
こんにちは、ひめのです。
『Dataiku上で構築した機械学習モデルをノンコーダーでも使えるようなアプリにしたい!!』
紆余曲折を経て完成しました!
はじめに
今回作成したのはMeta社が公開しているRobynというパッケージを動かすプロジェクトです。
MMM(マーケティングミックスモデリング)のためのパッケージで、Rで動きます。
時系列の広告データ、コンバージョンデータ、目的変数(売り上げなど)、
外部要因(降水量やコロナ新規感染者など)を入力してモデリングしてくれます。
↑
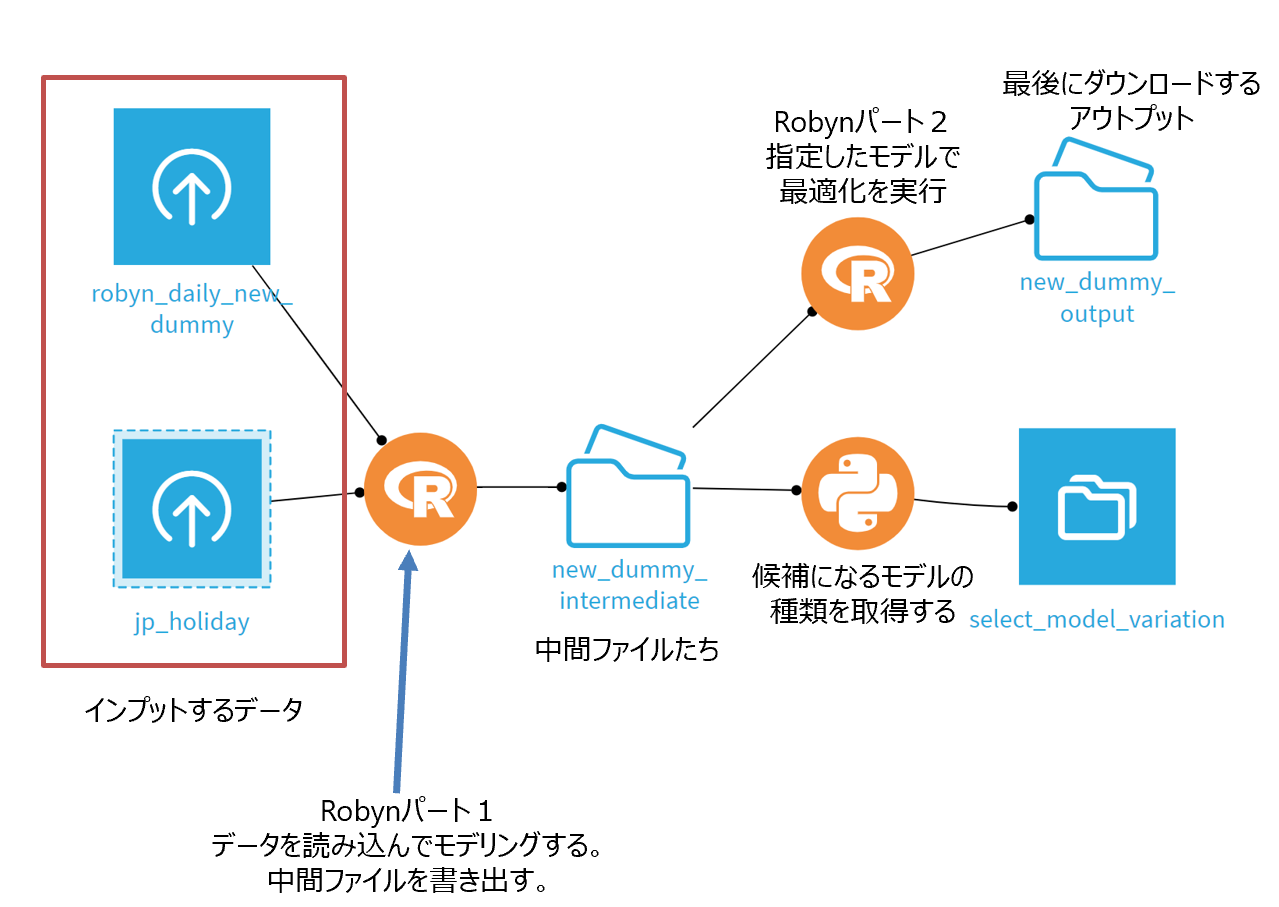
今回のプロジェクトのフローはこんな感じになっています。
ユーザー(ノンコーダー)にはフローをいじらずにアプリケーションUIだけを触ってもらいます。
↑
プルダウンやクリックだけ!コーディングは無し!
