
こんにちは、Deepblueのひめのです。
Dataikuを最新のV12にアップグレードしました!
いろいろ新しい機能が追加されています。V12の詳細はこちら(公式サイト)からご確認ください。
早速新しい機能を試しました!!今回はGenerate Featuresです。
機械学習のデータを用意する際に特徴量をいろいろ作ると思うのですが、よくやる作業をまとめてやってくれちゃう機能です。
V12にアップグレードしたらアイコンがこんな風に増えてます。
Connectionsの設定
Generate FeaturesはSQLのデータに対してしか実行できない機能なので、SQL形式のデータベースへの接続が必要です。
データの書き出し先という意味で必要なのと、処理を実行するエンジンもDSSではなくてIn-database(SQL)になります。
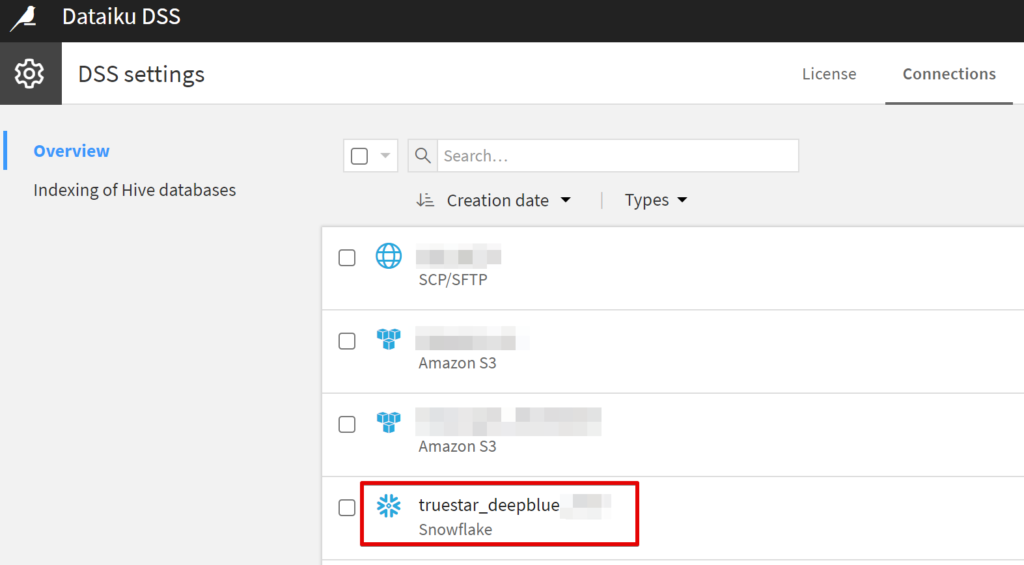
Administrationメニューから追加できます。
弊社はSnowflakeを使用しているのでDataikuからSnowflakeへの接続を作成しています。
データの準備
今回はTableauのSuperstoreのデータをcsvで落として、Dataikuのフローにアップロードしました。
