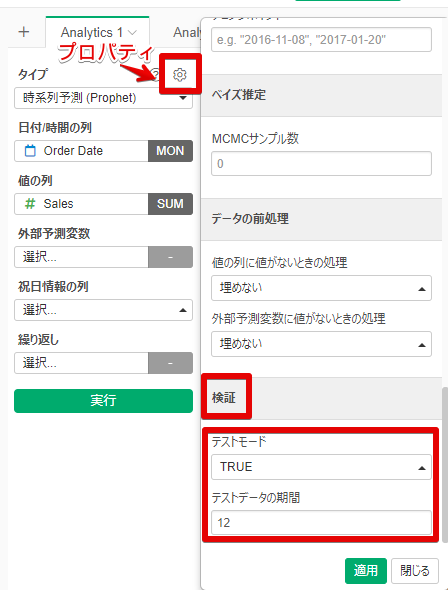
【操作手順】
プロパティ(歯車マーク)>検証>テストモード=TRUE>テストデータ期間=12(12カ月)>適用
※AnalyticsでProphet分析を実施した上で以下の操作を実施してください。
※テストデータ期間の粒度は「値の列」で設定した予測期間の粒度と合致します。
適応を実施すると以下の結果がアウトプットされました。
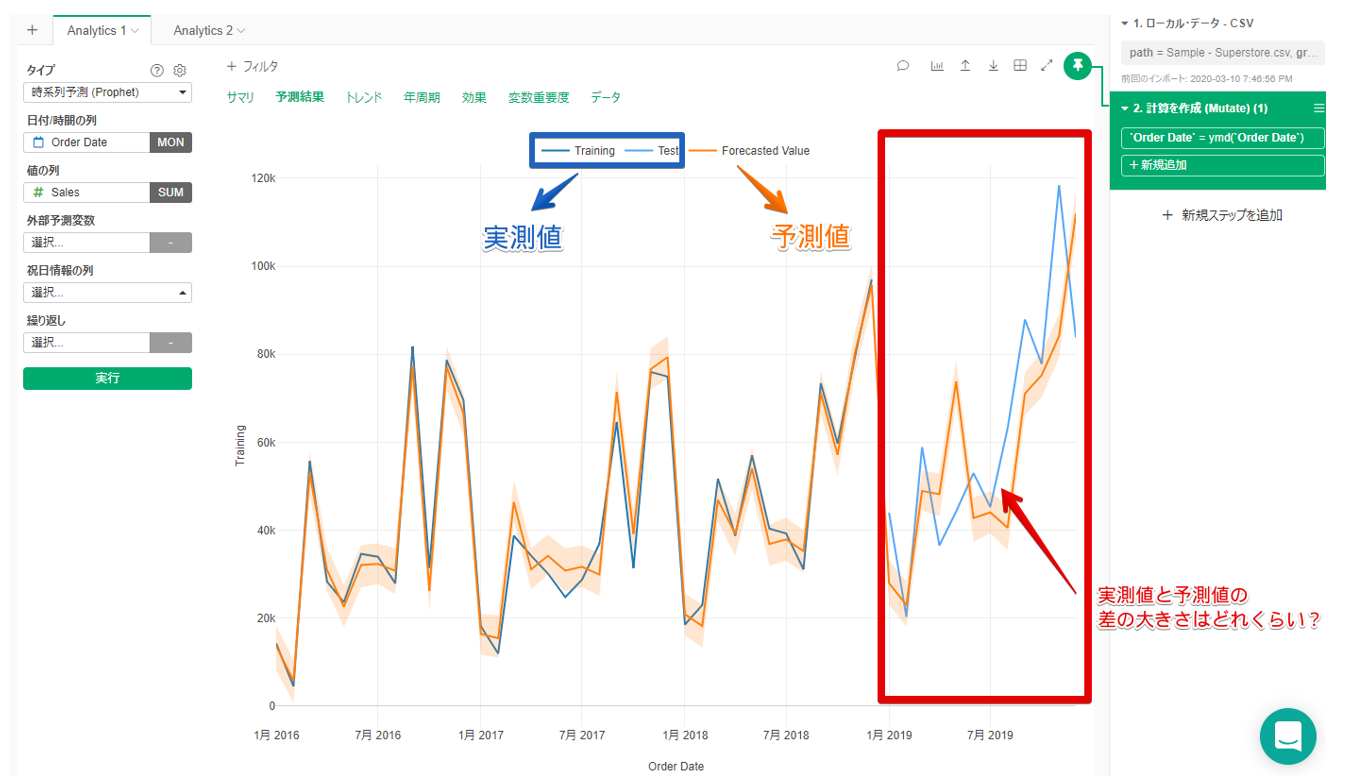
水色・青色のラインはトレーニング期間・テスト期間の差はあれ実測値になります。オレンジのラインが予測値になります。
全体的な傾向は良さそうですが、月単位で見ると予測をかなり外している月もあります。
では、このモデルの評価はどうでしょうか。赤枠内の予測値と実測値の差の大きさ確認するためにサマリタブを開きます。
モデルの評価ステップ②時系列予測の評価指標
サマリタブに以下の評価指標が並んでいます。

各指標を簡単に説明します(詳細が気になる方は是非調べてみてください!)