モデリングの後に良さそうな結果を選択して、そのモデルを用いて最適化します。
↑
ダッシュボードイメージです。画像は動的に置き換わります。
使用したデータはパッケージ内のダミーデータです。
使用したいモデル番号を指定して、最適化を実行します(同じUI画面から)。

↑
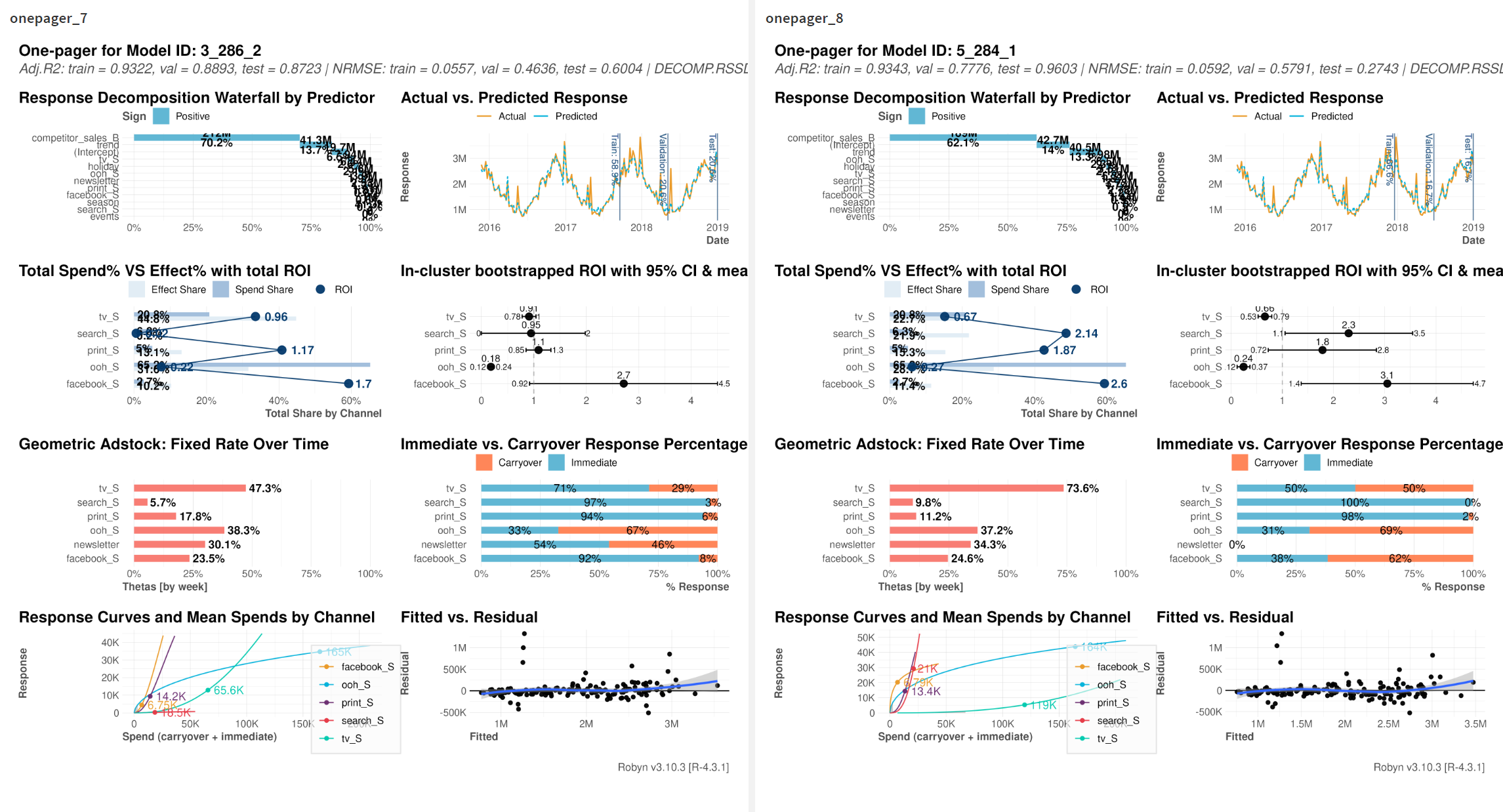
最適化結果のペライチ画像とcsvがUIからダウンロードできます!