SQLデータ用の処理なので、普通のcsvのデータを指定してアクションボタンを押してもグレーアウトしています。

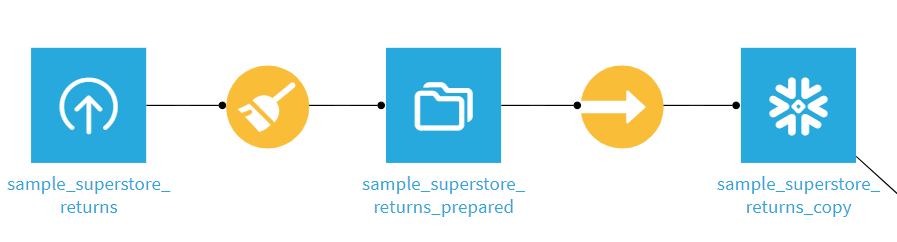
そのままでは使えないのでSyncしてSnowflakeにデータを置きます。
最初からSQLデータを読み込んでいる場合はSyncは不要です。

SQLの形式にしたいデータを選択してSyncアイコンを押すとポップアップが出るのでStore intoのプルダウンで先ほど作成したconnectionを指定します。
Create Recipeを押すとフロー上で新しいデータベースが作成されます。(今回の私のケースではSnowflakeマーク)
Generate Featuresを使ってみよう
SQLのデータアイコンをクリックし、ActionsからGenerate Featuresを選択します。
アウトプットは同じくSQLを指定します。そしてレシピの設定画面がこちら↓
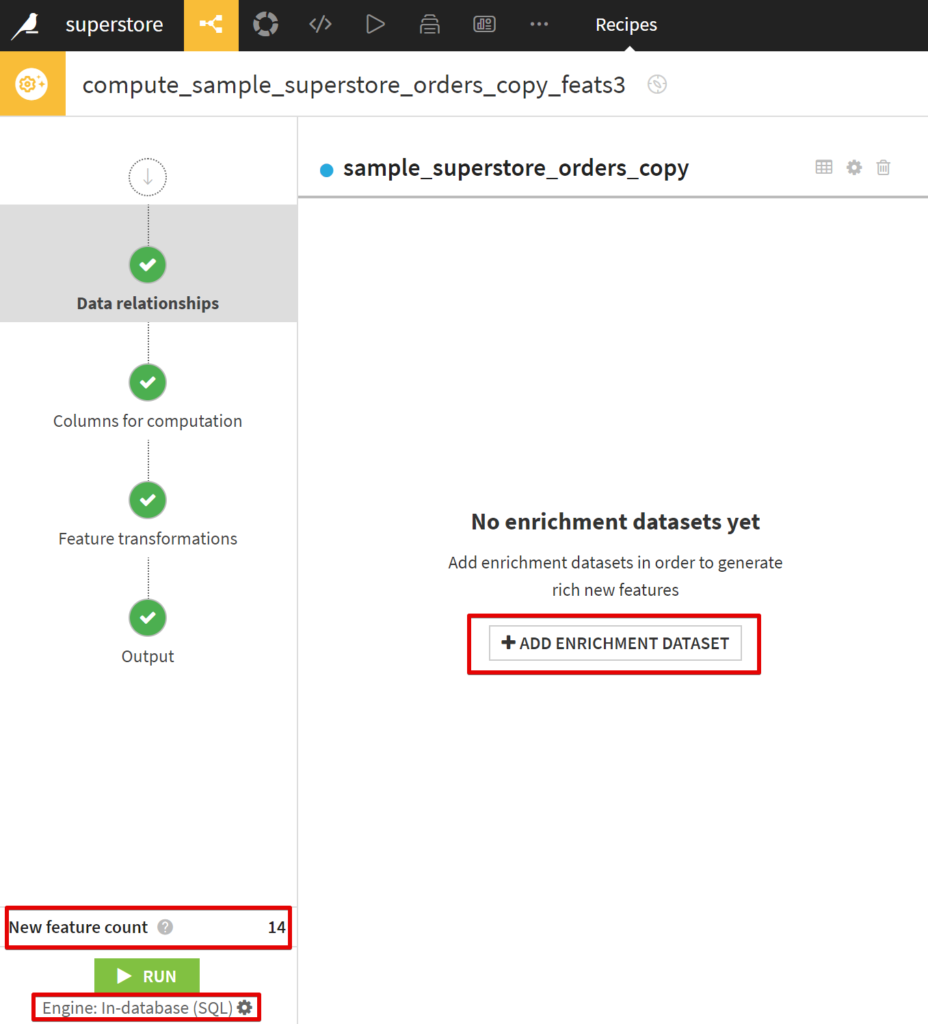
New feature countがこのままRUNすると生成される特徴量(列)の数です。
また、RUNの下にIn-database(SQL)のエンジンを使用する、とあります。
設定は大きく4ステップに分かれます。
- Data Relationships
