
はじめに
先日、dataikuのMLpractitioner資格取得に向けた学習をしていたところ、Dataikuのパーティションという機能について初めて知りました。私の周りでも意外とパーティション機能を知らない・使っていないというメンバーが多かったため、今回はdataikuのパーティション機能について簡単にご紹介してみたいと思います!
パーティションとは?
Dataikuにおけるパーティションとは、データセットを任意のdimention(例:日時やカテゴリなど)で分割する機能です。この機能には以下のような特徴があります。
・各パーティションは独立して処理され、他のパーティションに影響を与えない
・新しいデータが追加された場合、該当するパーティションのみを構築可能
・処理がパーティション単位で実行されるため、パフォーマンスの向上が期待できる
データセットのパーティション分割方法
では実際に、Dataikuの公式ドキュメントTutorial | Repartition a non-partitioned datasetのサンプルプロジェクトを使用しながら、
Dataiku上でデータセットをパーティション分割する方法を解説します。
データセットの準備
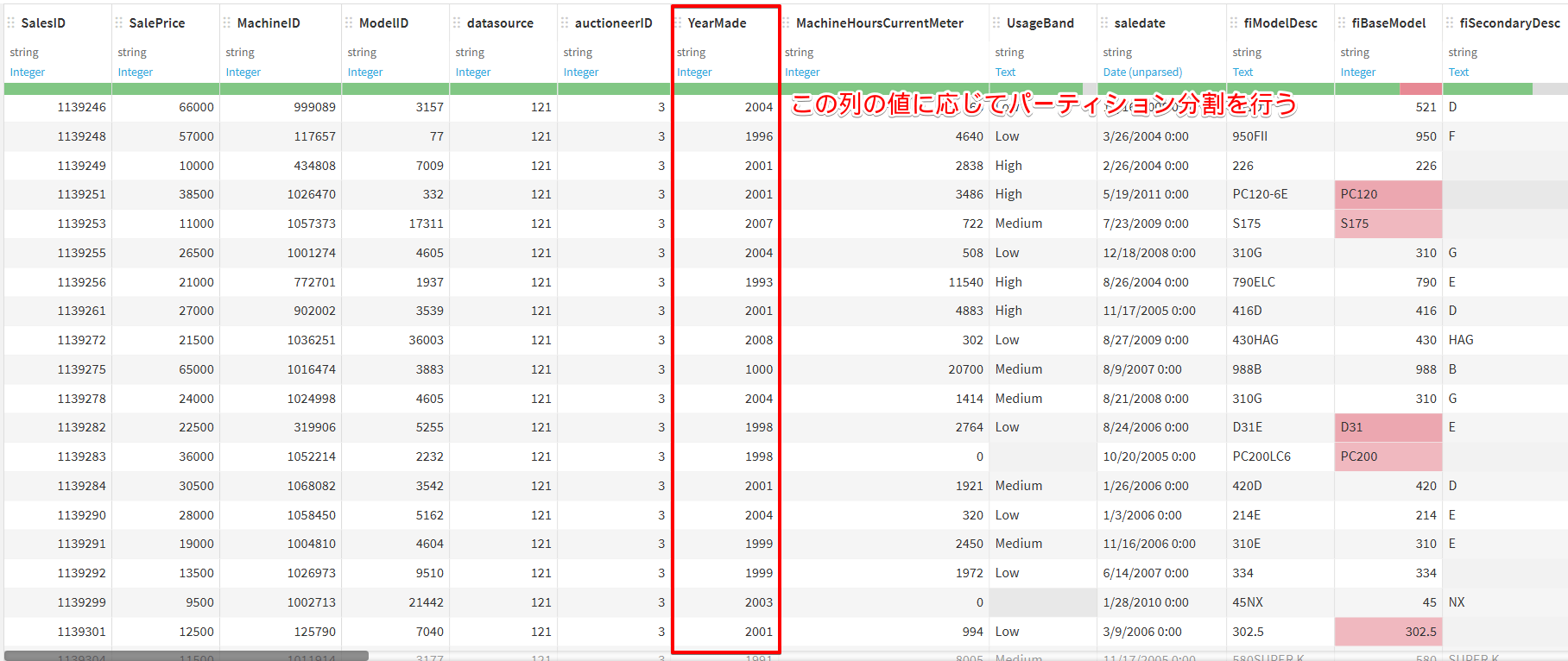
今回使用するデータの中身は下図のようになっており、以下ではYearMade列を使ってパーティション分割を行っていきます。
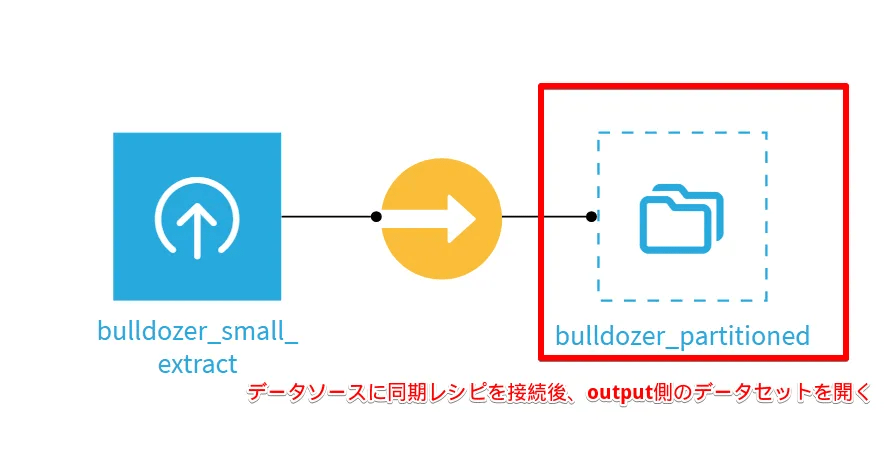
まずはDataikuのプロジェクト上にアップロードされた上記データセットに対して、同期レシピまたは準備レシピを接続して、レシピからアウトプットされたデータセットを開きます。
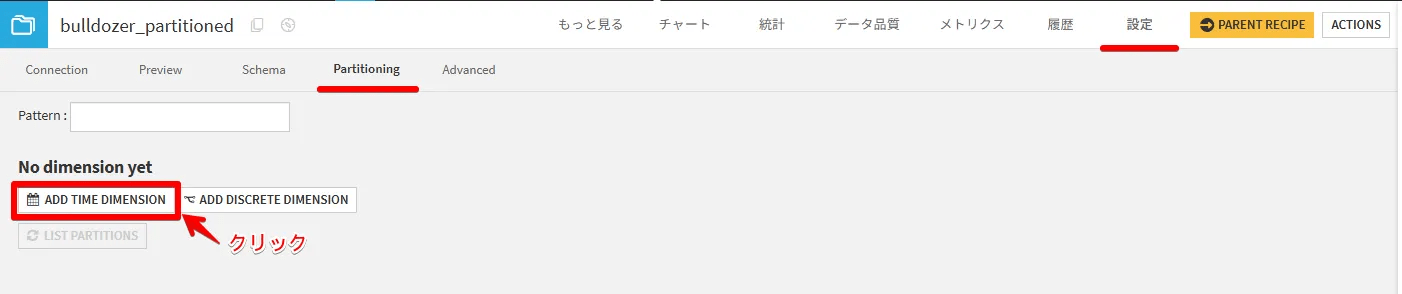
パーティションの設定
次にデータセットの設定タブ内のPartitioningタブで、どのようにパーティション分割するか定義設定します。
今回は「ADD TIME DIMENSION」を選択します。(パーティション分割したいカラムが、日時情報ではない場合(カテゴリ情報など)は「ADD DISCRETE DIMENTION」を選択してください)