他のモデルでも最適化したい場合はモデル番号の指定を変更→最適化実行→ダウンロードを繰り返すこともできます。
※DSSのバージョンは12.0.0です。
※バージョンによっては再現できない可能性があります。
Robynを使う環境構築
まずDataiku DSS でRobynを使えるようにcode envを作成します。
RobynはRのパッケージなので、R環境(condaなし)を作成し、必要なパッケージを追加します。
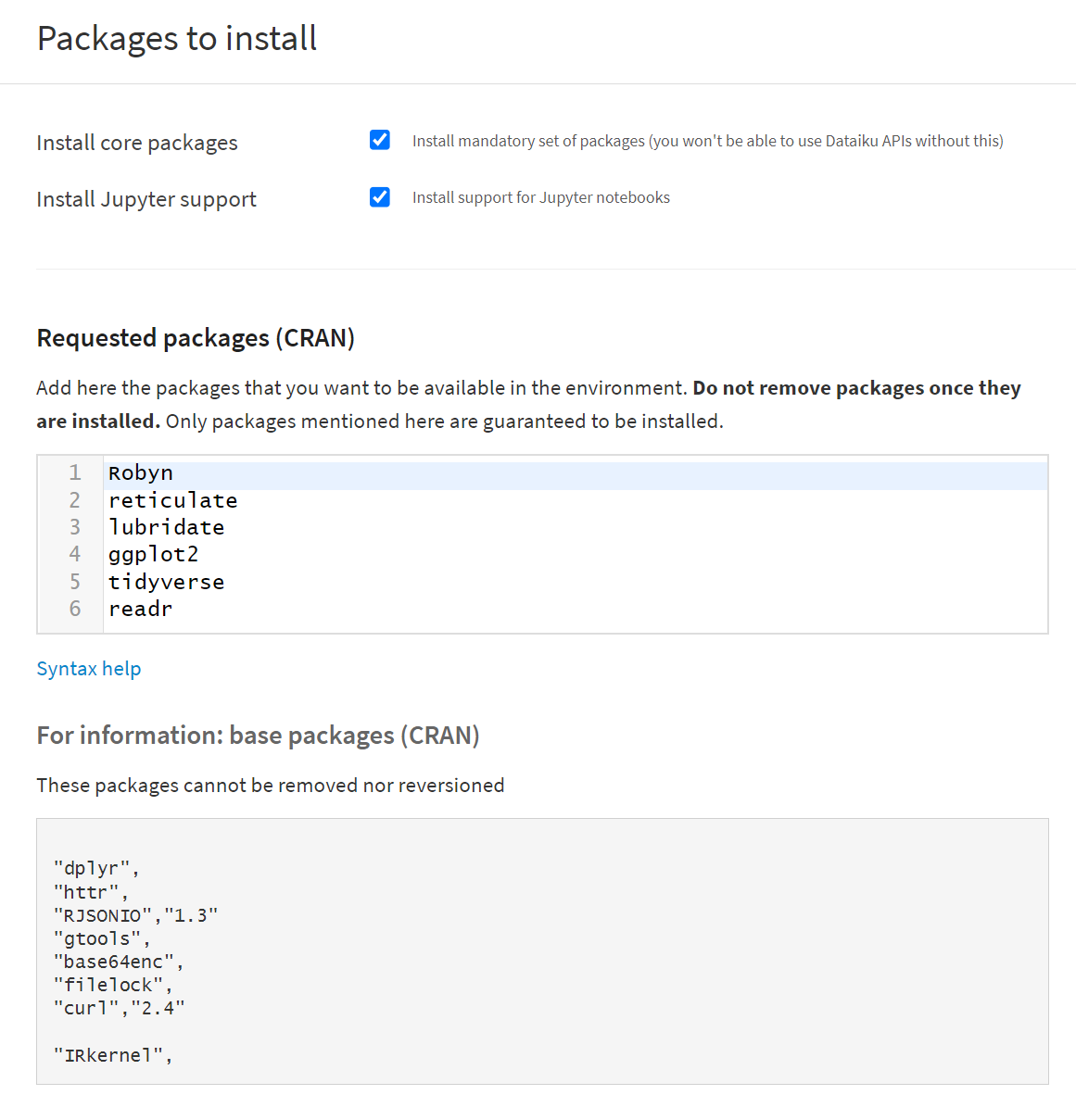
- Robyn
- reticulate
- lubridate
- ggplot2
- tidyverse
- readr
RobynはR Studioなどローカルで実行する際にはPythonの仮想環境を使用します。
ローカルでRobynを使っていた時、私はcondaを使用していたのでRでcondaあり環境を作ろうとしたのですが
conda無しのR環境が正解みたいです。
Python環境が無いとRobynは動かないので、Python環境(こちらもconda無し)も作成します。
私はPython 3.8にしました。
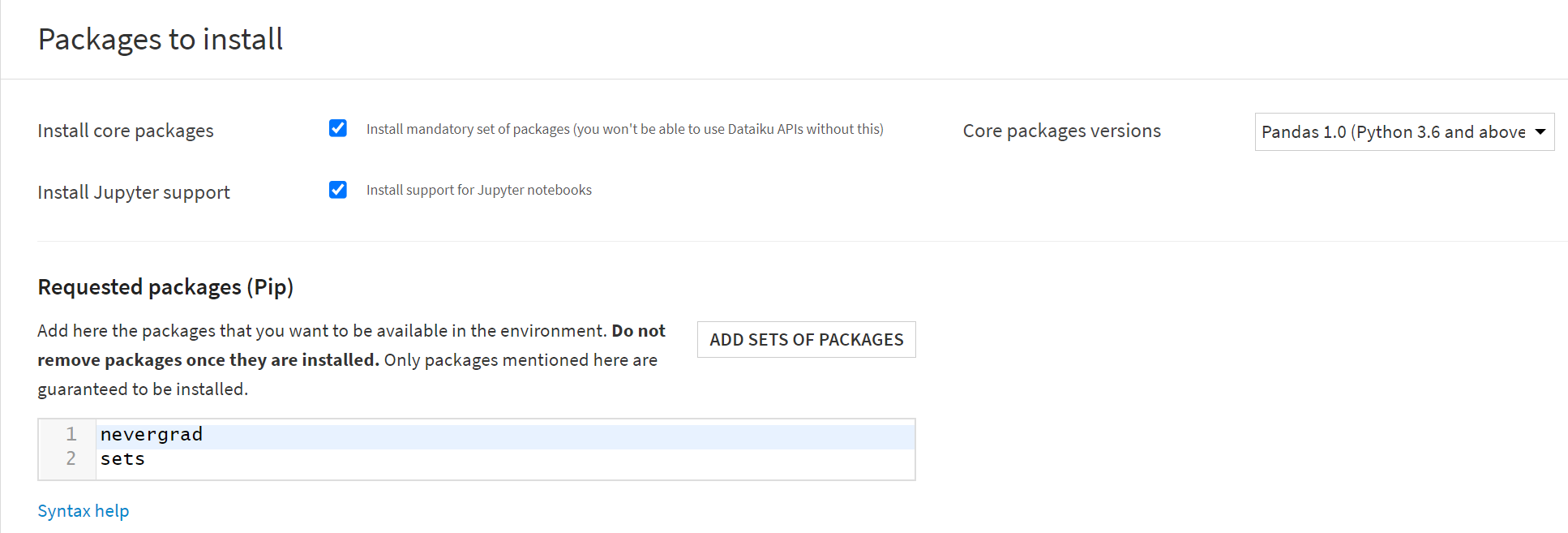
- nevergrad
- sets
今回のプロジェクトではクラスターは使用していません。
Robynが動くかのテスト
まずRobynがDSS上で動かせるか確認します。
ダミーデータは用意しなくてもパッケージで用意されているので、デモコードを実行してみます。
プロジェクトに適当な名前を付けて作成します。
Rコードのレシピを作成します。
インプットは無し、アウトプットはManaged Folderを新しく作成します。
EDIT IN NOTEBOOK をクリックし、ノートブック上で実行していきます。
※library(dataiku)はデモコードに入っていませんが、必要です。
確認していただきたいのはlibrary(Robyn)が通るか、です。
通らなかった場合はKernelが設定されているか、code envにパッケージを追加したときにエラーが起こっていないか、
などを確認してみてください。
