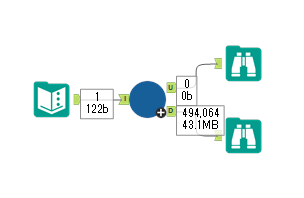
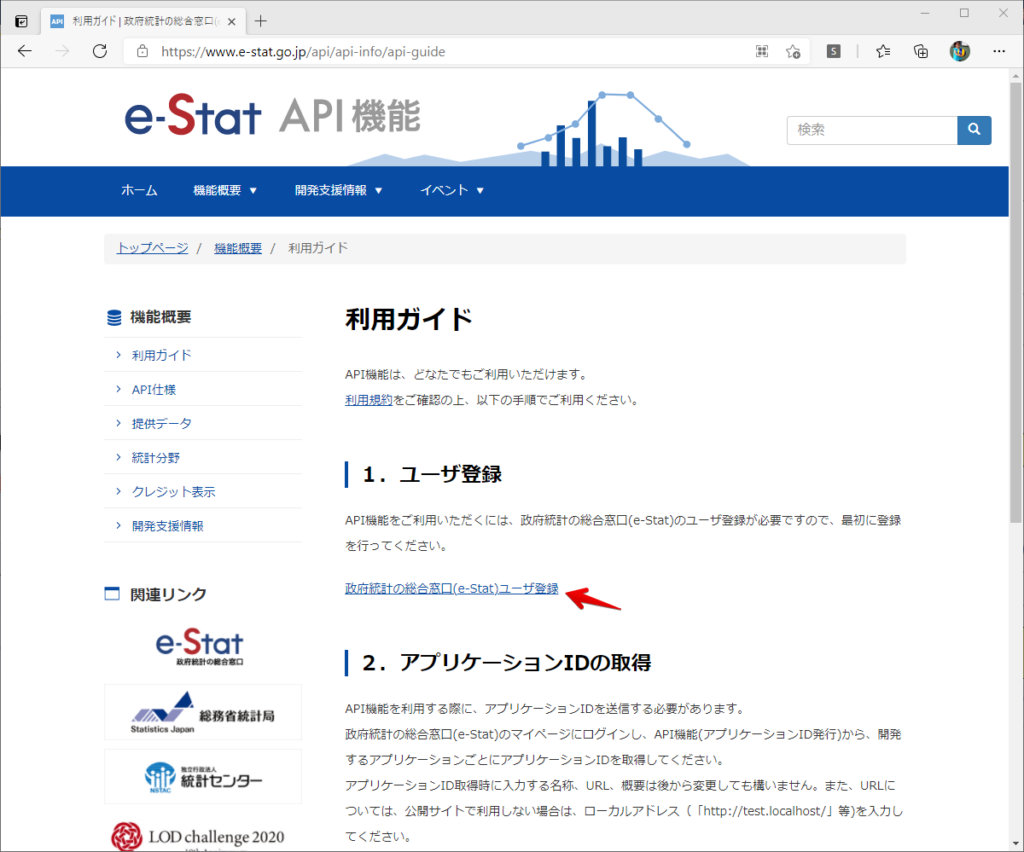
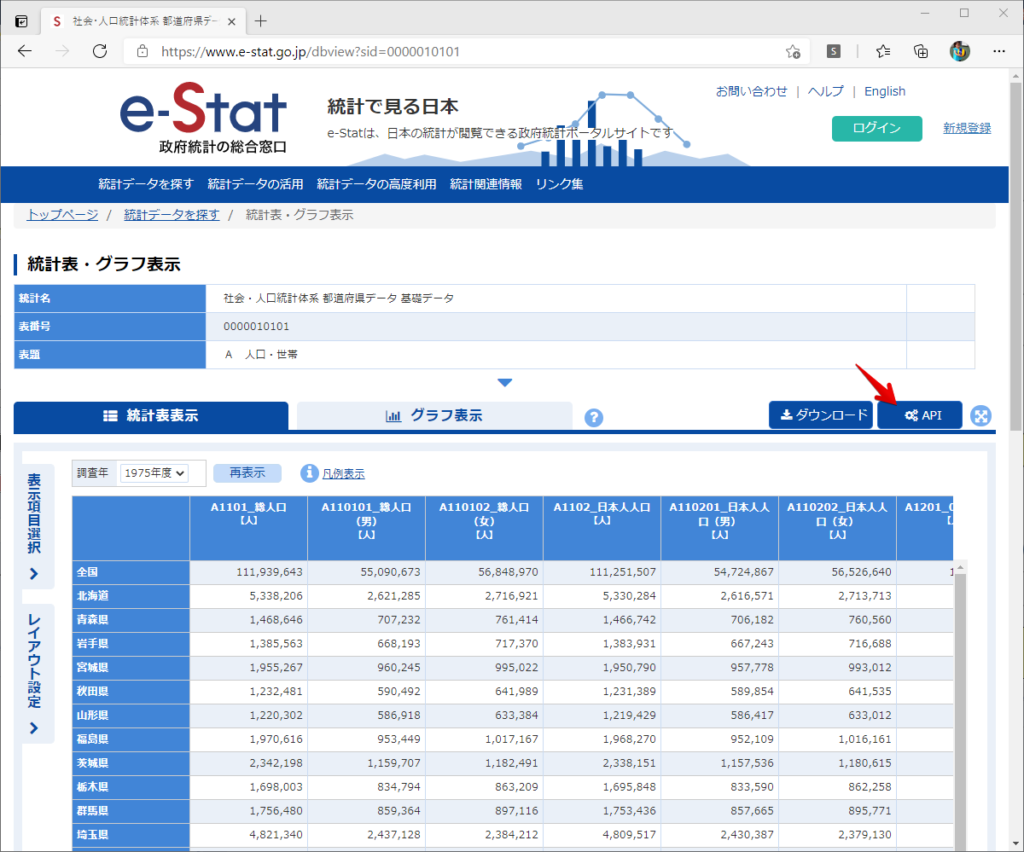
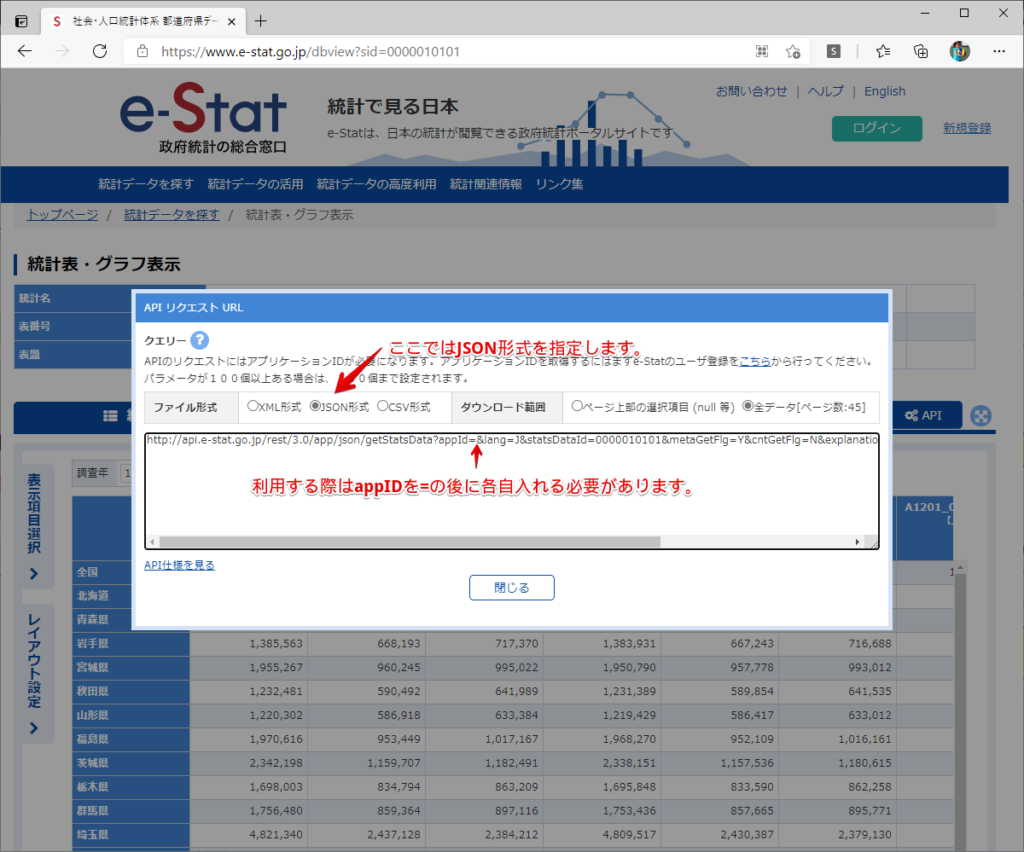
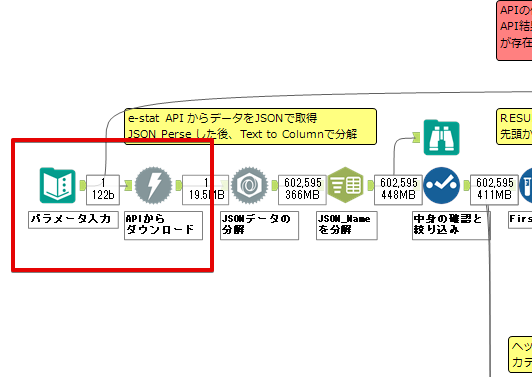
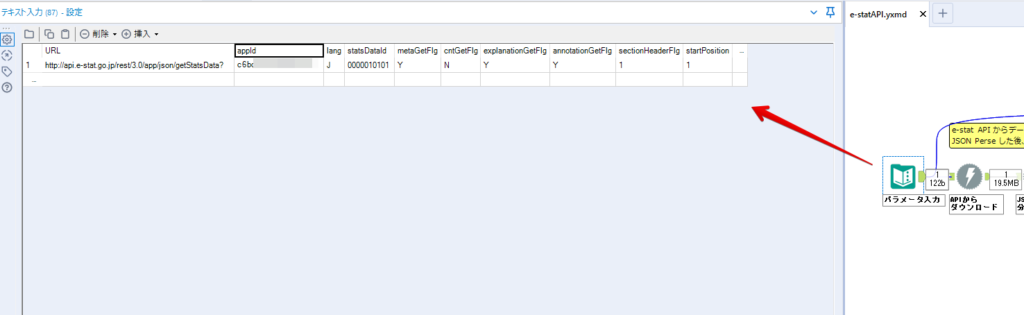
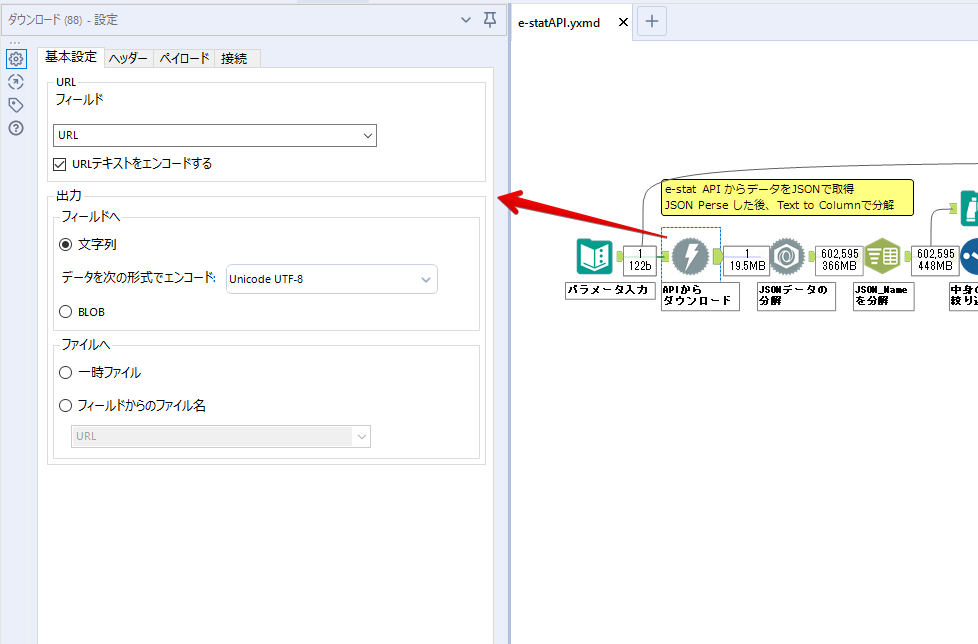
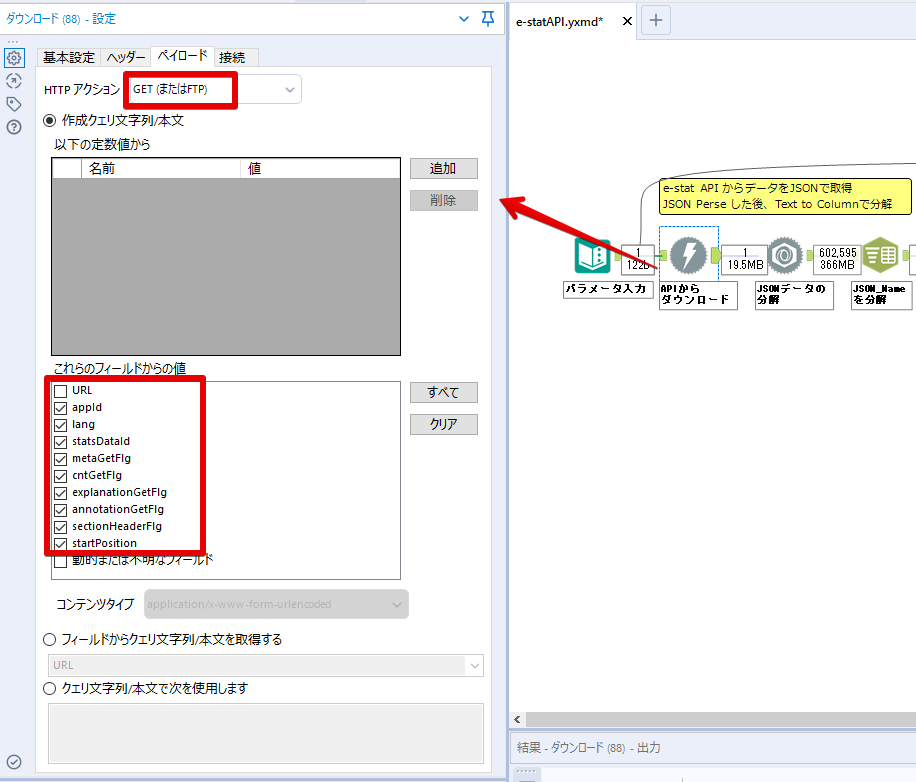
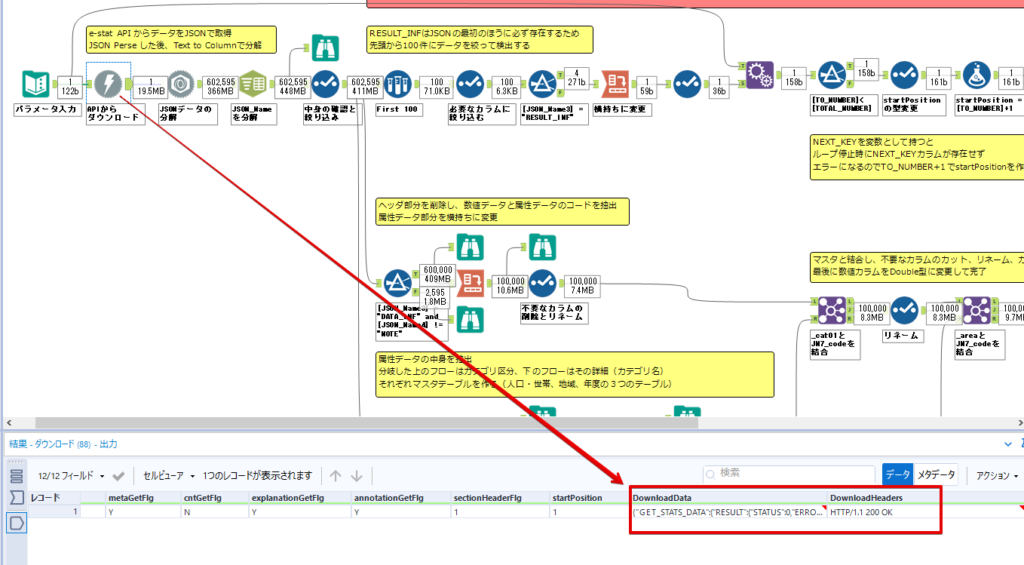
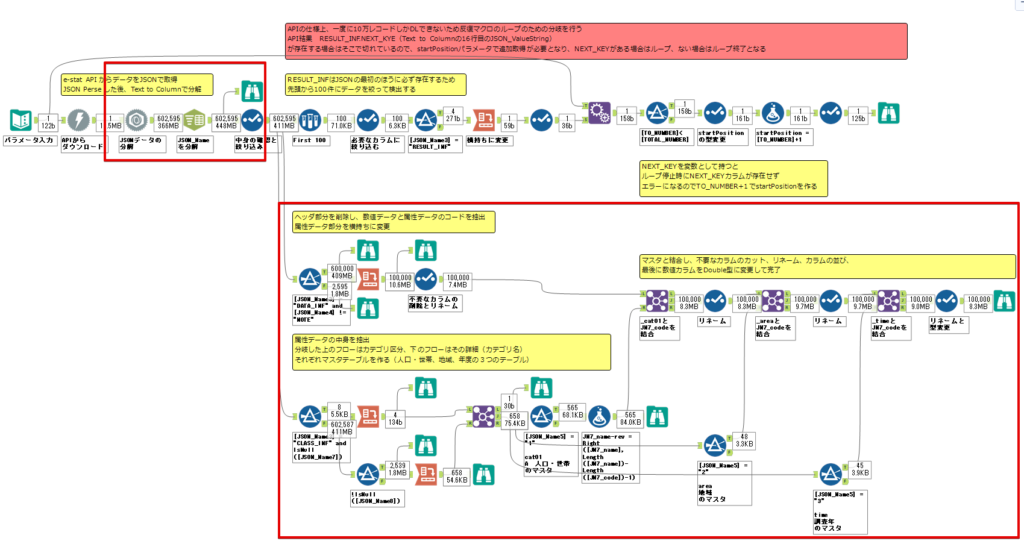
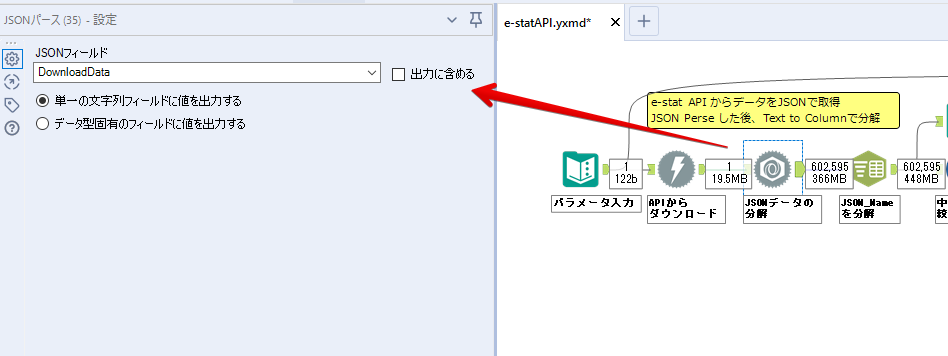
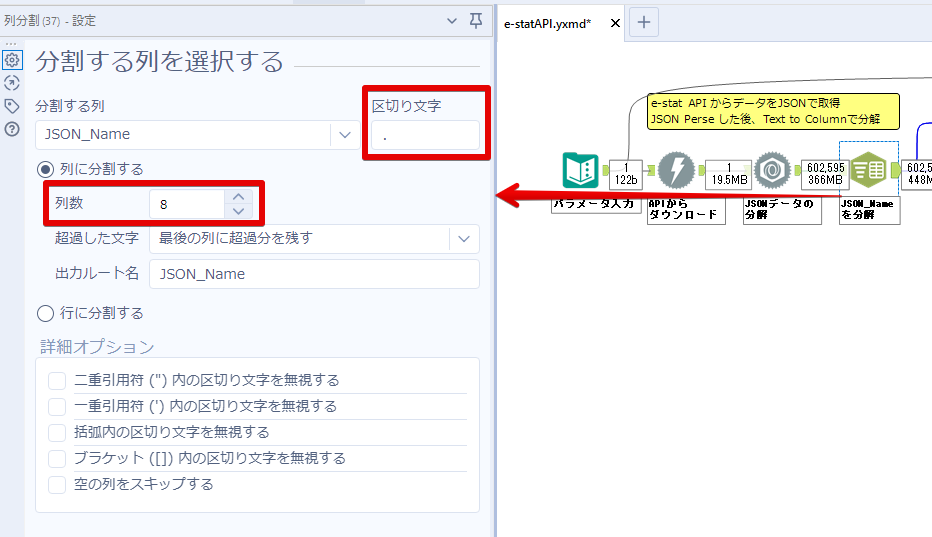
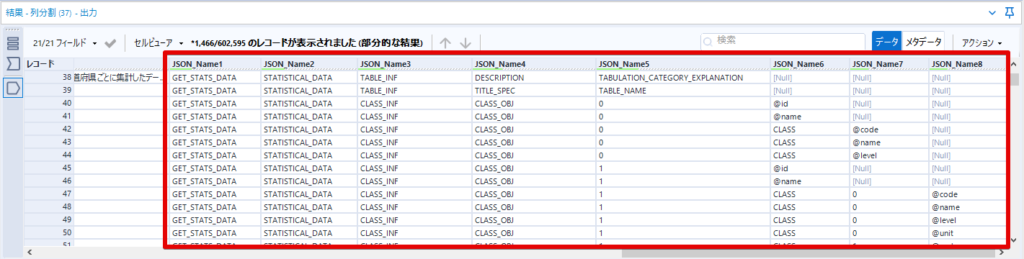
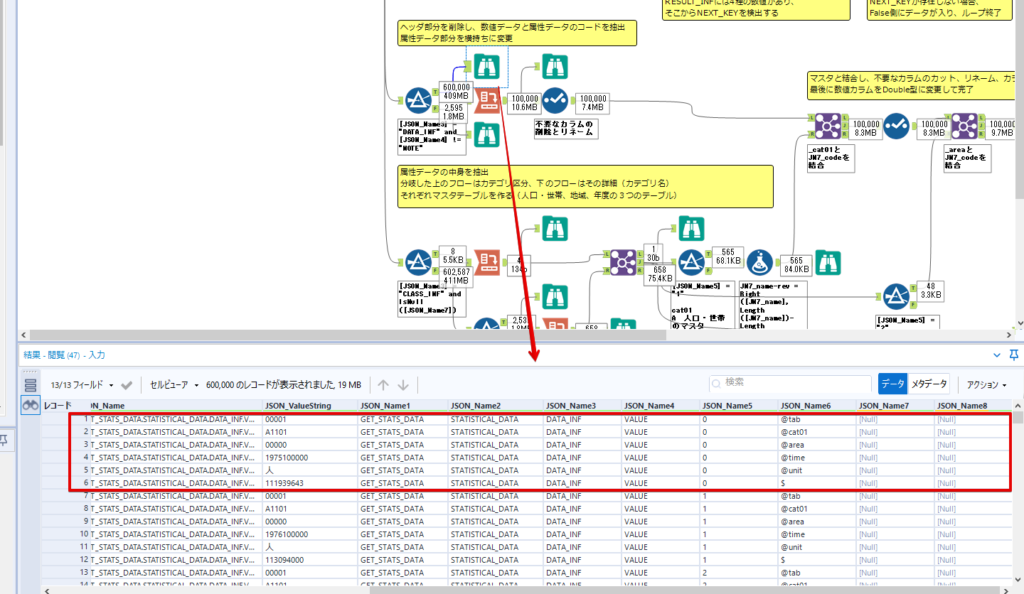
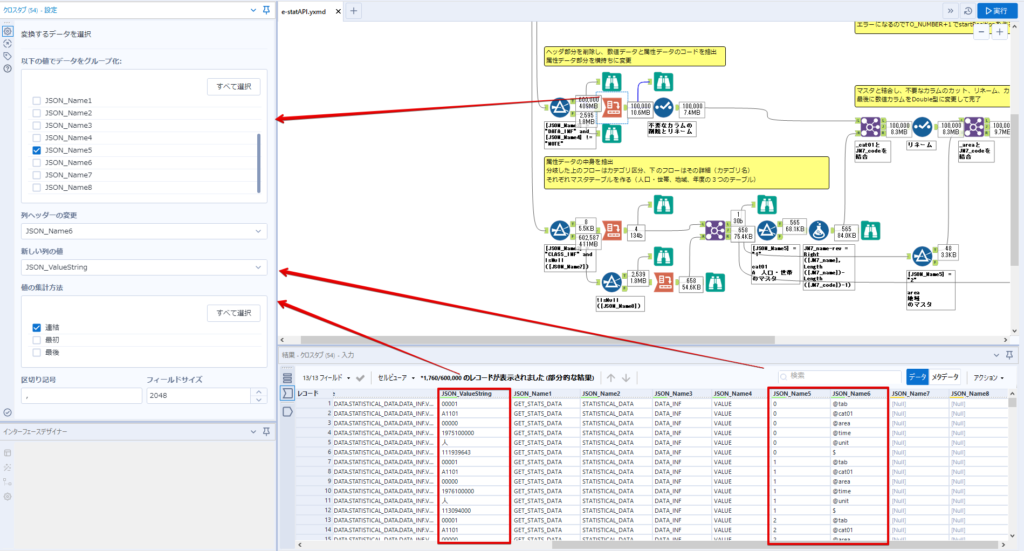
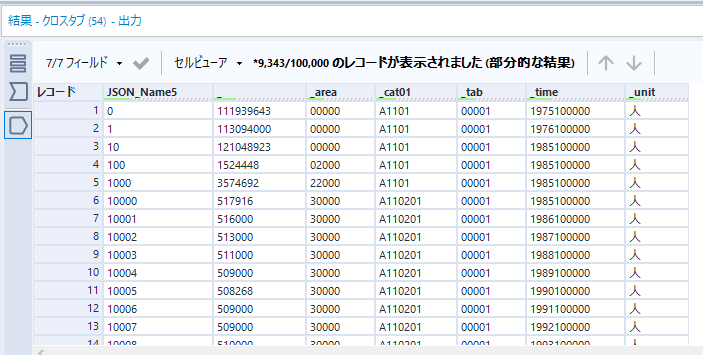
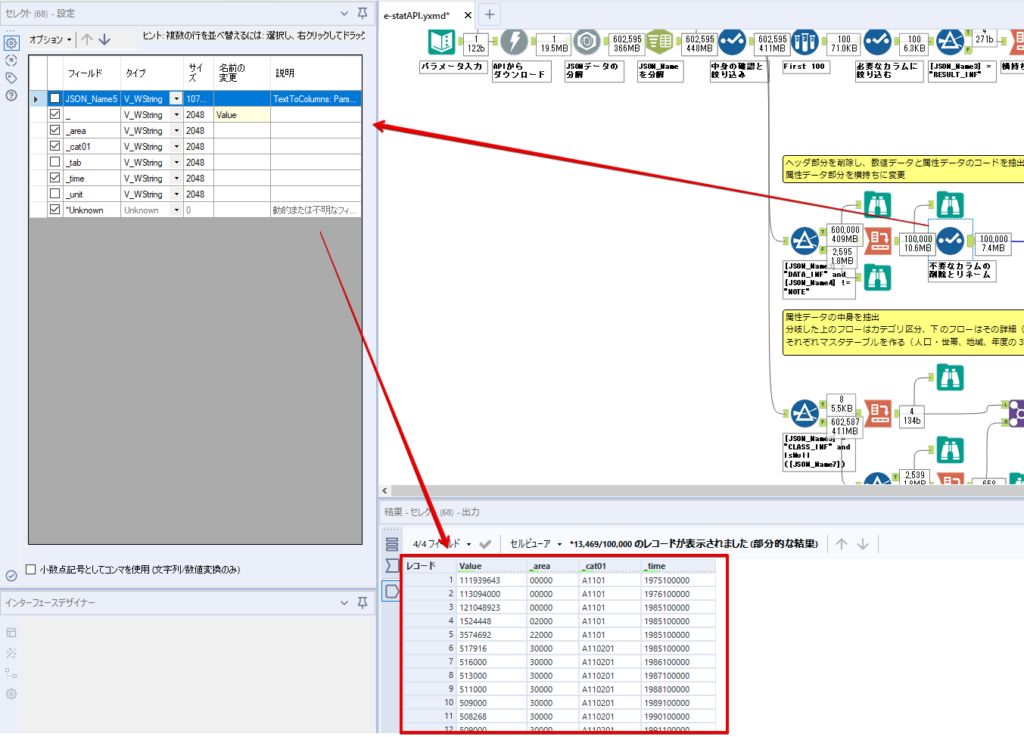
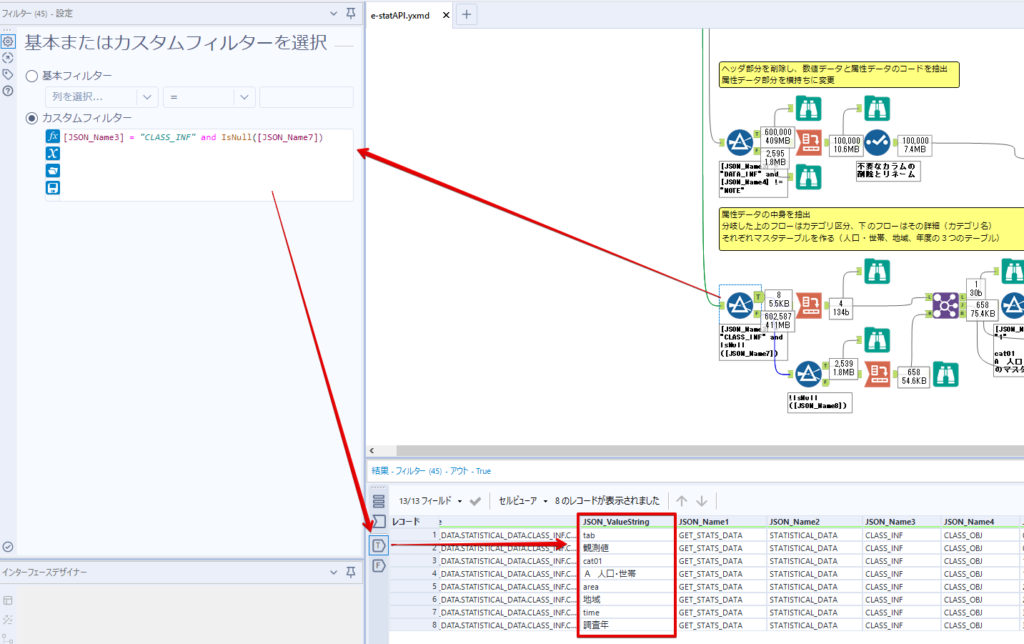
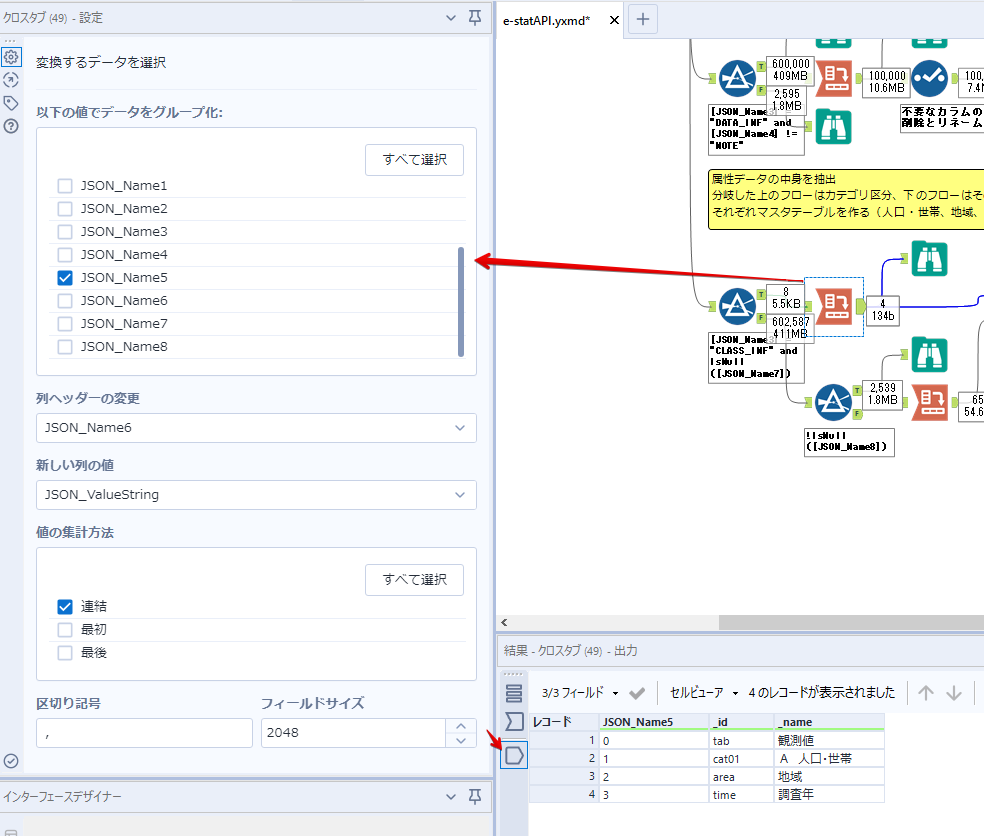
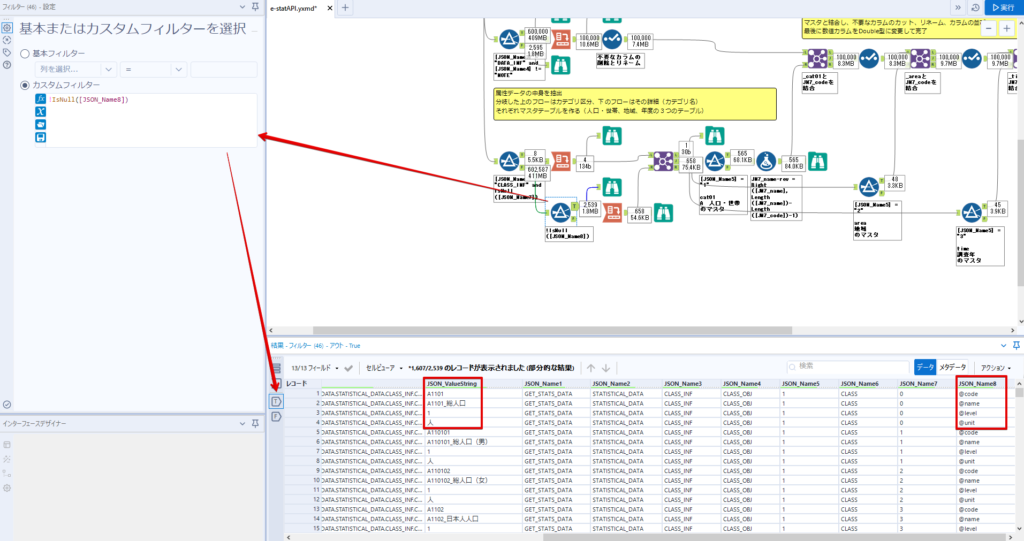
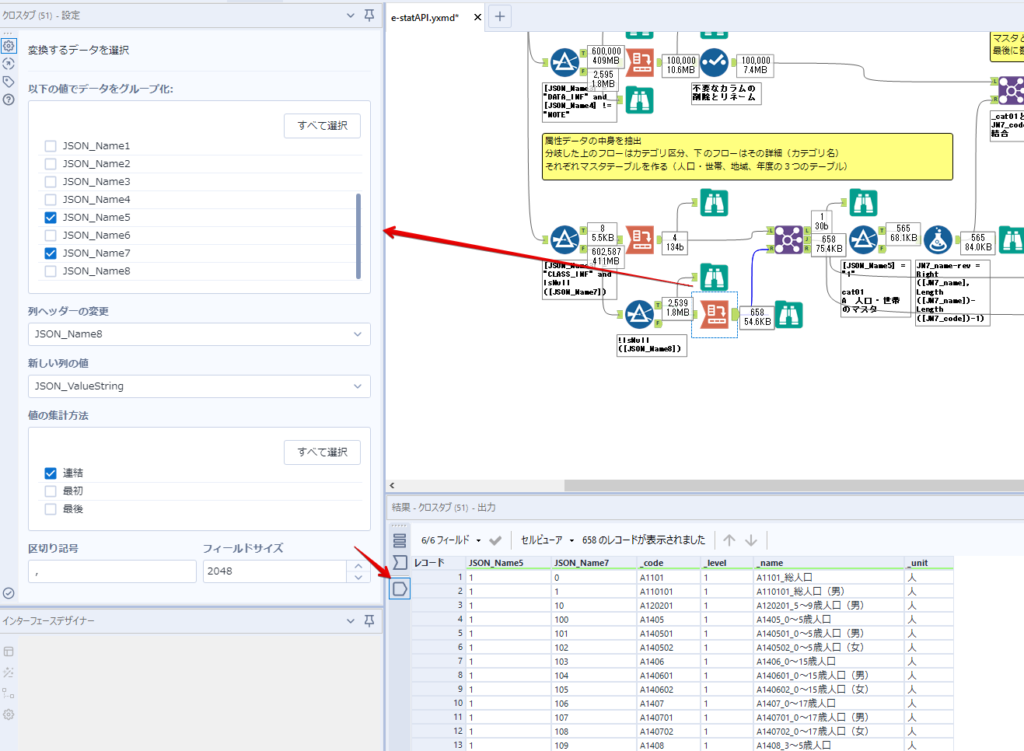
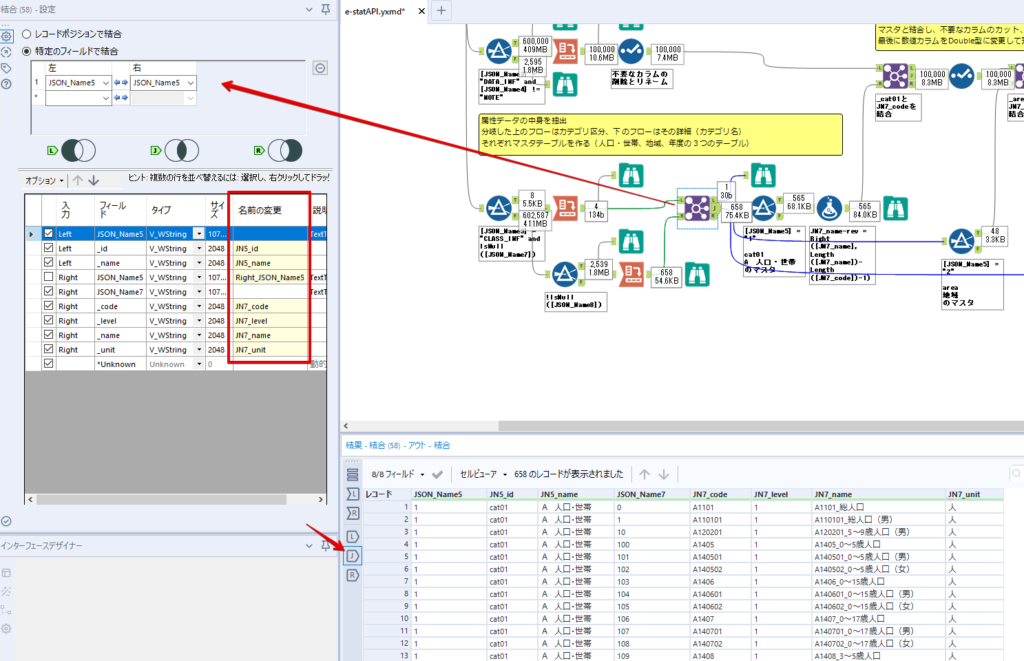
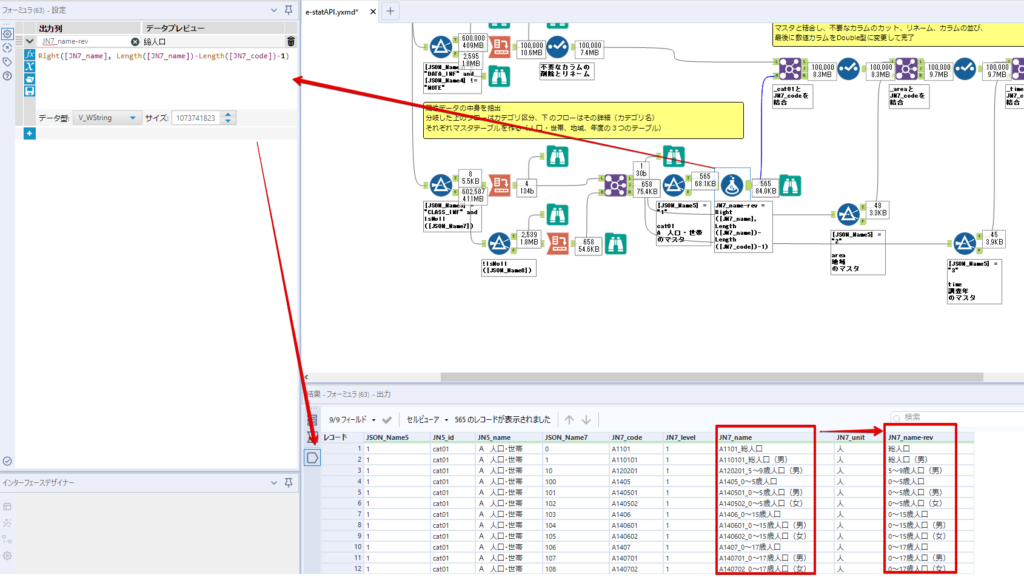
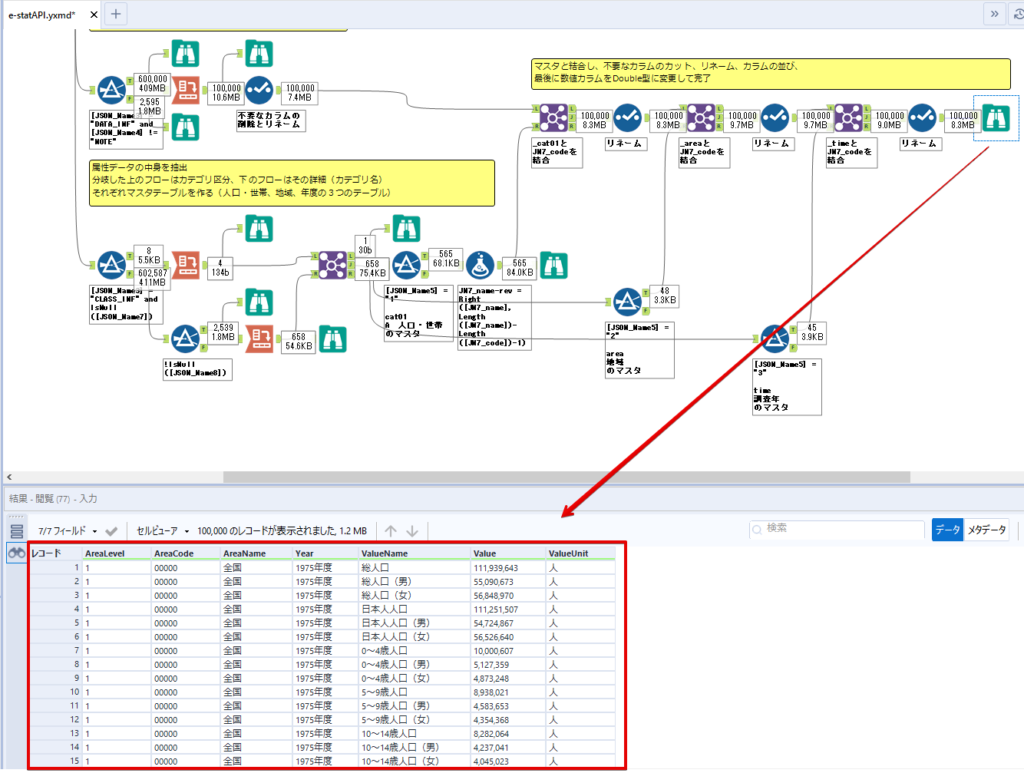
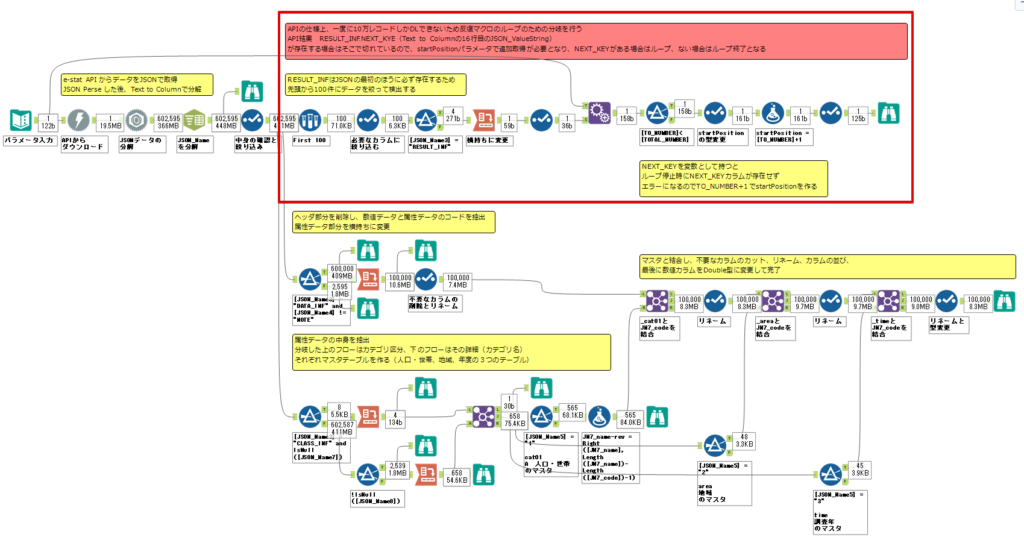
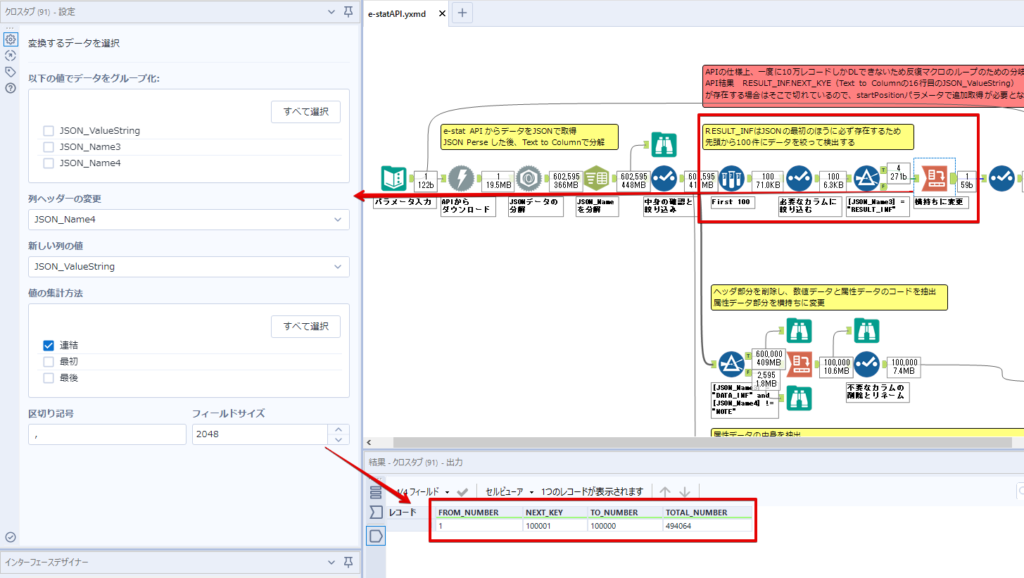
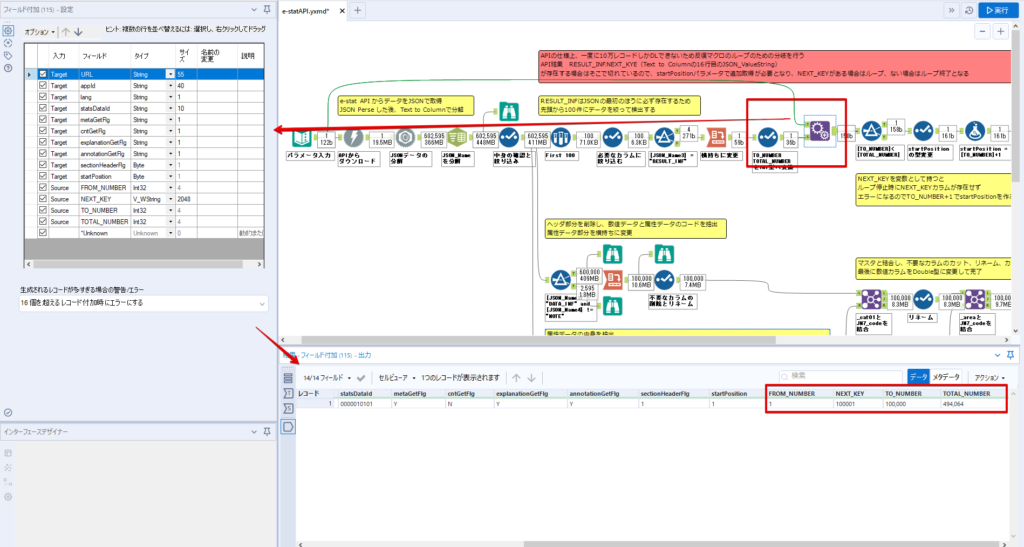