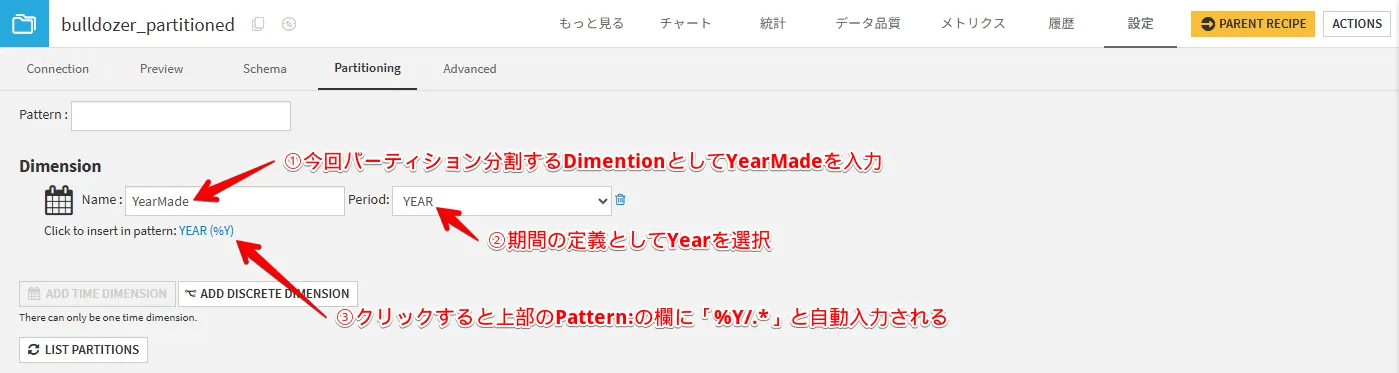
「YearMade」カラムをディメンションとして分割したいので、以下の図のように入力を進めます。(入力後に設定を保存してください)
レシピの実行
データセットから同期レシピに戻り、「入力列に応じてパーティションを再ディスパッチ」をオンにした状態でレシピを実行します。
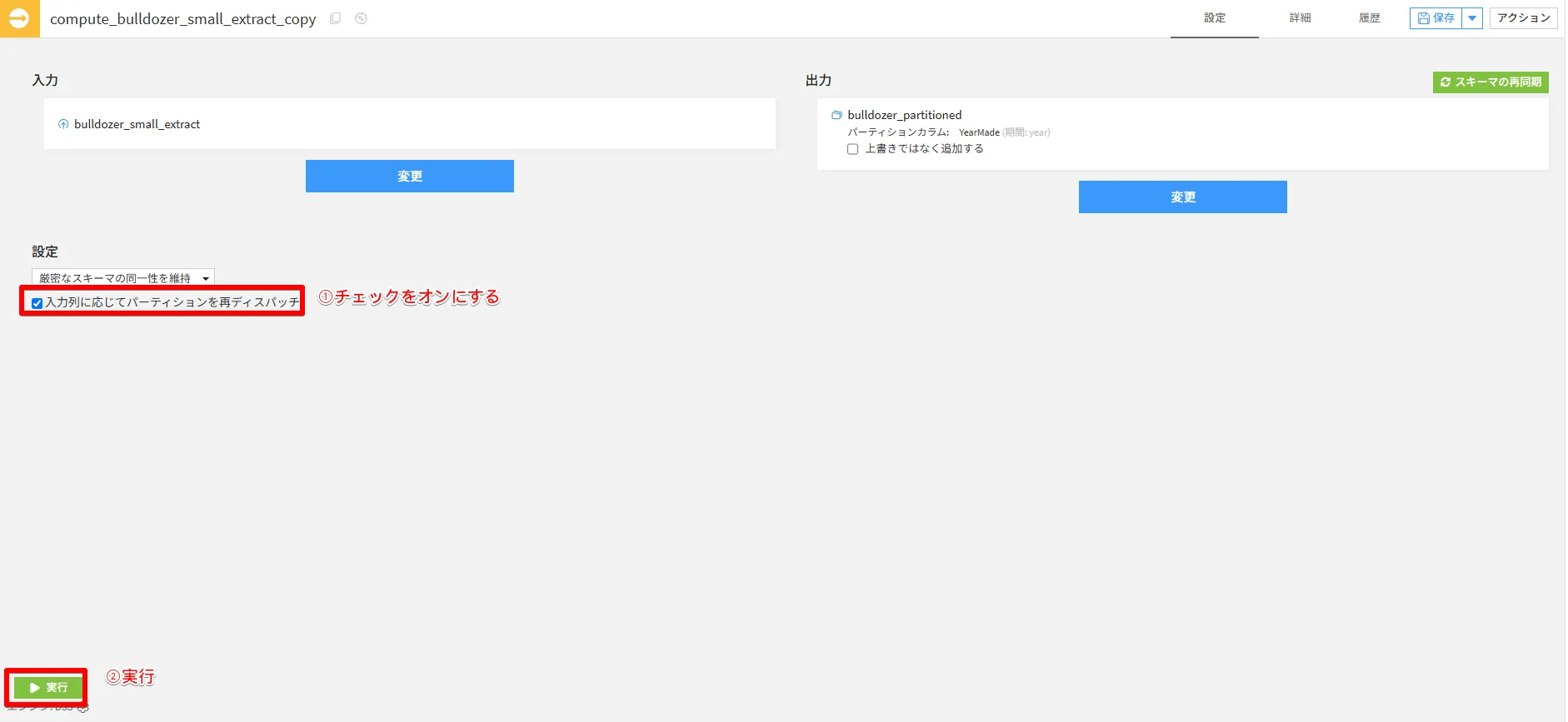
実行が終わるとデータセットがパーティション分割されます。(アイコンが重なって表示されており、パーティション分割されてことがわかります。)
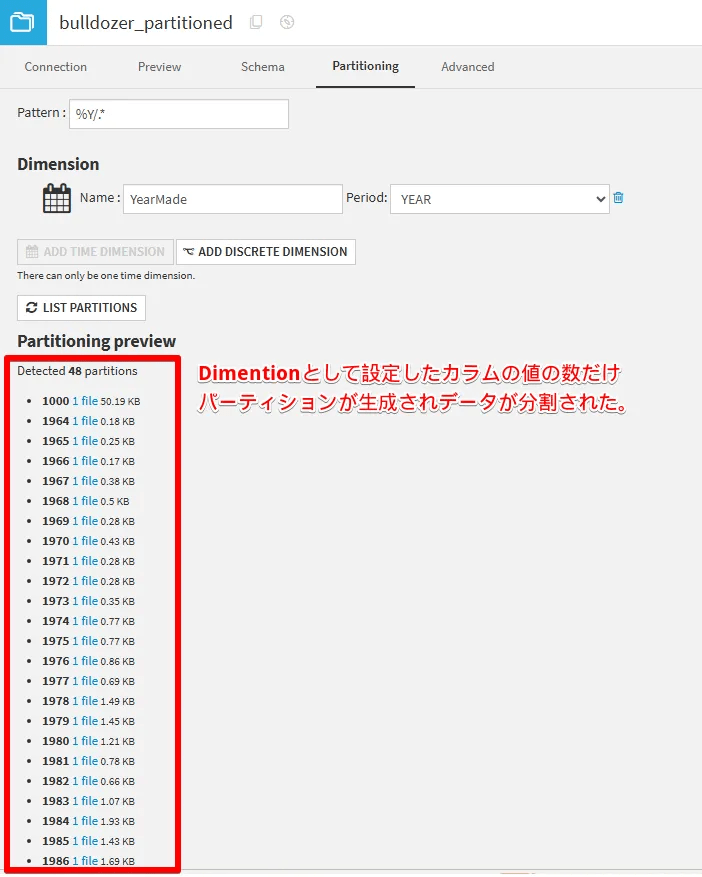
なお、この状態でデータセットのパーティション設定を確認してみると、どのようなパーティションに分割されたのか確認することが可能です。
YearMadeカラムに基づいて、48個のパーティションに分割されたことがわかります。なお、Dataiku上でパーティション分割されたデータは、ファイルそのものがパーティションの数だけ分割されて保存された状態になっています。