通った後はPythonを使うために
use_python('/data/dataiku/dss_data/code-envs/python/robyn_py38/bin/python')を実行します。
robyn_py38をご自身で作成したPython環境の名前に置き換えてください。
これでPythonをR環境からも使うことができます。
(Dataikuの方から教えていただいた方法なのですが、該当するドキュメントは見つけられず…)
デモコードを順に実行してみて、ノートブック上で結果のアウトプットが出ることを確認しましょう。
(Managed FolderにアウトプットはしなくてもOK)
Robynの使い方はこちらのブログなどを参考にしました。
フローを作成する
環境が整ったらフローを作成します。
フローができてからApplication designerでUIを作成し、シナリオを組んで自動化の流れを作ります。
project variableなどは後から一気に変更するので、
まずはダミーのインプットデータを使って最後まで実行できるフローを目指します。
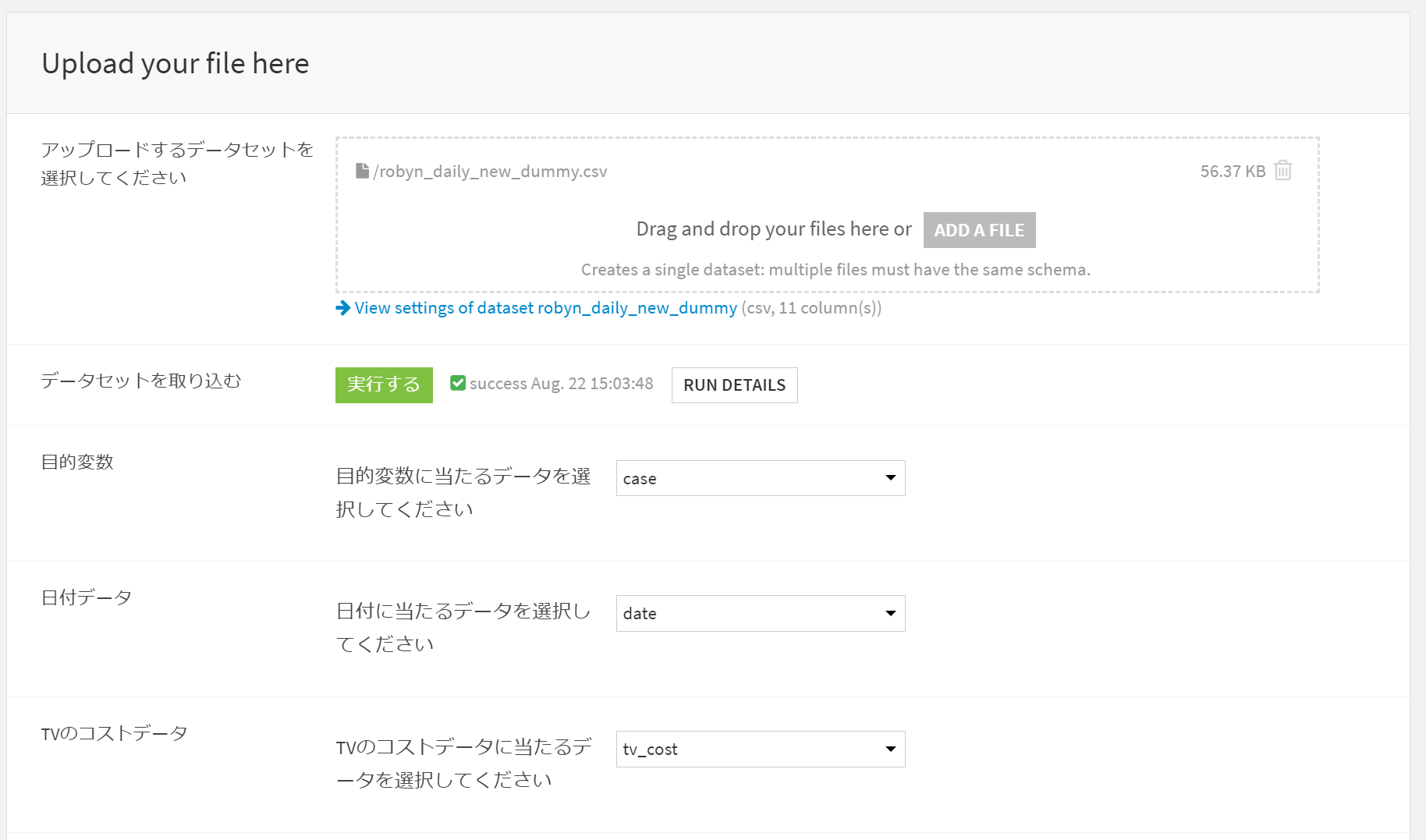
ユーザーにデータセットをアップロードさせてそのデータを使用する予定の場合、
置き換える前提のデータセットをフロー上に置く必要があります。
また、Prophetの祝日データには日本(JP)が含まれていないので私は自作してアップロードしました。
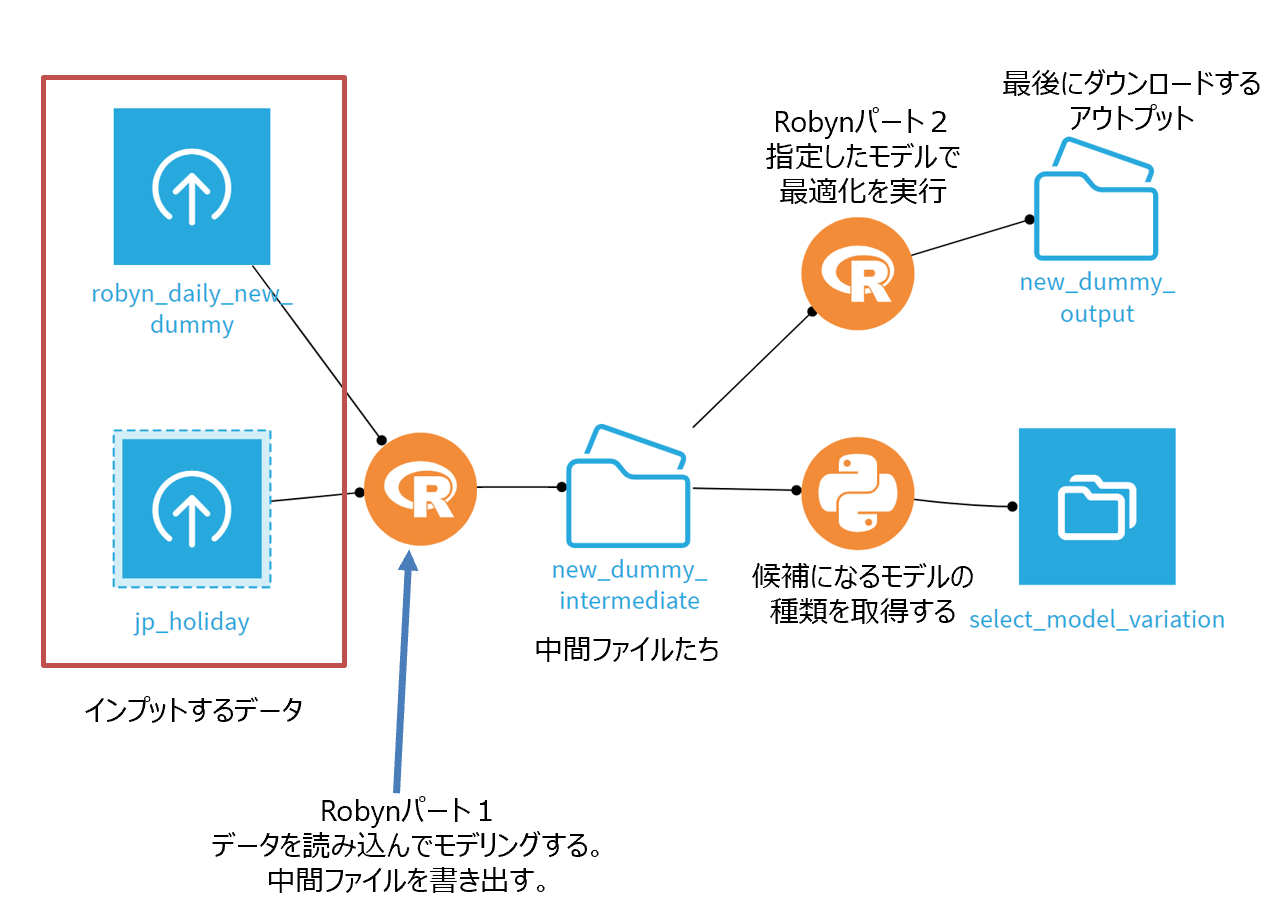
↑
再掲です。赤枠のデータセットの用意が今完了しました。
特に用意が無い場合はRobynパッケージのdt_simulated_weeklyをエクスポートしてアップロードするのでも良いと思います。
用意したデータセットをインプットに設定し、Rのコードレシピを作成します。
アウトプット先は確認用に作成したフォルダを指定します(新しく作り直してもいいのですが、managed folderにします)。
基本的にはデモコードを丸写しでいいのですが、ご自身で用意されたデータセットを使うなどされる場合は
変数名の定義を適宜変更してください。