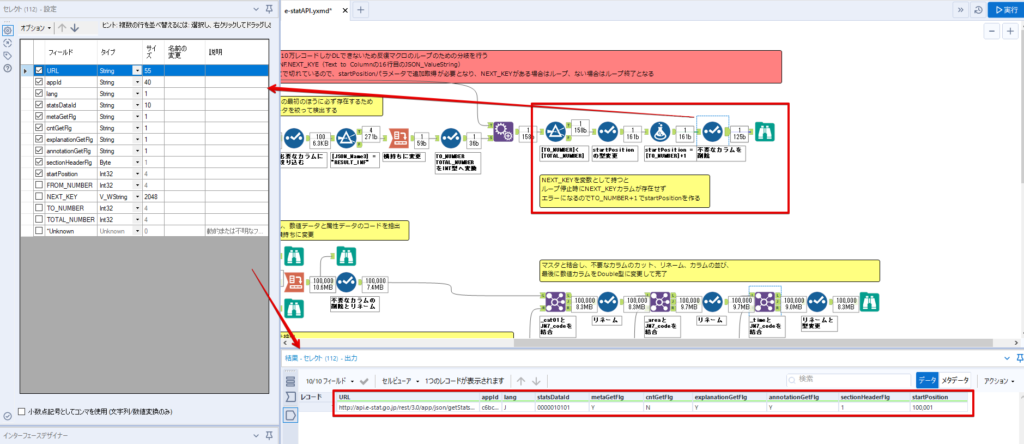
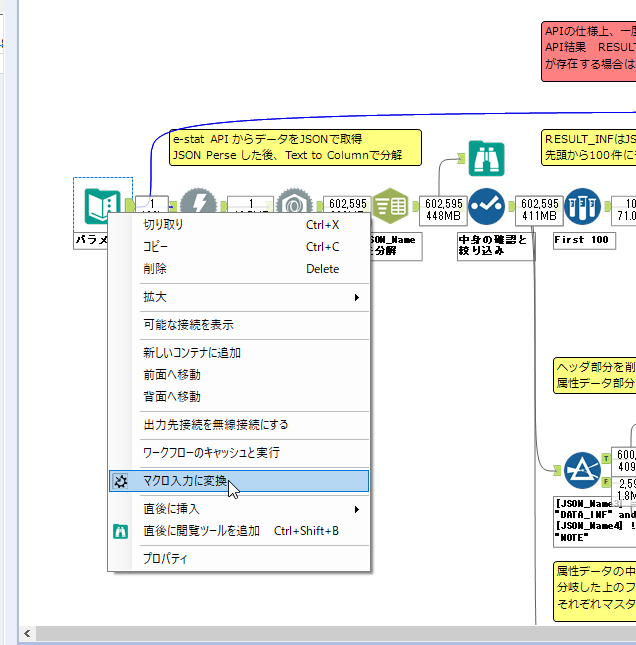
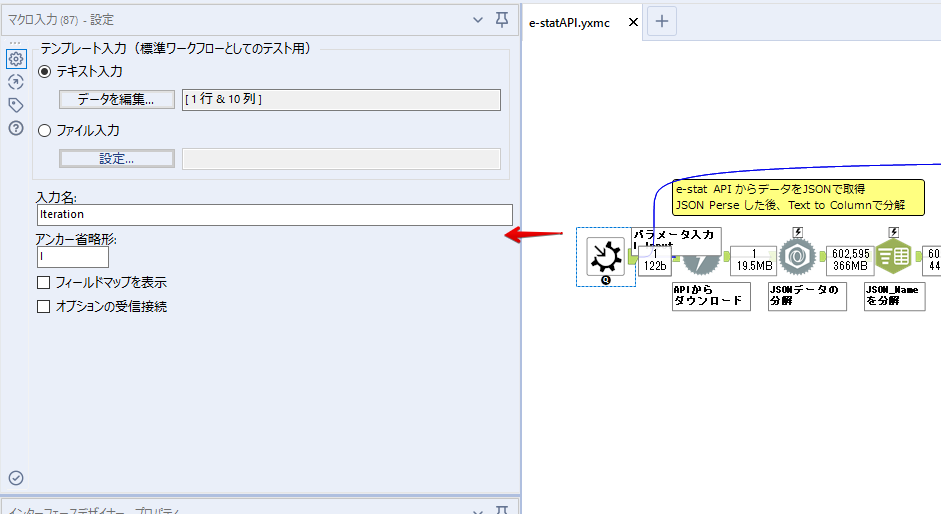
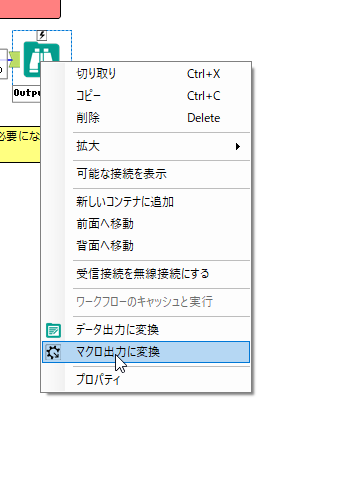
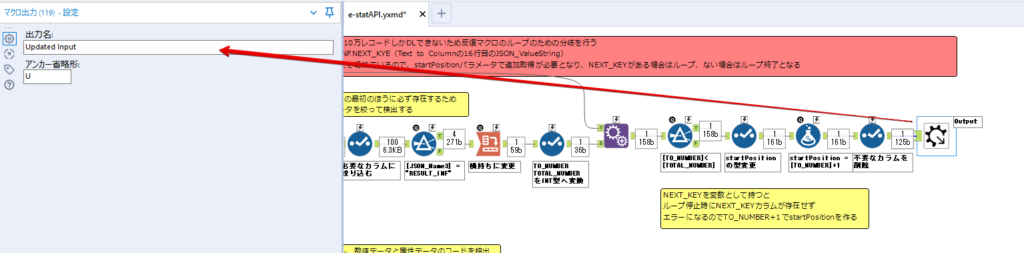
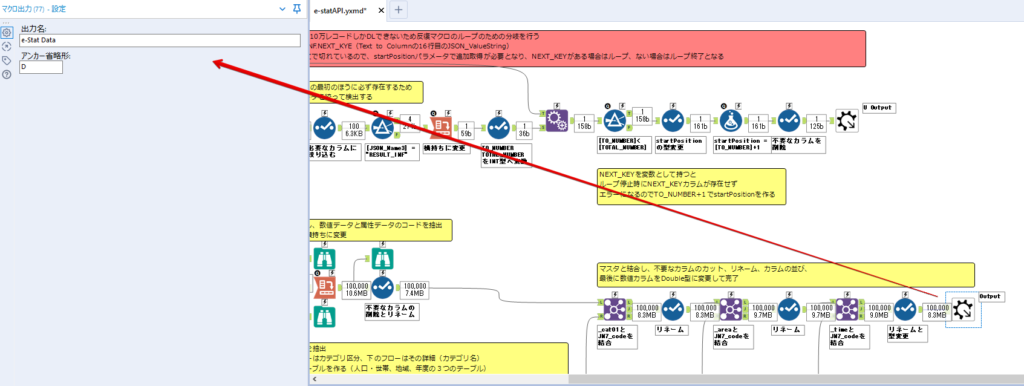
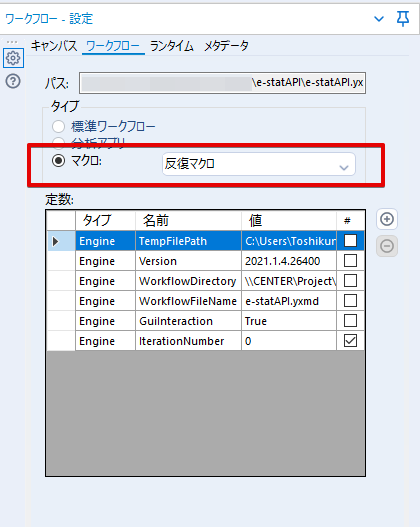
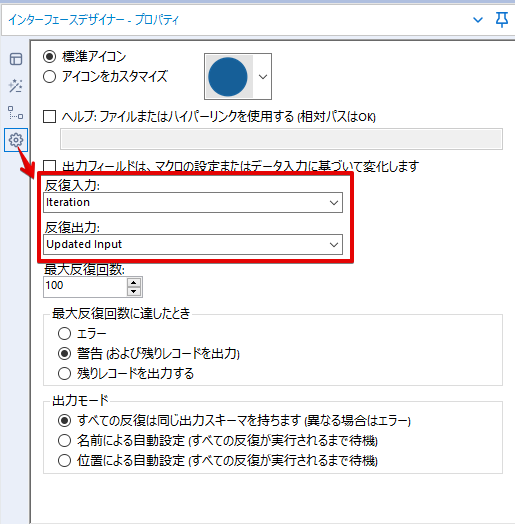
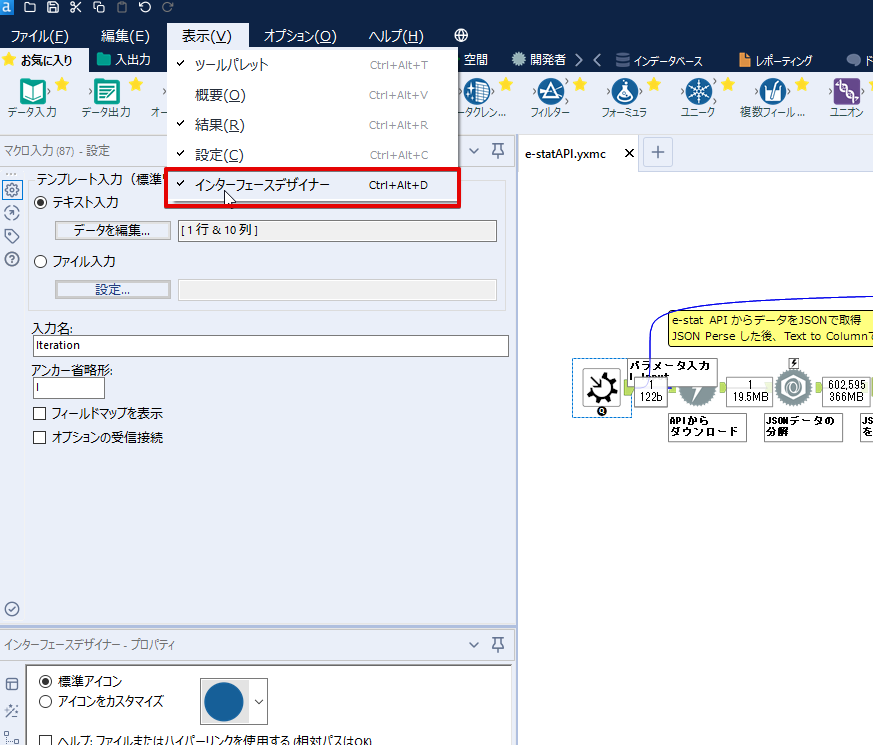
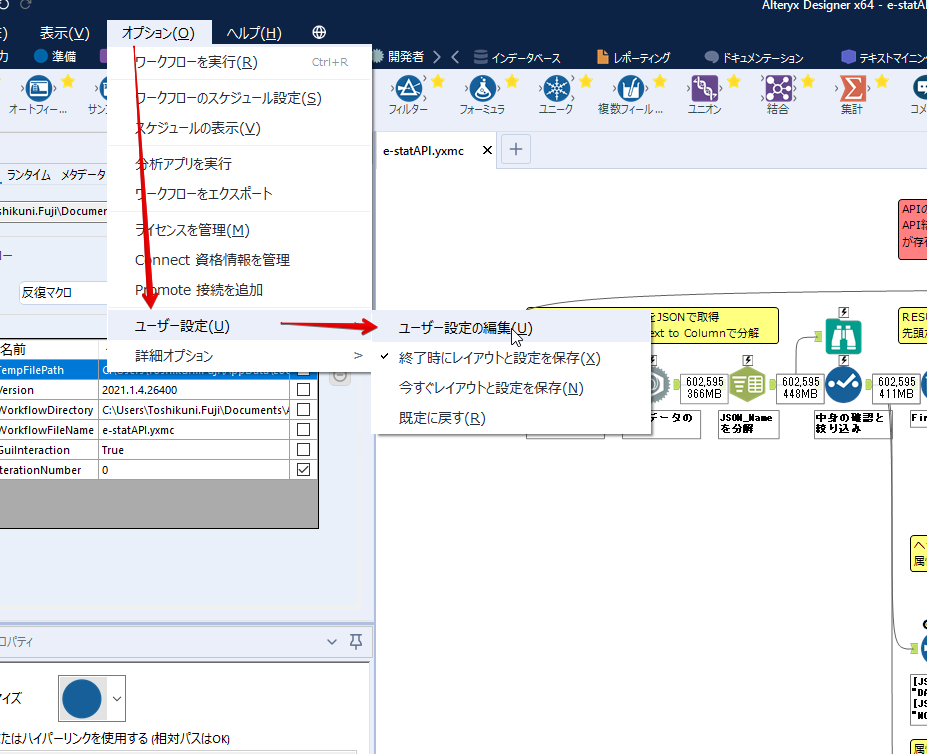
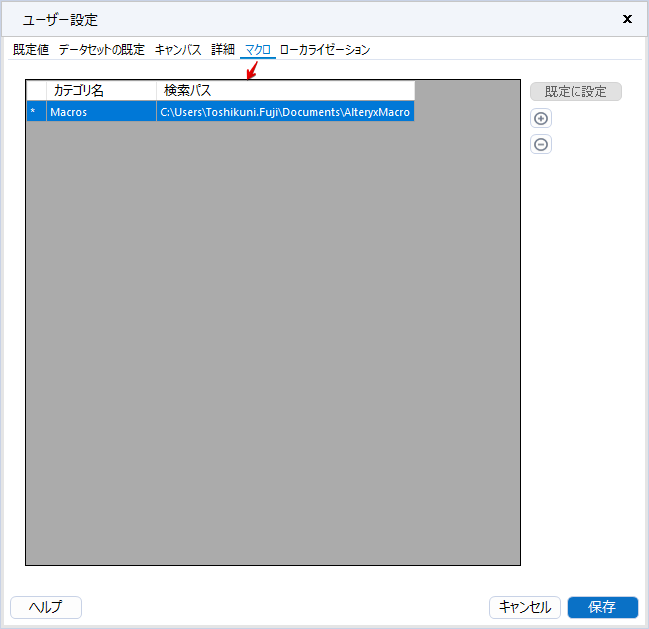
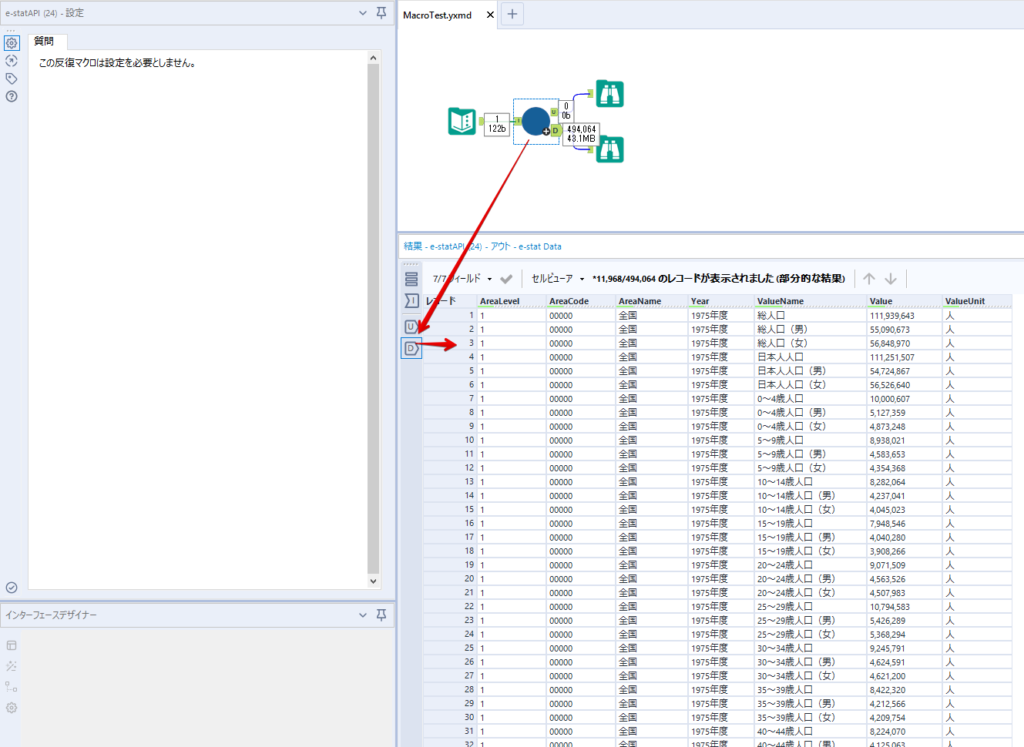
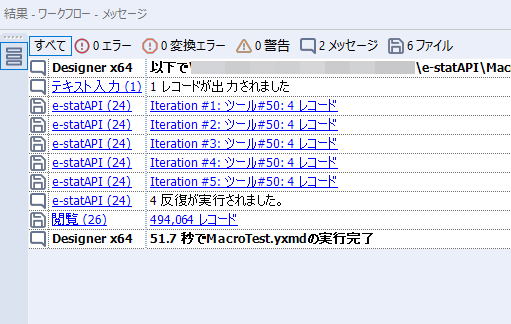
By t.fuji Alteryx 2021/05/19 目次 1.事前準備 2.データ抽出 3.データ加工 4.ループ処理 おわりに 関連する記事 こんにちは。Alteryxリハビリ中の藤です。 今回は政府統計のポータルサイトであるe-statからAPI経由でデータを抽出して加工してみたいと思います。 大まかな流れとしては 事前準備・・・APIキーと必要なデータのコードを取得する データ抽出・・・API経由でデータをダウンロードする データ加工・・・JSONデータの分解から、必要な形への整形を行う ループ処理・・・APIにデータ数の制限があるため、処理をループさせる(反復マクロ化する) となります。 最も参考になったのは例によってDevelopersIOさんのブログです。 DevelopersIO・e-StatのAPI機能を利用して、2015年の国勢調査結果から年齢別の人口を探索する ほとんど書いてあります。 ただ、取得しようとしていたのが別の人口データだったこともあり、データ制限に引っかかってループ処理化が必要になるなど、つまづいた点がいくつかありましたので、その辺りを中心に説明していきます。 このブログの中で、APIからのデータ取得と反復マクロの作成について学ぶことができますが、最初に伝えておくと、全体としてヘビーなので気持ちと時間に余裕がある時に試すことをオススメします・・・ 1.