- Columns for computation
- Feature transformations
- Output
1.Data Relationshipsの画面が最初表示されています。Enrichment Datasetを追加してJOINができます。
ただし必須ではないです。そしてEnrichmentに使うデータもSQL形式である必要があります。
JOINする場合は3種類から選べます。
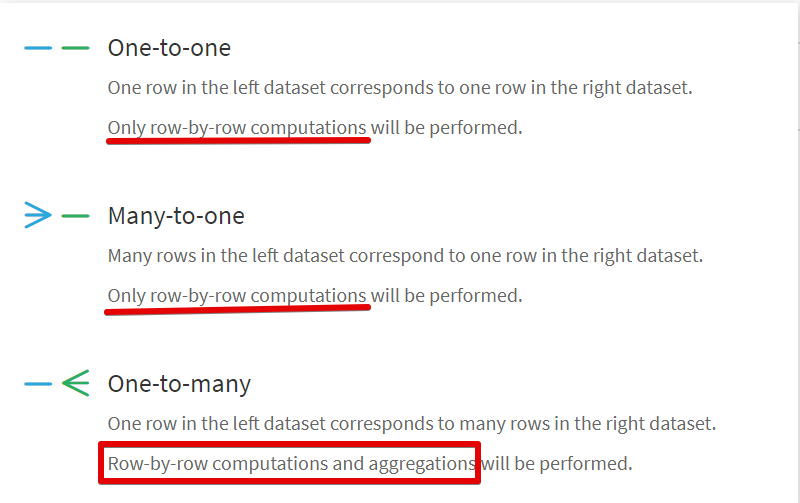
aggregationができるのはOne-to-manyのタイプだけです。One側の項目単位で集計することになります。
どれもLeft JOINなのでメインにするデータベースを先に指定して、右側にくるデータセットをEnrichmentとして指定します。
キーを指定して次のステップに進みます。
2.Columns for computationで使用する列とデータの形式を選択します。
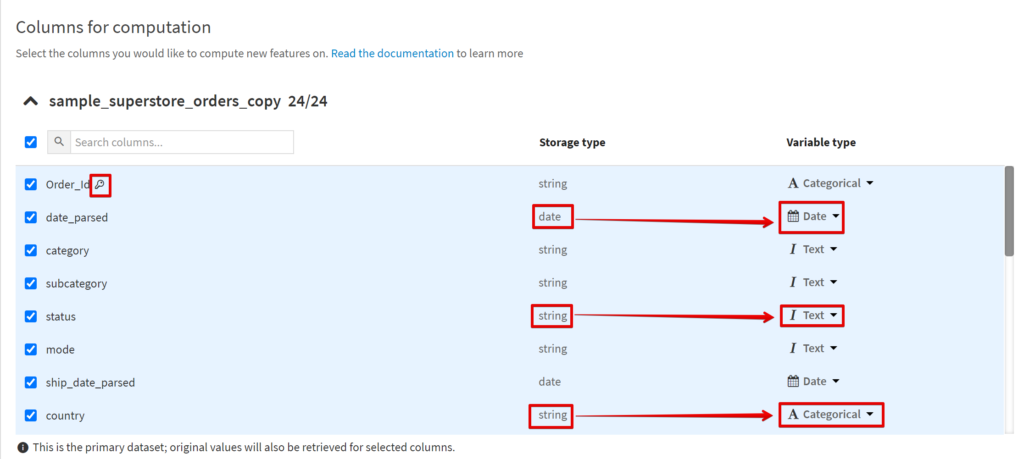
鍵マークがついているのが前のステップで指定したキーです。
Storage typeに応じて選択できるVariable typeが異なります。
(私が最初にやった時は数値も日付も全部String扱いになっていたのでPrepareで直しました)