1つ目のRコードレシピではデモコードのStep3のモデリングまでを実行します。
Dataikuで使用するために変更しないといけない箇所もあるので、以下解説です。
robyn_outputsでファイルの書き出しを指定しています。
R studioなどで実行するときはローカルに書き出されるのを先ほど作成したManaged Folderに書き込みます。
## Calculate Pareto fronts, cluster and export results and plots. See ?robyn_outputs
OutputCollect <- robyn_outputs(
InputCollect, OutputModels,
plot_folder_sub = plot_folder_sub,
pareto_fronts = "auto", # automatically pick how many pareto-fronts to fill min_candidates (100)
# min_candidates = 100, # top pareto models for clustering. Default to 100
# calibration_constraint = 0.1, # range c(0.01, 0.1) & default at 0.1
csv_out = "pareto", # "pareto", "all", or NULL (for none)
clusters = TRUE, # Set to TRUE to cluster similar models by ROAS. See ?robyn_clusters
export = TRUE, # this will create files locally
plot_folder = robyn_directory, # path for plots exports and files creation
plot_pareto = create_files # Set to FALSE to deactivate plotting and saving model one-pagers
)
print(OutputCollect)plot_folder_subとplot_folderを指定しておきます。
FolderPathは作成したフォルダに移動してURLを確認してください。
managedfolder/ABcd12E3/view/ ←ABcd12E3のような、managedfolderとviewの間にある8桁の英数字です。
# Recipe outputs
robyn_output <- dkuManagedFolderPath("********")
# システムの日付を取得(日付型:DATE)
systime <- format(Sys.time(), format = "%Y%m%d%H")
# サブフォルダを作成する準備
plot_folder_sub <- systime
# アウトプット先の設定
robyn_directory <- robyn_outputモデル番号を指定して最適化を実行するために中間ファイルの出力が必要です。
R studioでは一連の流れで最適化をしてしまうので不要だった部分です。
input_collectとoutput_collectをRDSファイルとして書き込みます。
input_collect_export <- InputCollect
saveRDS(input_collect_export, file = paste0(robyn_directory, "/", plot_folder_sub, "/input_collect_export.rds"))
output_collect_export <- OutputCollect
saveRDS(output_collect_export, file = paste0(robyn_directory, "/", plot_folder_sub, "/output_collect_export.rds"))1つ目のRレシピの変更点は以上です。
ノートブック上で実行し、問題が無ければ[Save back to recipe]をクリックし、ジョブとして実行してみます。
上手く行けばフォルダにサブフォルダが作成されています!↓
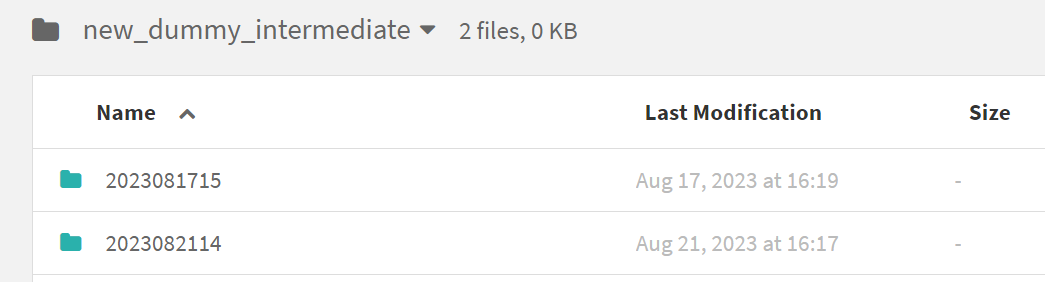