事前準備 まず、e-statのAPIを使うには無料のユーザー登録を行い、アプリケーションIDを取得する必要があります。 こちらのサイトから簡単にユーザー登録ができます。 e-statには様々なデータが公開されています。 アプリケーションIDは『誰が』取得しているのかを管理するものですが、『何を』取得するのかを指定するキーが必要になります。 このページで公開されているデータはAPIで取得できます。 今回はAPIで公開されている『社会・人口統計体系 都道府県データ 基礎データ』を使います。 データの中身はこちらのサイト上でも以下のように可視化できます。右側にあるAPIボタンをクリックすると、データのダウンロードに必要なURLが取得できます。 JSON形式でデータを取得します。 以下のようにパラメータが入ったURLが取得できますが、appIDは各自追加しないと使えません。 これで事前準備は完了です。 2.データ抽出 API経由でデータをダウンロードします。 下のアイコン2つだけです。 それぞれ見ていきます。 まず【テキスト入力】です。 事前準備で取得したURLを『&』で区切られている単位で分解してカラムに入れています。 ここのパラメータを変更することで取得情報を調整することができます。(ここではe-statから取得したままです。) appIDには事前準備で取得したアプリケーションIDを入れます。 次に【ダウンロード】ツールです。 まず、基本設定でURLとエンコードをUTF-8で指定します。 次に設定の『ペイロード』タブに移動します。 HTTPアクションは『GET(またはFTP)』に、『作成クエリ文字列/本文』ではURL以外のフィールドを選択します。これにより、【テキスト入力】で保持したパラメータもURLと一緒に送られることになります。 JSONのアウトプットは赤枠の二つのカラムです。実際に使うのはDownloadDataです。この1セルに取得したデータすべてがテキストで入っています。 これを後続の処理で分解していくことになります。 なお、最後のプロセスでループ処理を行うのですが、startPositionはどこから処理を始めるかのキーとなります。 今回のケースでは10万レコード分のダウンロードで制限がかかるため、例えば二回目のループではstartPosition=100,001となります。APIからは、一回目の処理のアウトプットでNEXT_KEYとして100,001が返ってきます。これは後続の処理であらためて確認します。 