①RMSE:(Root Mean Square Error)
予測からのずれの二乗の平均の平方根
例:誤差が10,2,-2,4だった場合
![]()
②MAE:(Mean Absolute Error )
予測からのずれの絶対値の平均
例:誤差が10,2,-2,4だった場合
![]()
予測値と実測値のずれの扱いに違いはありますが、両指標はいずれも“ずれの平均”を表現しています。
したがって、評価は予測したい値(例えば売上)の実測値スケールに左右されるため、スケールが異なるモデルどうしを比較することはできません。
例えば、月当たりの家具の売上が多い店(月数億円)と少ない店(月数百万)で、それぞれ売り上げ予測モデルを作成した場合、
売り上げが低い店のモデルの方が、誤差平均が小さくなります。この結果で「売上が低い店の予測モデルの方が良い」といった比較はできません。
そのような場合でもモデル精度を比較したい時は、MAPE、MASE指標を用います。
※RMSEとMAEではRMSEは平方根の中身で二乗しているので、MAEよりも外れ値をより大きな誤差として扱う傾向があります。
③MAPE:(Mean Absolute Percentage Error)
予測からのずれの割合の絶対値の平均(MAEを割合%で表したもの)

※MAPEはゼロのデータが存在する場合、ゼロで割ることになってしまうので使えません。
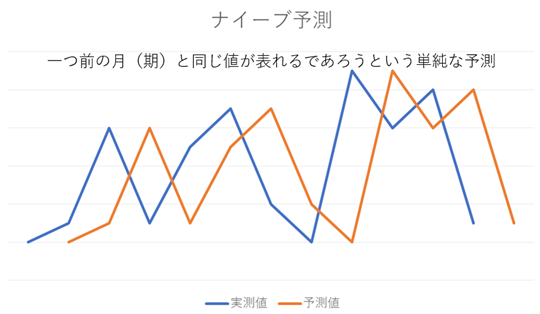