2つ目のRコードレシピを作成します。
ここではモデル番号を指定して最適化(デモコードのStep4と5)部分を実行します。
またアウトプットはフォルダになるので、新規で作成します。
インプットは先ほど1つ目のRレシピで書き出した先のフォルダを指定します。
input_collectとoutput_collectはRDSファイルで、Dataikuではバイナリファイルをサポートしていないので
そのままでは読み込めません。
フォルダに保存して、フォルダから直に読み込むことで回避します。
(フォルダの中のファイルをデータセットを作成することができるのですが、バイナリファイルの場合は扱えなくなります)
folder_id <- "********"
info <- dkuManagedFolderInfo(folder_id, sensitiveInfo=FALSE)
folder_path <- info$info$path
sub_folder <- dkuManagedFolderPathDetails(folder_id ,"/")$children[length(dkuManagedFolderPathDetails(folder_id ,"/")$children)][[1]]$fullPath
output_collect_path <- paste0(folder_path, sub_folder, "/output_collect_export.rds")
input_collect_path <- paste0(folder_path, sub_folder, "/input_collect_export.rds")
input_collect <- readRDS(input_collect_path)
output_collect <- readRDS(output_collect_path)サブフォルダが複数ある場合にも対応できるようにDataikuのR APIを使用していますが、
最初のフローを作る段階であればパスをベタ打ちでも問題ありません。
select_model <- "1_123_1" # 中間ファイルのpareto_aggregated.csvでtop_sol=TRUEのsolIDを指定する
output_collect$plot_folder <- paste0(robyn_directory, "/", systime, "/")output_collect$plot_folder
# Example 2: maximize response for latest 10 periods with given spend
AllocatorCollect <- robyn_allocator(
InputCollect = input_collect,
OutputCollect = output_collect,
select_model = select_model,
date_range = "last_10", # Last 10 periods, same as c("2018-10-22", "2018-12-31")
total_budget = 100000000000, # Total budget for date_range period
simulationchannel_constr_low = c(0.8, 0.7, 0.7, 0.7, 0.7),
channel_constr_up = c(1.2, 1.5, 1.5, 1.5, 1.5),
channel_constr_multiplier = 5, # Customise bound extension for wider insights
scenario = "max_response",
export = TRUE)
print(AllocatorCollect)1つ目のRコードレシピ同様にノートブックで実行し、問題なく動けば[Save back to recipe]をクリックして
ジョブとして実行してみます。
今回は動くかどうかの確認優先なので変数の値が妥当なのか、などの確認はしていません。ご了承ください。
長くなってしまったので中編に続きます!(前編・後編だけに収まらなかった…)
中編ではApplication designerとシナリオを使ってどうユーザー用の仕組みを作るか、の説明をしたいと思います!