作成当初は仕様書を細かく読んでおらず、当たり前のように全件ダウンロードできるものと思い込んでいたため、ループ処理が後で必要になるとは考えていませんでした。 しかし、この後に説明する『3.データ加工』処理後に抽出した結果がピッタリ100,000件だったため、問題に気づいたのですが、このあたりは先述のブログにも無い話なので細かい話は『4.ループ処理』で説明していきます。 ちなみに以下のブログを参考にデータ制限周りの理解を深めました。 Technically, technophobic・e-Stat APIをRから使う Qiita・貿易統計をe-Stat APIを使って入手するメモ いずれにせよ、まずはループ処理は気にせずにデータの加工を行っていきます。 3.データ加工 この二つの赤枠がデータ加工ステップです。 APIの仕様を読み解きながら進める必要があります。データプレップで時間がかかるゾーンです。 APIでデータ共有されているんだから、データは簡単に取り込めるはずと思われがちですが、実際はなかなか一筋縄ではいきません。JSONの場合、大量のデータを素早くダウンロードできますが、その後の処理をデータの仕様に沿って正確に行う必要があります。 このプロセスで迷宮入りして諦めてしまう方は、かなりの数存在しているのではないかと予想しています。 最初はダウンロードしたJSONの分解からです 元のデータは上の赤枠ですが、これを【JSONパース】ツールで分解します。 設定は簡単です。下図のように分解されて縦持ちになります。 属性情報となる『JSON_Name』と値となる『JSON_ValueString』に分かれます。 続いて『JSON_Name』を分解する必要がありますが、ここには以下のようなデータが入っています。 ピリオドで区切られてデータが入る形になっています。ピリオドごとに8本の赤線がありますが、このように8つの列に分解することができます。 JSONには数値以外の情報(エラーメッセージとかパラメーターの設定内容とか)も含まれますが、ここで必要なのは数値情報となりますので、数値情報を持った行の『JSON_Name』から分割する列数を決めます。 ピリオドを区切りに8列に分割します。 属性情報が8つのカラムに分割されました。 続いて、数値データとそれに紐づく属性データを抽出します。 最初は数値データと属性データのコードです。 『JSON_Name3』が”Data_INF”かつ『JSON_Name4』が”NOTE”でないもの が求めるものになります。 求めたい数値データに対する属性データを含めて、6行分が縦持ちされている状況なので、横持ちに変更します。 