④MASE:(Mean Absolute Scaled Error)
テスト期間のMAEをトレーニング期間のナイーブ予測のMAEで割ったもの
※ナイーブ予測=一つ前の月(期)と同じ値が表れるであろうという単純な予測
RMSEとMAEの平均的なズレの単位は「平均1千万ほどズレがあります」といった実測値ベースで、
MAPEとMASEは「(平均)10%のズレがあります」といった割合ベースで表現できます。
MAPE・MASEは割合で評価するためモデルの比較も可能です(ただしMAPE・MASEの値を比較してみ意味がありません。)
データの特徴とモデル作成の目的から適切な評価指標で解釈していきましょう。
■まとめ表(他にもいろいろ特徴や使い勝手はあります)

ちなみに、評価指標は決定係数やP値のように〇〇以上以下ならOKという基準はなく、できるだけ指標の値が低くなるようにモデルをチューニングしていきます。
再度サマリタブの各指標の値を確認すると、MSE、MAEともに1.8~2.1万ドルの誤差、MAPEでみても30%程度の誤差があり、
MASEでもテスト期間のMAEと超単純な予測のMAEが88%程度合致してしまいます。なんとも言えない結果なので、モデルのチューニング(≒精度向上)をしてみます。
モデル精度を向上させる
やっと本題に入ってきました・・・。
- さて、モデル精度が微妙なのでモデルのチューニングをしてみます
今回モデル精度向上のために実施してみるチューニングは以下
- ①季節性のモードを変更してみる(加法的 vs 乗法的)
