
はじめに
dbtの基礎知識理解とdbt Analytics Engineering Certification Examを受験するために
学んだことのアウトプットも兼ねて公式トレーニングの内容をブログ化します。
今回は第一回目のdbt Fundamentalsを紹介します。
dbt Fundamentals概要
概要は以下になります。動画とドキュメントを行き来して最後にQuestionを解く形式です。
実践はdbt cloudとSnowflakeを用いて行います。
サンプルコードがあるのでSQLが書けなくても、実装の流れは理解できます。

コースの内容は以下になります。
dbtの長所であるTransformation、変更管理、ドキュメント化、デプロイに関連する項目を一通り学びます。

個人的に辛かったポイントは、動画の字幕が英語かスペイン語しかない点です。
なので、実践→レビューでドキュメント読む→動画視聴で復習の流れで学習しました。
Who is an analytics engineer?
この章では従来のデータチームの役割、ELTの台頭による変化、dbtの役割について解説しています。
ざっくり説明すると、今まではETLプロセスを維持するエンジニアと、データを分析するアナリストの関係が
ELTの台頭によってELに集中する人と分析用にTransformationする人に分かれたよ的な話をしています。
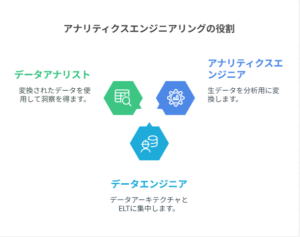
「で、俺が産まれたってわけ」とまでは言っていないのですがTransformationに集中できるようになったので
ソフトエンジニアリングの原則に倣った変更管理やモジュール化ができるdbtを活用していきましょうと章を結んでおりました。
Set up dbt Cloud
クイックスタートに則りdbt Cloud IDEのset upをします。
使用しているプラットフォームのドキュメントを読んで、dbtからデータ操作をできる設定をします。
クイックスタートのドキュメントと講義の内容が若干異なるため
最後まで実装をせずデータを準備する段階で
クイックスタートは止めた方が良い、というのが実践をする上でのtipsです
この章では特に実践はせずdbt Cloud IDEのレイアウトやざっくりとした使い方を教えてくれるのみなので
触りたい方はModelsにすぐ移ってもよいかもしれません。
Models
この章ではモデル、モジュール性、参照マクロを学習します。
一番実践的でdbtの本質を学べる分野になります。
モデル
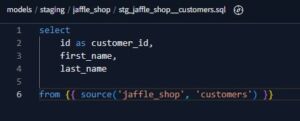
dbtはsqlファイルを元にモデル構築をします。
モデルの一番の特徴としてはDDL/DMLを記述せず、SELECT分のみで作成できる点にあります。
例えば以下の場合記述はSELECT文のみなります。
一方で、dbt runをするとCompileしてくれてプラットフォームに上げる際にCreateしてくれます
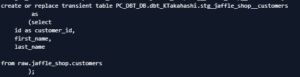
DDL/DMLを書かずにモデル構築できるため
簡単なSELECTを知っていれば誰でも作成可能な点がdbtの強力な点の一つになります。
モジュール性
モジュール性とは、システムを分割し、再組み立て可能な構造を指します。
dbtの設計思想として、「モジュール性」の活用が推奨されております。
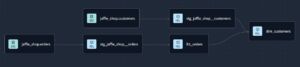
例えば、今回のモデル例ですとSQLを一個所に記述するのではなく、
顧客データと注文データをそれぞれステージングし、整形した上で、それらを参照する中間モデルを作り、最終的な dim_customers を構築します。
「モジュール性」を活用することで、より柔軟で再利用可能な形でデータを構築できます。
参照マクロ
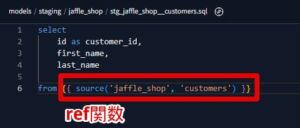
dbt では、モデル間の依存関係を管理するために ref 関数を使用します。
これにより、テーブル名をハードコードすることなく、柔軟で共有可能なコードを実現できます。
この関数を使うことで、開発環境に依存せずにモデル間の関係を定義でき
dbt はそれらの依存関係を自動的に把握して、正しい順序でモデルを構築します。
命名規則
dbt推奨の命名規則になります
| 接頭語 | 名称 | 主な内容・用途 | 備考 |
|---|---|---|---|
src_ |
ソース(Source) | データウェアハウスにロードされた生データテーブル | ソース定義に基づいて構成され、元データとして機能する |
stg_ |
ステージング(Staging) | ソースと1対1の関係。軽い変換・クレンジング・標準化に使用 | 通常ビューとして実体化され後続の 中間・ファクト・ディメンションモデルの前処理として使われる |
int_ |
中間モデル(Intermediate) | stg_モデルを元に構築。集計・結合・加工を行う中間処理 |
ステージング層を活用し、より高度なロジックや結合を含む変換を行う。通常は最終テーブルの構築に利用される |
fct_ |
ファクト(Fact) | イベントやアクションの事実データ (例:注文、セッション、投票など) |
通常、細長い形状(long format)で表現され 時系列や数量的分析の基盤となる |
dim_ |
ディメンション(Dimension) | 人・物・場所などの属性情報(例:顧客、製品、従業員など) | 分析軸として使用され、ファクトテーブルと結合して意味のある インサイトを得るために利用される。正規化モデリング手法に由来 |
フォルダ
dbtはmodelsディレクトリ内の全モデルが実行されます。
このフォルダ構造を活用することで、モデル管理が明確になるため推奨されている形になります。

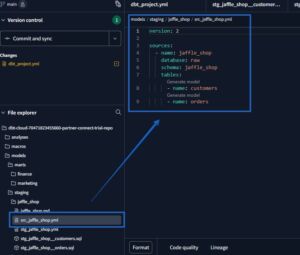
Sources
ソースとは、データウェアハウスにロードされた生データを指します。
source() 関数を使うことで設定の一元管理、系統グラフでの表示、freshness機能の利用など恩恵を受けられます。
ソースは、モデル ディレクトリ内の YAML ファイルで構成されます。
Tests
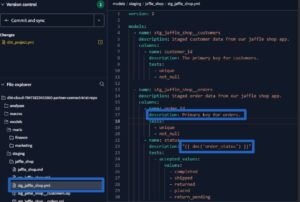
TestはSQL変換が期待通りのデータモデルを生成しているかを検証する手段。
Testにはuniqueやnot_nullなどYAMLで設定する再利用可能な汎用テストと
特定シナリオのためのSQLクエリで記述した特異テストがあります。
その他dbtで用意されたパッケージを利用したテストも存在するため
用途に合わせてカスタマイズをすることも可能になります。
Documentation
dbtはドキュメント作成ができます。
YAMLファイルに記述しdbt docs generateを実行することで作成されます。
ドキュメントはmdファイルなどでブロック化することも可能です。
Deployment
dbtでは開発環境とブランチを使用することで
本番環境に影響を与えずにプロジェクトのビルドができます。
この章では基本的な環境の作成やjobスケジュールの操作に留まっていました。
詳細はdevelopment advancedコースで説明されるそうです。
さいごに
Fundamentalといいつつボリューミーで実装と概念も学べるので
無料で良いのかと思えるくらい良質なコースでした。
次回はdevelopment advancedを受講して、ブログにまとめたいと思います。
参考文献
dbt Fundamentals
https://learn.getdbt.com/learn/dashboard
dbtクイックスタート
https://docs.getdbt.com/guides/snowflake?step=1
Sourceドキュメント
https://docs.getdbt.com/reference/source-properties
Testドキュメント
https://docs.getdbt.com/reference/node-selection/test-selection-examples