横持ちへの変更は【クロスタブ】ツールを使います。 『JSON_Name5』がレコードIDに近しいものなので、これをキーにグループ化します。 ヘッダーは『JSON_Name6』、値は『JSON_ValueString』です。 それっぽいテーブルになりましたね。 不要なカラムを削除し、残るカラムをリネームします。 残す属性情報は、_cat01が数値のカテゴリ(性年代とか人口か世帯かとか)、_areaが地域、_timeが年度です。 属性情報の_areaと_cat01はコードが入ったままなので、属性のマスタテーブルを別途作ります。 【フィルター】ツールで『JSON_Name3』が”CLASS_INF”かつ『JSON_Name7』がNullのものを絞ると属性の名称を取得できます。 ちなみにtab(観測値)は今回使用しません。 実際のコードの中身は、上の【フィルター】ツールのFalse側から取り出します。 『JSON_Name8』に値が入っていればそれが属性データの中身です。 次に【クロスタブ】ツールで横持ちにします。 列ヘッダーになる『JSON_Name8』でデータ名に『@』がついていたものは『_』に変化して出力されます。 @code ⇒ _code@level ⇒ _level@name ⇒ _name@unit ⇒ _unit 次に属性の名称と中身を結合します。 『JSON_Name5』で結合し、リネームしておきます。 _code, _level, _name, _unitは『JSON_Name7』のコードに対応します。 マスタテーブルっぽいものができました。 【結合】ツール後に分岐がありますが、ここは分岐しなくても進められます。 『JSON_Name5』=”1″が cat01 A 人口 ・世帯『JSON_Name5』=”2″が area 地域『JSON_Name5』=”3″が time 調査年 のテーブルです。 cat01 の属性値がコードを含んで長いため【フォーミュラ】で調整しています。 あとは数値と属性のデータテーブルにマスタをぶつけて、適当にリネームしたら終了です。 きれいなテーブルができました! めでたしめでたし。 ・・・となるはずだったんですが、最初にお伝えした通り、データ件数の制限に引っかかり、10万件しか取得できていません。 ということで、残るはループ処理ですね・・・。 4.ループ処理 今回リクエストしたデータは結果的に全部で50万件弱あります。APIの仕様上、一度に取得可能なデータ件数は10万件です。ワークフローを5つ作って、取得結果を別のワークフローで積み上げる、みたいなこともできます。