- ②外部予測変数を追加してみる
①季節性モードを入れてみる
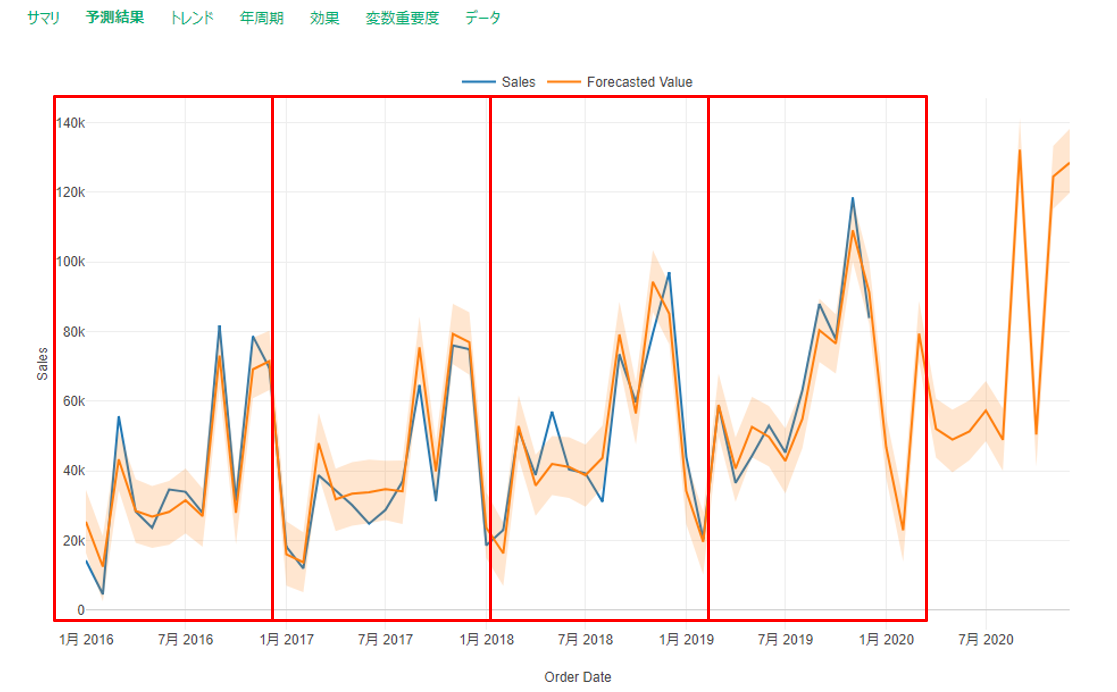
再度プロパティで設定した検証>テストモード=TRUEをFLUSEにしてテスト期間のない予測モデル結果を見てみると、
2016年1月以降1年ごとに予測値と実測値のズレが大きくなっていくように見えます。
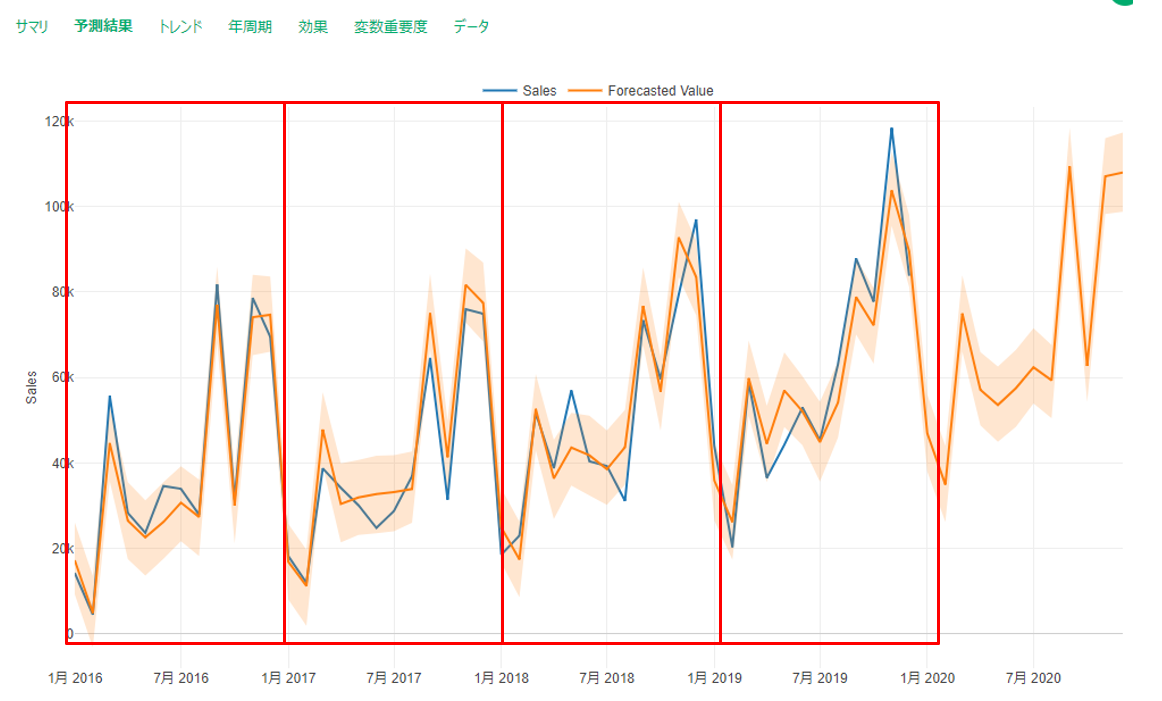
何が起きてるのでしょうか?
前提:売り上げが上がるにつれ、季節性による変動(12月に売れ、8月に売れない)も大きくなるはず
仮説:モデルは季節性による変動の大きさは一定であるという前提で予測している?
または、売り上げが加速的に増加しており実際の季節変動の大きさにモデルが予測する季節変動の大きさがついていけてない?
前提から上記のような仮説が成り立ちそうです。
つまり、目的変数である売り上げが下図のような乗法的イメージで増加している可能性が考えられます。
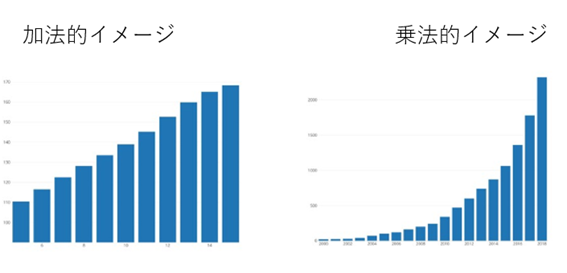
このようなことが考えられる場合、季節性モードを変更してみましょう
- 季節性モード:
- 加法的(デフォルト):目的変数の値に関わらず、季節性の変動の大きさは一定
- 乗法的:目的変数の値が大きくなればなるほど、季節性の変動も大きくなる
目的変数(売り上げ)が乗法的伸びをしている場合、あわせて季節性も乗法的に設定します。