(今回のbulldozer_small_extractデータセットはもともと1つのcsvファイルのデータですが、パーティション分割後のデータセットは48個のファイルに分割されています)
パーティション分割のメリット
Dataikuでは処理がパーティション単位で実行されるため、データが更新されたパーティションについてのみ処理を行うなどにより、実行時間が短縮されたりなどのパフォーマンス改善が期待できます。
また、Dataikuでは機械学習にパーティション分割されたデータセットを用いることができ、パーティションごとにモデルのトレーニングを行うことが可能です。これにより、機械学習モデルの精度が向上する場合があります。
パーティションモデル実践
ここでは具体的な例として、フライトの到着遅延時間を予測するモデルの開発事例を紹介します。
なお、以下ではDataikuのチュートリアルとして用意されているTutorial | Partitioned modelsのプロジェクトを使って解説します。
このデータセットはフライトの目的地の州(floridaまたはcalifornia)ごとにパーティション分割されており、
データセット全体をモデルのトレーニングに使った場合と、パーティションごとにモデルをトレーニングした場合でモデルにどのような性能差が表れるのか確認することができます。
パーティションモデルの作成方法
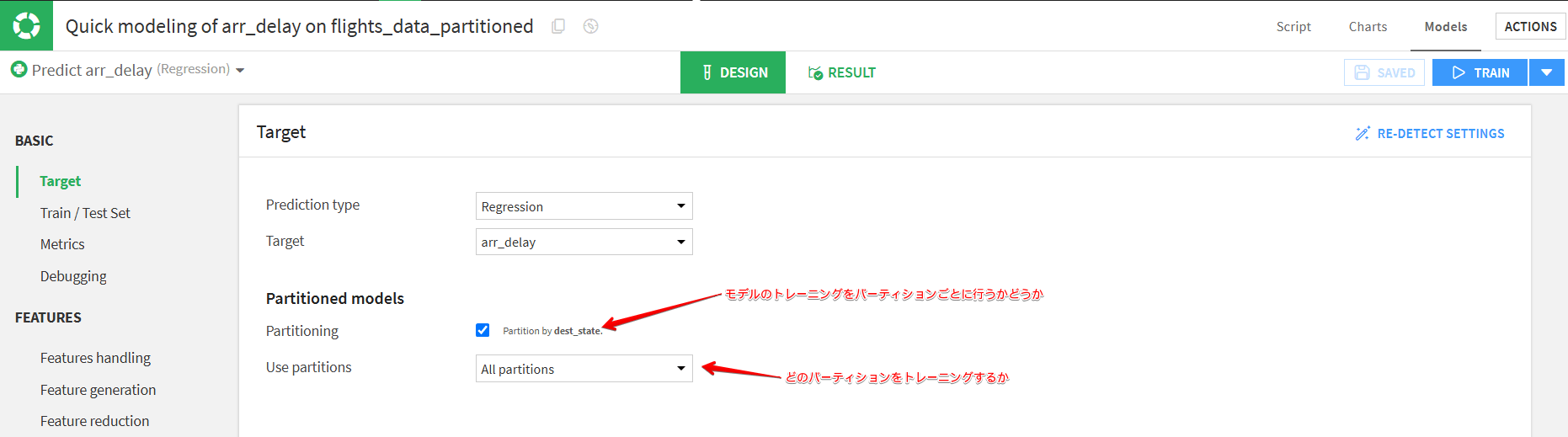
パーティション分割されたデータセットからモデルのトレーニングを行う場合、設定画面で「Partitioning」と「Use Partitions」の項目の設定を行うことができます。
「Partitioning」設定ではモデルのトレーニングをパーティションごとに行うかどうかを設定することができます。このチェックボックスをオンにしない場合はトレーニングがパーティションごとではなく、全データを使用した単一モデルが作られます。
「Use Partitions」設定では、どのパーティションをトレーニングするか設定することができ、All Partitionsを選択すれば全てのパーティションで個別モデルが作られます。一方で、ここでパーティションを個別選択すれば特定のパーティションだけの個別モデルが作られます。