Variable typeによってどういう特徴量を作成するかが異なるので、一旦次のステップの画面を確認します。

StringもCategoricalにするのか、Textにするのかで挙動が変わります。
必要ない特徴量は外します。例えば日付でHourを取り出してくれても別に要らない、とかTextでWord countをしてくれても今回は使わないのでチェックを取ります。
今回の例では注文のデータに返品のデータをOne-to-manyで接続しています(One-to-manyじゃなくても別にいい例になってしまった)が、も集計する指標が特に無いのでRow-by-rowの挙動になりました。
ここでどういう特徴量が生成されるのかを確認して前のステップに戻ります。不要なものはチェックを外しましょう。
※LEFTJOINなので左側のデータのオリジナル列は全て出力されます。
- Outputに移って出力される予定の内容を確認します。
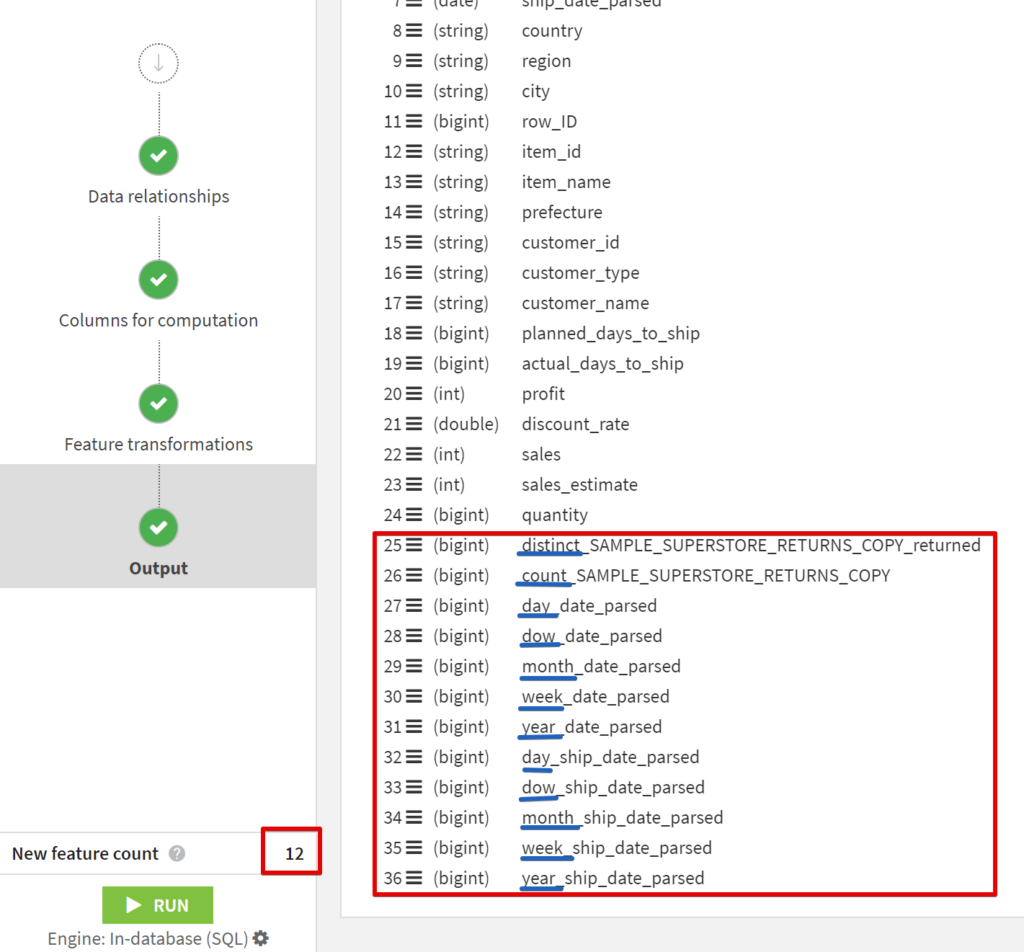
今回は12列増える予定で、distinct やcount、日付のparse結果がそれぞれ追加されています。
問題が無ければRUNして結果を確認します。
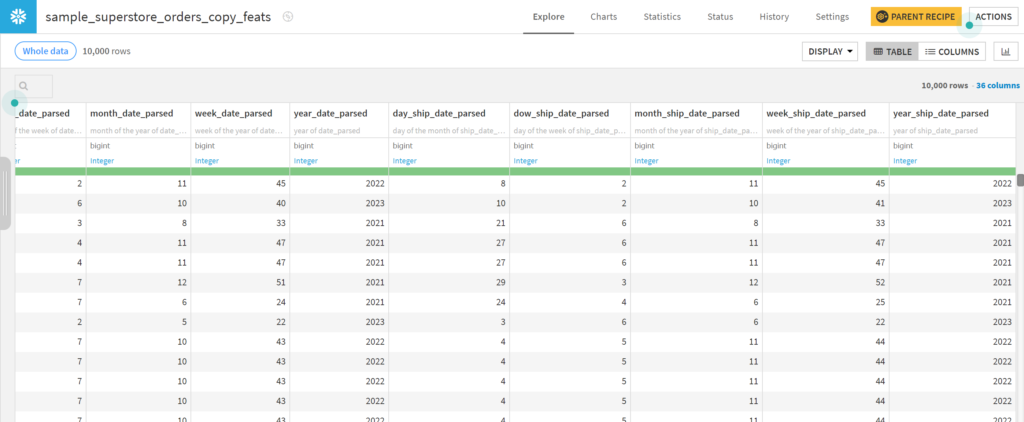
無事に特徴量を追加できました!