(というか最初はそうしていました。) ただ、データ件数によってワークフローを追加する必要があるなど、全体が自動化されていません。Alteryxの機能を生かし切れていない上にとにかく不格好です。 ということで、全てのプロセスをリクエストした全データを一回のワークフロー実行で取得するため、データ抽出から加工処理のプロセスをループさせます。Alteryxの反復マクロ(Iteration Macro)を使います。 参考資料です。 DevelopersIO・反復マクロを作成しよう! – 今日からはじめるAlteryx再入門アドベントカレンダー・AlteryxのIterativeマクロ(反復マクロ)を使って、ぐるなびAPIから奈良県中西部の飲食店情報を取得してみた KCME Tech Blog・【Alteryx Tips】Alteryxのマクロの作り方【マクロ概要説明編】 通常のデータ加工処理はもう作ってある訳ですが、特定の条件によって反復させるための処理を追加する必要があります。 赤枠の処理が該当します。 一番右の【閲覧】ツール(※【マクロ出力】に後ほど変更)にデータが流れてくればループ、流れてこなければ終了、というのが反復マクロの流れです。 ループ時はデータ加工で作成した右下の右端の【閲覧】ツール(※これも【マクロ出力】に後ほど変更)のアウトプットに自動的にユニオンされていきます。 それでは反復条件を作っていきます。 何件処理されたか、といった情報は、『RESULT_INF』という名前でAPIから返ってきます。JSONの最初の方に含まれます。 ここでは【サンプリング】ツールでデータを絞り、【セレクト】ツールで今回必要な『JSON_ValueString』『JSON_Name3』『JSON_Name4』に絞ります。 『JSON_Name3』に『RESULT_INF』が含まれるので【フィルター】ツールで絞り、【クロスタブ】ツールで横持ちに変更します。 ここに『NEXT_KEY』というものが存在していますが、このカラムが存在することが全部取得できていない証です。次は100001番目のレコードから取得してくださいね、ってことです。 『NEXT_KEY』が存在していたら反復させるようなフローを作っていきます。 当初は『NEXT_KEY』のあるなしで分岐するようなフローを組んでマクロ化しましたが、その場合はループの最終回に『NEXT_KEY』が存在しないためマクロ内部でエラーが出てしまいまいした。 そのため毎回必ず存在する『TO_NUMBER』と『TOTAL_NUMBER』を使います。 