パーティションモデルの性能
実際にモデルのトレーニングを行うと、フライト到着遅延時間予測モデルのR²スコアは下記のようになります。(ここではランダムフォレストを採用しています。)
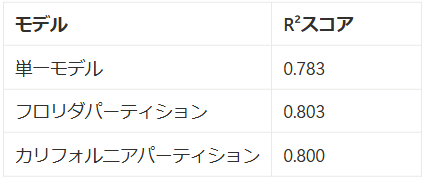
単一モデル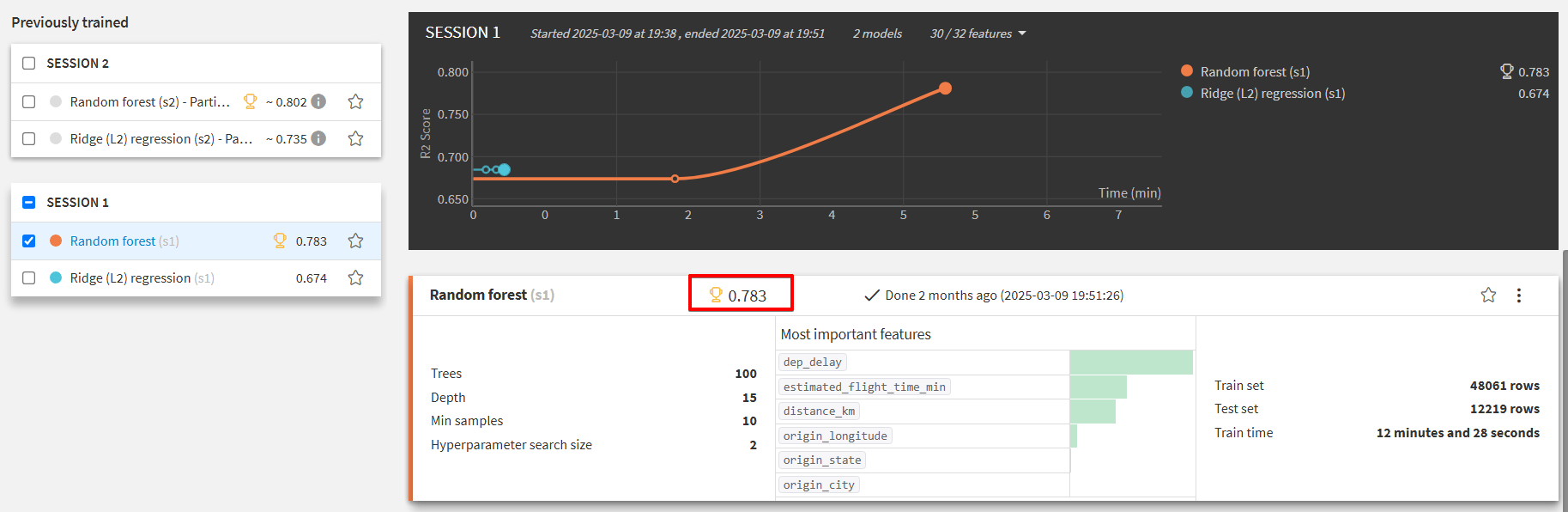
パーティションモデル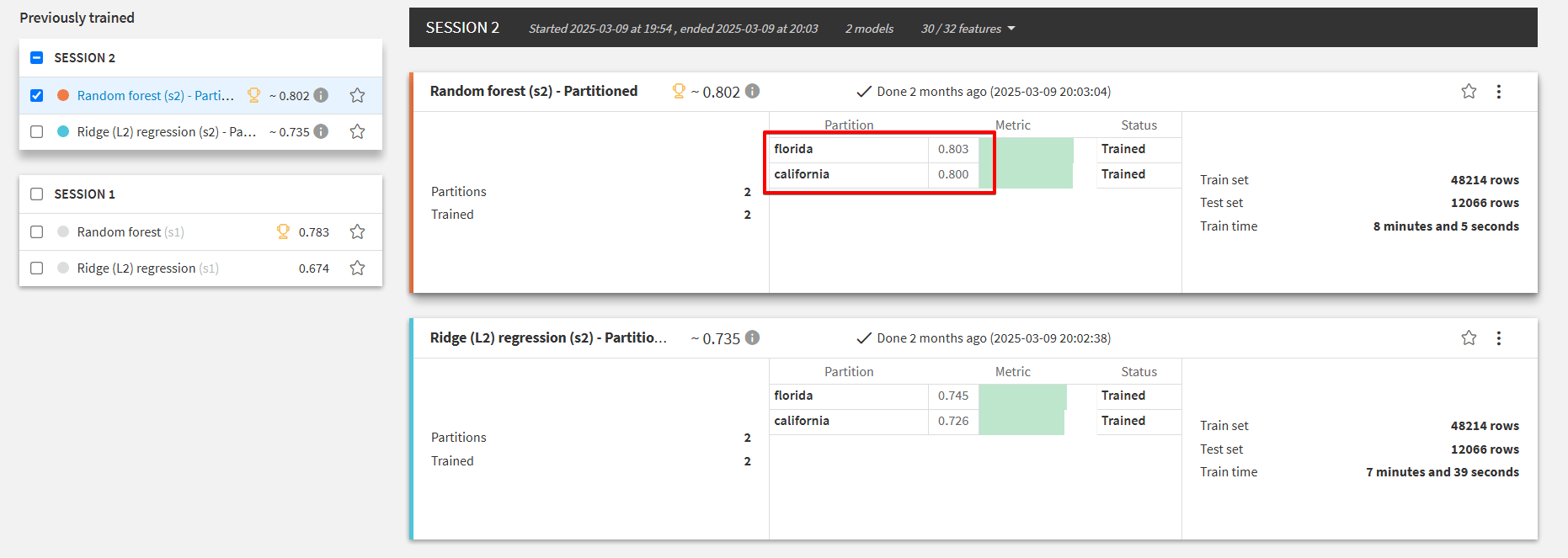
このように単一モデルに比べて各パーティションごとにトレーニングを行ったモデルのほうが、わずかではありますがパフォーマンスがよいように見受けられます。
これは、データセットのサブグループが異なる特性を持つ場合があり、それによって特徴量全体に異なるパターンが現れる可能性があるためです。
パーティショニングが効果的なケース
上記のように、機械学習を行う際にもパーティション分割したうえでモデルのトレーニングを行う方が効果的である場合があることがわかりました。
基本的には、以下のような状況においてパーティション分割したモデルを採用すると、モデルの性能が向上する場合があります。
・データのサブグループごとに異なる特性がある場合(季節性、消費者行動など)
・カテゴリカルデータで明確なグループ分けができる場合
・時系列データで期間ごとの特徴が大きく異なる場合
もちろん必ずしも性能が向上するわけではありませんが、モデルの性能向上で行き詰った際などは試してみてはいかがでしょうか?
おわりに
以上見てきたように、パーティション機能を活用することで、フローの処理速度やモデルの精度が向上する可能性があることがおわかりいただけたと思います。
パーティション分割自体も簡単に実装できるので、地域性が特徴が強いデータセットなどでは試しにパーティション分割してみることをおすすめします!
truestarではDataikuの検討、導入支援や環境構築から導入後の運用まで幅広くサポート可能です。
Dataikuに興味がある、導入済みだけどもっとうまく活用したい等々ありましたら、ぜひこちらからご相談ください。