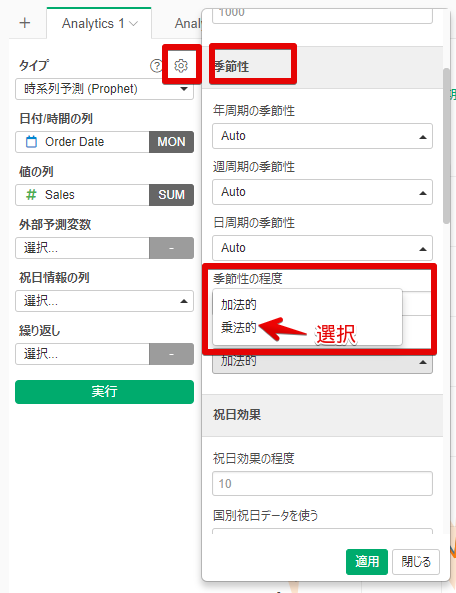
【操作手順】
プロパティ(歯車マーク)>季節性>季節性の程度=乗法的>適用
設定をチューニングした結果、以下のように予測が変わりました。
加法的な結果に比べて1年ごとの予測値と実測値のズレが一定になった(どんどん開いていかない)ことがわかります。
評価指標でも精度を確認します。再度テスト期間を12カ月設けて結果を比べてみました。
幸い各指標の値が低下しモデル精度が向上しています。
■チューニング前

■チューニング後

②外部予測変数を追加してみる
さて、もう少し精度を向上させたいと考えた場合、売り上げと相関関係のある変数を外部予測変数として追加してみるということが考えられます。
この外部予測変数は少なくとも目的変数を予測したい期間分だけ予測できる(“プロモーション費用”のように予定として決まっていたり、別の予測モデルで予測できたり)、
ないしコントロールできる必要があります。
※今回、外部変数になりそうな変数は2020年12月(予測期間)までダミーデータをセットしてあります。
さっそく外部予測変数投入までのステップを追ってみます。
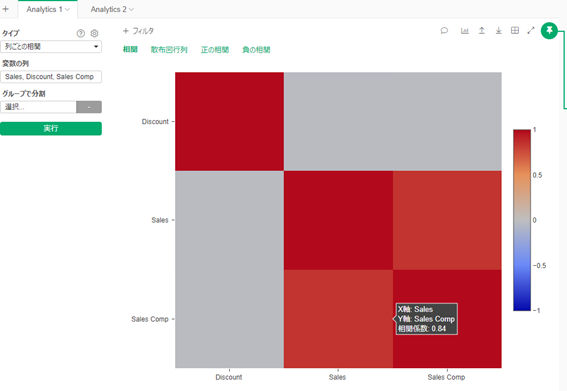
1.売り上げと相関関係の高い変数をみつける
売り上げと相関の高そうな変数を探索してみます。
今回は候補として、ディスカウントと売り上げ報酬(どちらもコントロール可能な変数です)にします。