【セレクト】でINT型に変更し、【テキスト入力】のデータと【フィールド追加】で結合します。 『TO_NUMBER』が『TOTAL_NUMBER』より小さい場合は、全てのデータを取り切れていません。その時に『startPosition』を更新して反復するフローにします。 最初の【フィルター】で『TO_NUMBER』と『TOTAL_NUMBER』を比較します。T(True)にデータが流れれば反復、F(False)なら終了です。 テキスト入力時の『startPosition』が1ということもあり自動でByte型になっているので【セレクト】でINT型に変更します。 【フォーミュラ】で『startPosition』を『TO_NUMBER』の次(+1)に置き換えます。 反復させる場合にはもう少し処理が必要です。反復マクロの場合、このワークフローの入力と全く同じカラム構成で反復用の出力を返す必要があります。 【セレクト】で不要なカラムを削除し、最初の【テキスト入力】と同じカラム構成にすればOKです。 最後はマクロ化です。 必要な入力系ツール、出力系ツールをマクロ用に変換します。 入力名は反復マクロの設定で選択肢に出てきます。 反復マクロの場合、マクロ出力は二つあります。 まず右上の【閲覧】ツールです。これは反復時に入力値をアップデートして戻すための出力です。この出力名もマクロの設定で使います。 もう一つはAPI出力値をテーブル化した最後の【閲覧】ツールです。こちらの出力名も後で使います。 マクロの設定は、ツールを何も選択していない状況での設定画面から『ワークフロー』タブで『反復マクロ』を選びます。 また、インターフェースデザイナーのプロパティで反復入力と反復出力の設定をします。反復入力にはマクロ入力の入力名を、反復出力にはループ処理のためのマクロ出力の出力名を選択します。間違えやすいので注意しましょう。 インターフェースデザイナーが見当たらない場合は、ツールバーから『表示』でインターフェースデザイナーにチェックを入れると出てくるはずです。 次にマクロとして保存します。 【マクロ入力】ツールや【マクロ出力】ツールを使ったワークフローは自動的にyxmcファイルになります。 頻繁に使用するマクロは保存場所を予め定めて集約すると便利です。 ユーザー設定でマクロの保存場所を登録することでいつでもすぐ呼び出せるようになります。 実際にマクロを使って回してみます。 最初に使用していた【テキスト入力】ツールに作ったマクロを繋げるだけです。 青いツールに汗と涙が詰め込まれています。 いい感じに取得できてますね。 マクロが5回回って49万4064レコードを取得しています。 