
前回に引き続き、Dataikuのインストール版からクラウド版に移行できるか
検証した内容をお届けします。
マネージドフォルダが無い!?
クラウド版の一番の驚きポイント、マネージドフォルダが無い!
インストール版で特に設定もいらず、なんでもかんでも保存できて便利~
と思っていたマネージドフォルダはクラウド版では使えないそうで…
サポートの方に「Managed Folder選択できたから作成してみたんだが…操作できない」と問い合わせると
「本来使えないはずなのに設定ミスか何かで表示されていたみたいだ、もう見えないはず」、
とのお答えが…そういうものらしいです。
というわけで、いろんな種類のファイル形式を一気に出力したりするときは
AWSかGCPかAzureのストレージサービスを使用する必要があります。
私はAWSのS3の使用しました。
RとPythonでフォルダへの書き込み方法が異なるので、まずRのお話から。
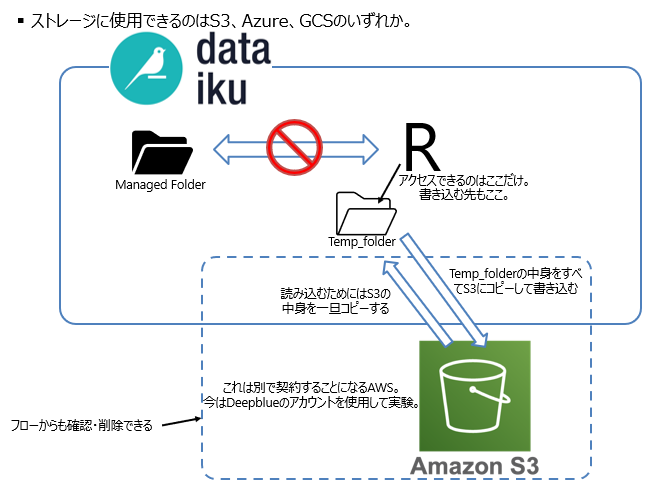
クラウド版ではフォルダは外部のストレージサービス(私の場合はS3)になります。
Dataikuのフローからストレージには直接書き込めないようなのです。
そこで登場するのがTemp folder。
ざっくりイメージ図にすると以下のようになります↓
Rコードレシピからフォルダに書き込む場合
上の図にあるように、直接S3には書き込めないので一時保存フォルダを作成します。
# Creating a temporary directory
temp_dir <- tempdir()
私が検証していたRobynのノートブックは繰り返し実行することが想定され、
その度に別のフォルダに書き出してほしかったのでサブフォルダを作成するコードを追加します。
# Generate data and copy multiple files
current_datetime <- format(Sys.time(), “%Y%m%d%H”) # Get current date and time
plot_folder_sub <- file.path(tempdir(), current_datetime) # Creating a subdirectory within the temporary directory with the current date and time
dir.create(plot_folder_sub) # Creating the subdirectory if it doesn’t exist
サブフォルダに書き出すのはRobynの出力機能を使用しています。
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
plot_folder = temp_dir, # path for plots exports and files creation
plot_folder_sub = plot_folder_sub,
pareto_fronts = “auto”, # automatically pick how many pareto-fronts to fill min_candidates (100)
csv_out = “pareto”, # “pareto”, “all”, or NULL (for none)
clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters
export = TRUE, # this will create files locally
plot_pareto = TRUE # Set to FALSE to deactivate plotting and saving model one-pagers
)
その他Rコードで作成したcsvなども同じくtemp_dirに保存しておきます。
output_folder_id <- “XXXXXXXX” # Replace “XXXXXXXX” with the actual folder ID
id_df <- data.frame(ID = ids) #適当なデータをデータフレームに格納
# CSVファイルとして保存
write.csv(id_df, paste0(temp_dir, “/ids.csv”), row.names = FALSE)
一通りtemp_dirに書き込んだら、S3にフォルダをまるごとコピーします。
# Copy files from the subdirectory to the Dataiku folder
dkuManagedFolderCopyFromLocal(output_folder_id, temp_dir)
S3にコピーをするとやっとフロー上のフォルダに出力したファイルが現れてきます。
ちなみにAWSのコンソールにログインしてS3の画面からでもファイルが書き込まれたのを確認できます。
Rコードレシピからフォルダの中身を読み込むとき
Rのノートブックから今フォルダに何が入っているかを確認するためには以下のコードを実行します。
dkuManagedFolderPartitionPaths(folder_id)
ストレージに格納したファイルは「リモートにある」という表現をサポートの方はされていました。
フロー上で動かすにはファイルが「ローカルにある」状態が必要だそうです。
↑のコードでリモートのフォルダに何があるか確認した後、ローカルに移す必要があります。
ここで言う「ローカル」は書き込む際にも使用したtemp_dirです。
temp_dir <- tempdir() # Creating a temporary directory
dkuManagedFolderCopyToLocal(folder_id, temp_dir)
書き出したフォルダのID(読み込むRノートブックにとってはインプット)を入力し、
一度リモートのフォルダの中身を全部ローカルに移して、
その後データを加工するなりいろいろRコードを実行しましょう。
次回はPythonでフォルダに書き込んだり読み込んだりする場合をご紹介します。