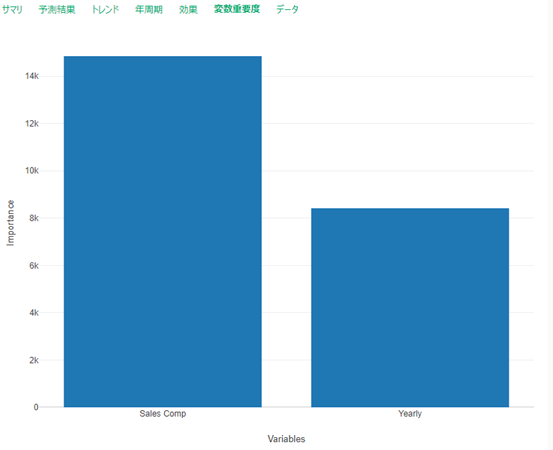
3変数の相関をみてみると、ディスカウントは無相関ですが売り上げ報酬(Sales Comp)とは相関が0.84ありました。
したがって売り上げ報酬変数を外部変数に投入し、再度テスト期間を設けて予測モデルを作成してみます。
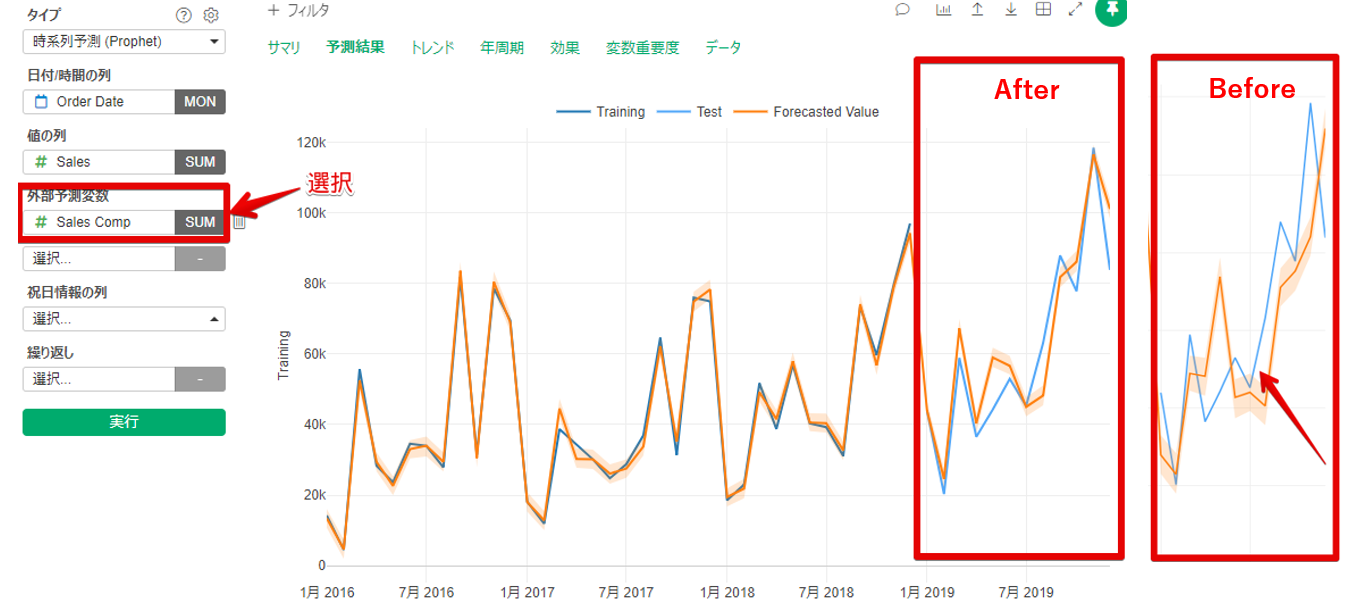
2.目的変数と関係のありそうな変数を外部予測変数に投入する
では、外部予測変数にSales Compを選択します。テスト期間の設定などは今までと同様です。
実行してみると以下の結果が出ました。
テスト期間の予測値と実測値をみるとズレが小さくなり改善しています。サマリタブで評価指標を確認すると各評価指標も大幅に減少しています。

変数重要度タブを見てみると、Sales Compが最も売り上げ予測に貢献していることがわかり、Sales Comp変数を入れたことは正解だったようです。
その他、気になる変数を同様に抜き差ししてみて、評価指標・効果・重要変数度などを見ながら
モデルのチューニングを繰り返す、というのがモデル精度向上のおおざっぱな流れになります。
ひとまず、モデル精度を上げてみる!は以上となります!
長くなってしまいましたが、実際ExploratoryのProphet分析をしてみるとモデルの作成・評価・精度の向上までかなりスムーズにできると思います。
簡単に予測モデルにチャレンジしたいという方は是非試してみてください!