APIからのダウンロードを含めてわずか50秒で約50万件のデータ取得とJSONのデータプレップが自動的に処理されました。 完成! おわりに もっと簡単に作れるかと思っていましたが事前の見積りが甘かったです・・・ 本当は誰でも簡単ですね、みたいな締め方をしたかったところですが、普段からこういったAPIを叩くことに慣れていないと、手戻りなしにホイホイ作るのは無理だと思います。 データプレップの大変さをあらためて感じる結果となりました。 e-stat APIからAlteryxでデータを取得すること自体はこのブログの内容を参考にすれば誰でもできると思います。 ただ、なかなかレベルの高い実装が必要になるのと、業務での運用持続性を鑑みた時に、普段からAPIを触っていない上に、年に数回取得するかどうかのデータのために自前で作るべきか、というと率直にあまりオススメできません・・・。 技術力が高いメンバーが揃っている、そのAPIを頻繁に使う、などといった環境があるなら自前でも良いと思います。 一方、来年自分がその担当なのかも不透明だったり、丁寧な詳細説明とセットでないとワークフローの引き継ぎも困難だったりする場合は、特にコスパが悪そうです。費やす時間の割に大して使われないですし、たまに使った時に問題が起こると、記憶を呼び起こし、APIの仕様書を読み直すなどして、問題の解決に時間を取られることになります。 ということで、APIからのデータプレップ(取得や加工)にお悩みの方は、是非こちらからtruestarまでお問い合わせください(笑) それではまた。 関連する記事 Alteryx でジオコーディング API を使って緯度経度や正規化された住所情報を取得する Alteryxで調査データをTableau用データに加工してみた-Part 1 #Alteryx #14 | Alteryx Advent Calendar 2016 Polygon for Tableauを使ってみる #Alteryx #06 | Alteryx Advent Calendar 2016 Alteryxで調査データをTableau用データに加工してみた-Part 2 #Alteryx #16 | Alteryx Advent Calendar 2016 AlteryxAPIMacro t.fuji / About Author More posts by t.fuji ↓すぐに使えるオープンデータが揃っています。 ↓弊社に興味を持った方はこちらから ↓弊社のサポートを受けてみませんか? ↓求人募集・人材募集についてのお知らせです。