Aggregationの結果を見たかったのでリベンジ
Order_IDというユニークな列が入っていたので集計のしようがなかったことに気付き、Aggregateされた例も欲しかったのでやり直した例も書いておきます。
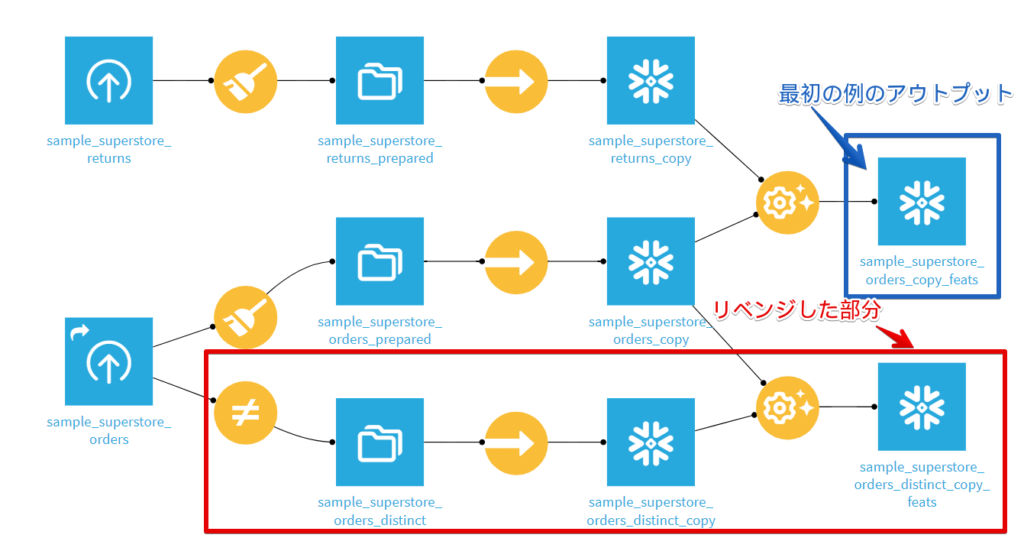
One-to-manyのJOINをしたかったので赤枠の中でDistinctのレシピを追加しています。

One-to-manyにしたいのでLEFTに来るように、このカテゴリーとサブカテゴリーのユニークなリストを先に指定してGenerate Featuresを選択します。
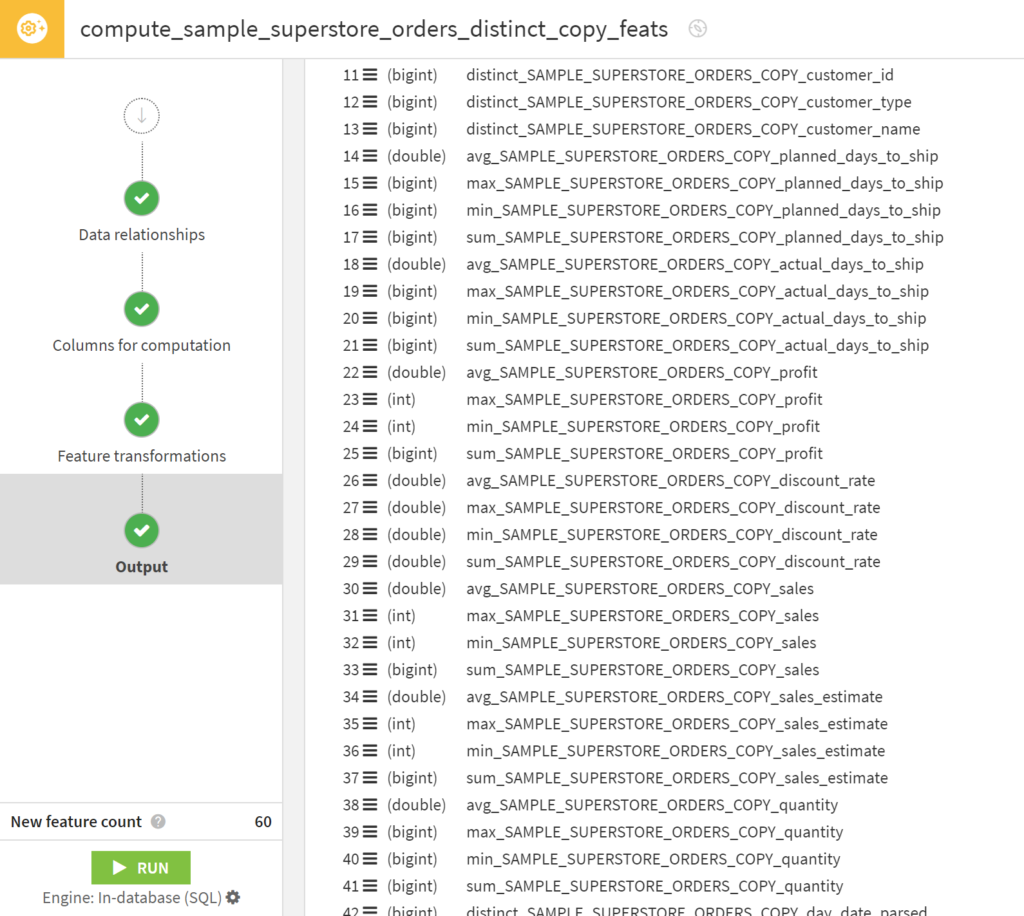
数値データをカテゴリー毎に集計してくれそうなOutput画面になりました。
RUNしたら60列増える予定です。
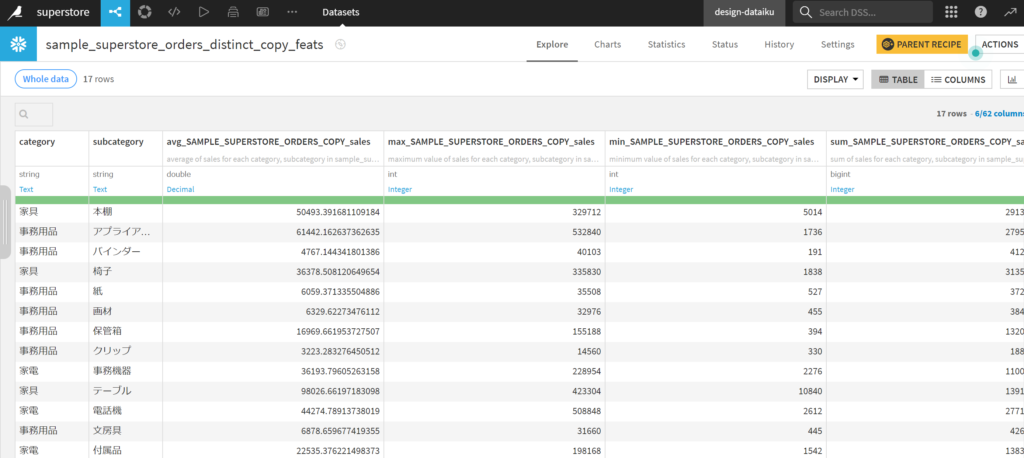
カテゴリーとサブカテゴリー単位で平均や最大値の計算ができています。
無事にAggregateバージョンもできました。
まとめと感想
Alteryxでもデータ加工して最大値と平均値をそれぞれの指標に対して作成する、ということができるのですがちまちま操作していると間違いそうになるので、まとめて一気に作成できちゃうのはうっかりが減りそうでいいな、と思いました。
日付データを分解するのも楽だと思います。
(今回のテーマ関係無いですが、Alteryxのdate parseって結構厳格ですぐエラーになっちゃうんですが、その点Dataikuはもっといい感じに処理してくれるのがいいですね。)
(Syncすればいいんですが)SQLじゃないとできないのであれば特にデータの項目が少ない時は従来のPrepareで頑張ってしまうかも、という気もしました。うっかりを減らす、という観点であればレシピにして使いまわすのもアリな気もします。
Aggregateされた結果を元データに再度JOINしないと特徴量として機械学習モデルに使えないので(もうちょっといい方法あるのかもしれないのですがまだたどり着いてません)、そこまで一気にできるようになると使い勝手がさらに良くなる気がしました。
処理スピードに関してはデータが小さいこともあってあまりSQLにして早くなった、という気はしませんでした。
ただV12にアップグレードしてから全体的な処理速度はかなり上がったと思います。
Alteryxに比べて各ステップが遅いな、と思っていたのですが差が小さくなった気がします。
個人的な反省としては使用するデータの種類によっても効果の実感が違うかもしれない、ということです。次回以降どういうデータで試すか、も考えていきたいと思います。
次はData Catalogについて記事にしたいと思います!
ではまた!