複数モデルの作成(おまけ)
評価指標の項でも少し触れましたが、市場や店舗ごとに複数の売り上げ予測モデルを作成し比較したいといったケースもあります。
Exploratoryでは簡単に複数モデルを作成することができます。
今回は地域別(中央地域、東地域、南地域、西地域)に売り上げ予測モデルを生成してみます。
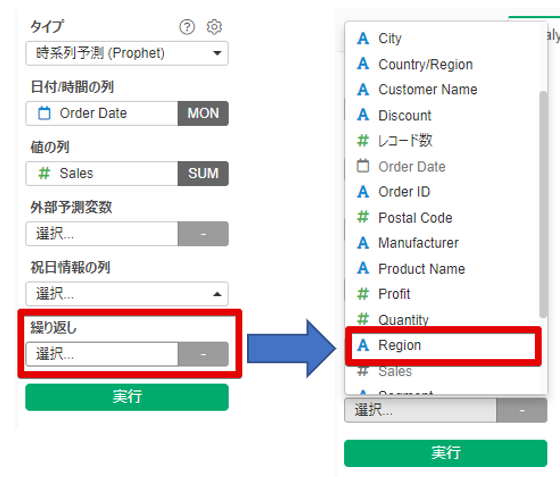
【操作手順】
メニュー>繰り返し>モデルを作成したいカテゴリー(今回はRegion別)>実行
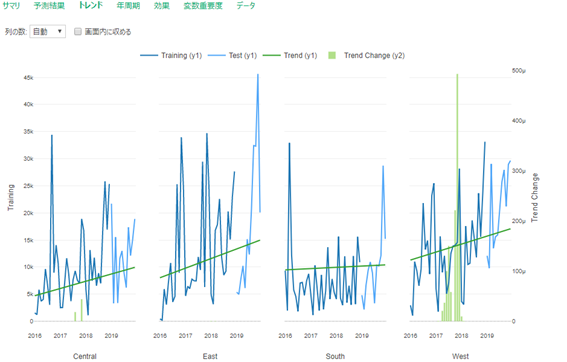
以下結果のアウトプット
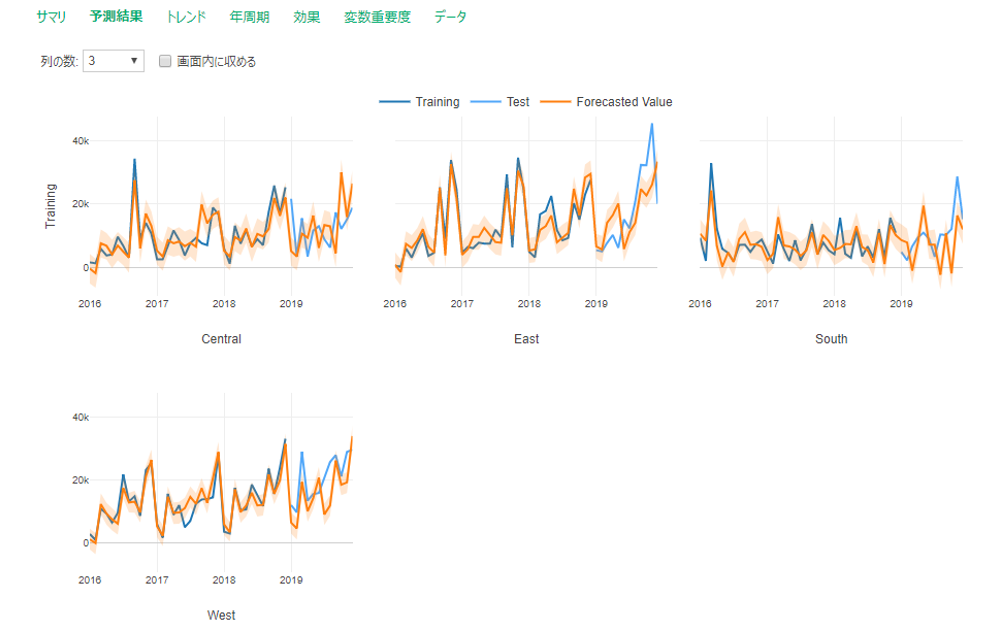

各地域の実測をみると、南・西地域の売り上げが他の地域と比べて低いようです。
したがってPMSE・MAEは低めに出ています。完全に売り上げのスケール感が同じではないのでMAPEないしMASEで評価するのが無難です。
MAPE・MASEをみると西地域モデルの評価が最も良さそうですが、MASEが89%・・・もう少しチューニングが必要そうです。。(チューニングの旅へ!)
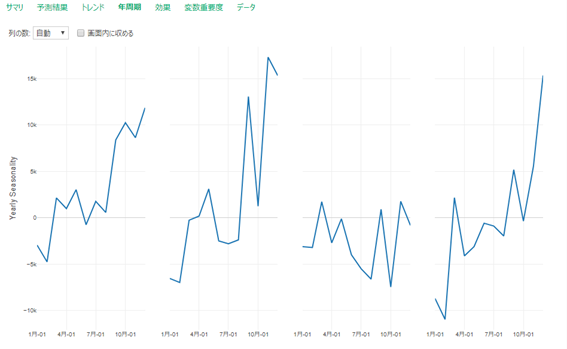
ちなみにサマリタブのトレンドと年周期も大変示唆的で、地域によって年周期が異なること、
また市場の伸びや変化点がことなることがわかります。探索的データ分析にもProphetは使えるのでお勧めです。